Rastgele Ormanlar
Python ile Ağaç Tabanlı Modellerle Machine Learning

Elie Kawerk
Data Scientist
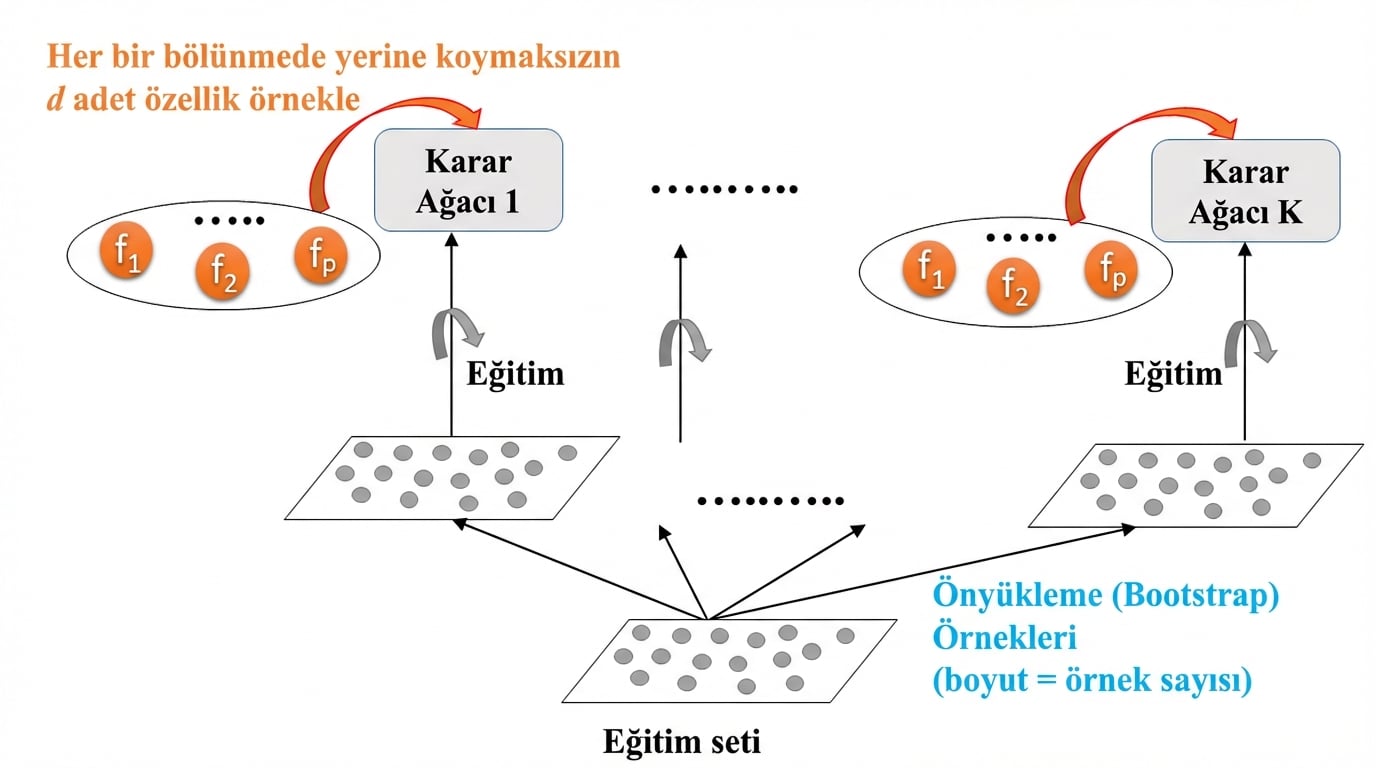
Rastgele Ormanlar: Eğitim
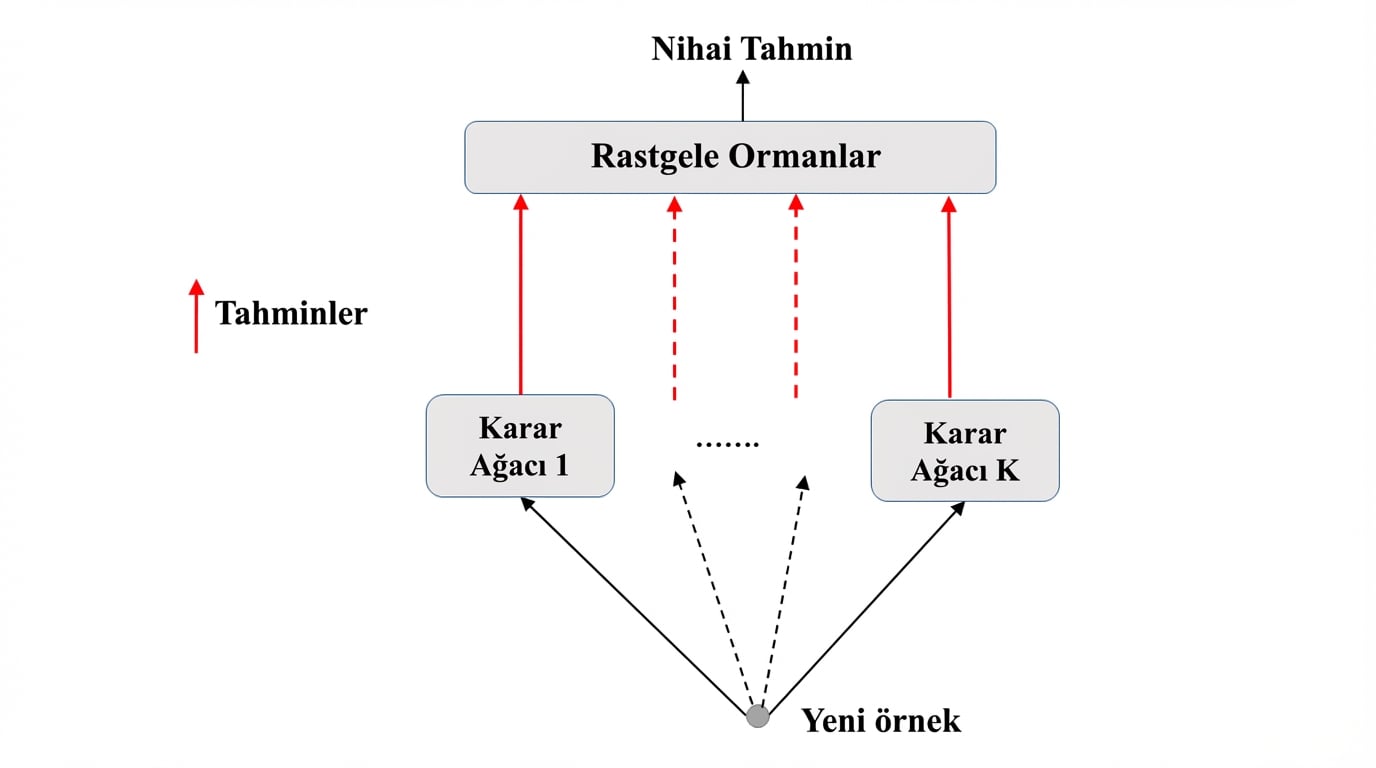
Rastgele Ormanlar: Tahmin
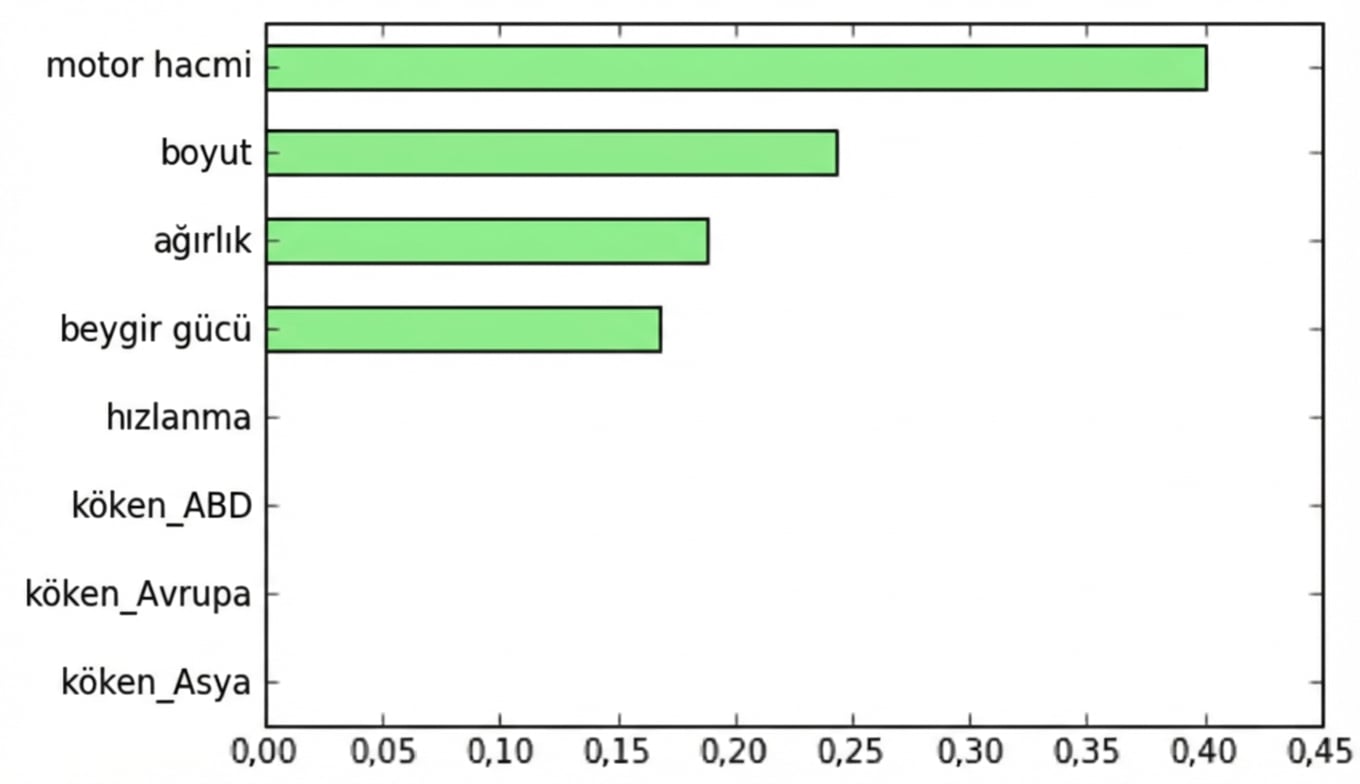
sklearn'de Özellik Önemi
Python ile Ağaç Tabanlı Modellerle Machine Learning
Elie Kawerk
Data Scientist

