Sönen ve taşan gradyanlar
PyTorch ile Orta Düzey Deep Learning

Michal Oleszak
Machine Learning Engineer
Sönen gradyanlar
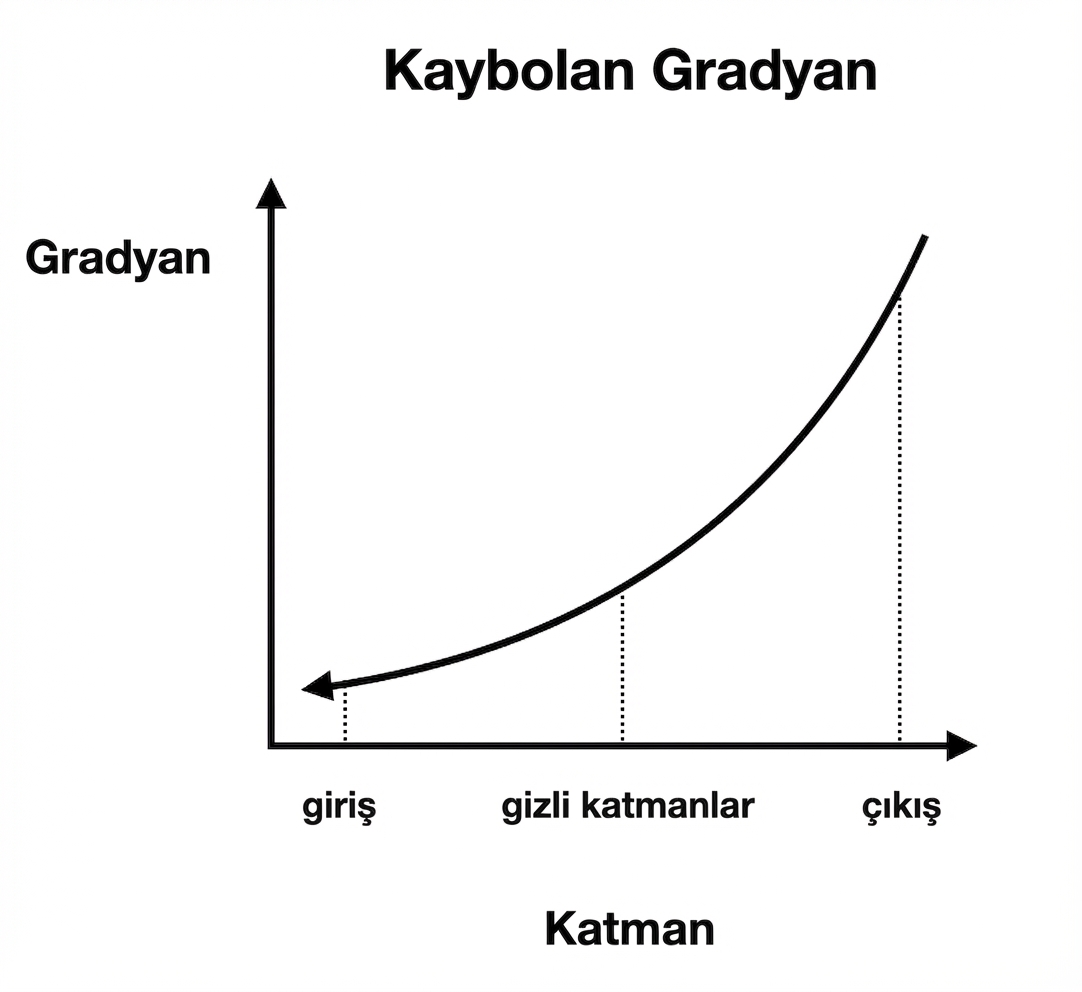
Taşan gradyanlar
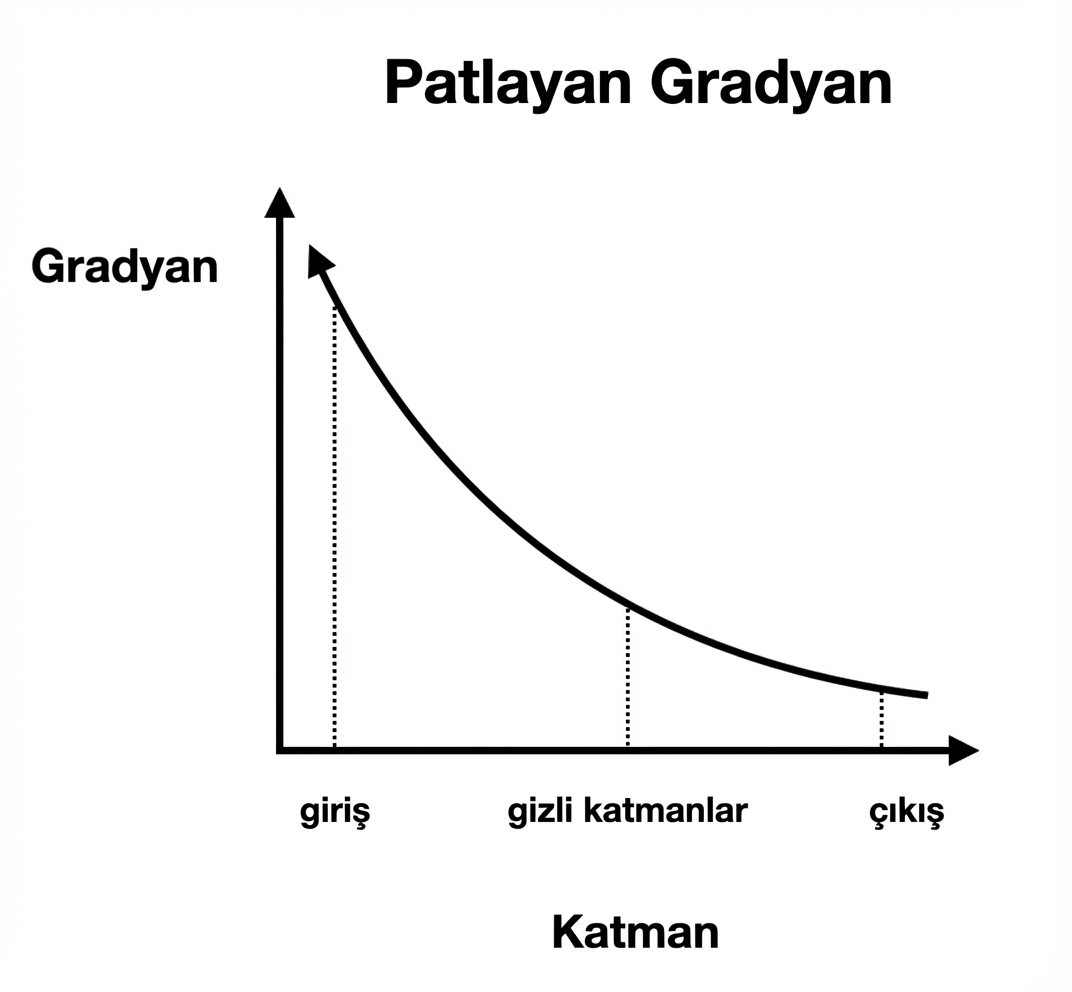
Dengesiz gradyanlara çözüm
- Doğru ağırlık başlatma
- Uygun aktivasyonlar
- Batch normalization

Aktivasyon fonksiyonları
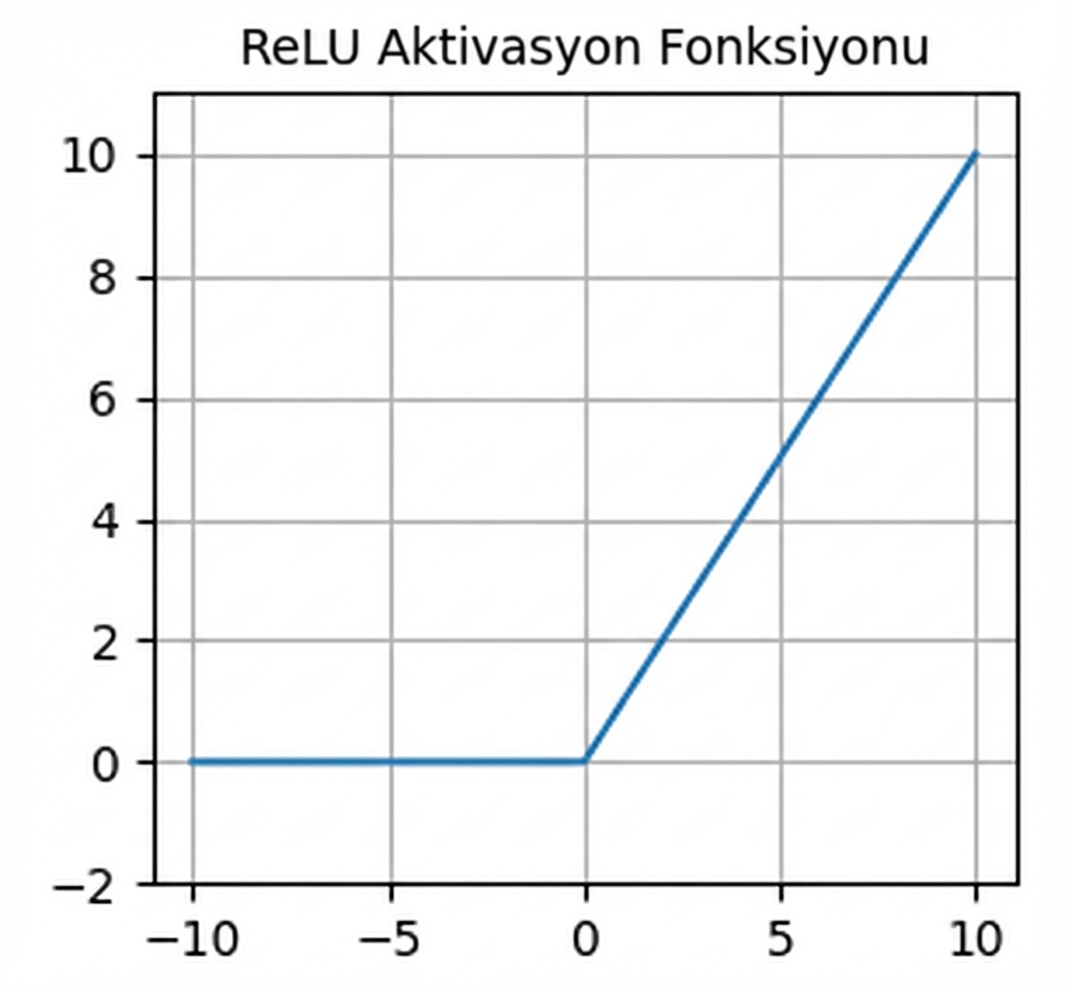
- Sıklıkla varsayılan aktivasyon
nn.functional.relu()- Negatif girdilerde sıfır — ölen nöronlar
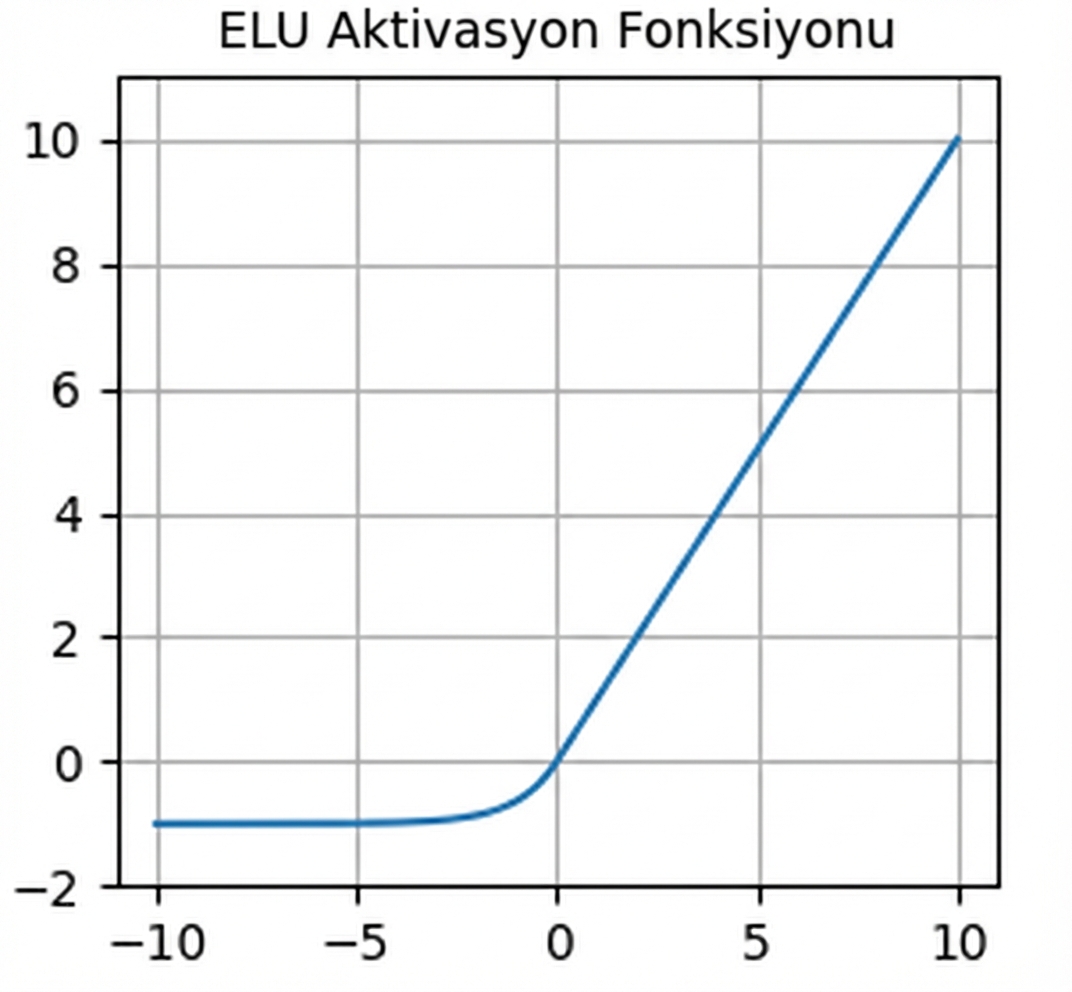
nn.functional.elu()- Negatif değerler için sıfır olmayan gradyanlar — ölen nöronlara karşı yardımcı
- Ortalama çıktı sıfır civarı — sönen gradyanlara karşı yardımcı

