Örnekleme ve bootstrap dağılımlarını karşılaştırma
Python'da Örnekleme

James Chapman
Curriculum Manager, DataCamp
Kahve odaklı alt küme
coffee_sample = coffee_ratings[["variety", "country_of_origin", "flavor"]]\
.reset_index().sample(n=500)
index variety country_of_origin flavor
132 132 Other Costa Rica 7.58
51 51 None United States (Hawaii) 8.17
42 42 Yellow Bourbon Brazil 7.92
569 569 Bourbon Guatemala 7.67
.. ... ... ... ...
643 643 Catuai Costa Rica 7.42
356 356 Caturra Colombia 7.58
494 494 None Indonesia 7.58
169 169 None Brazil 7.81
[500 rows x 4 columns]
Ortalama kahve tatlarının bootstrap'i
import numpy as np
mean_flavors_5000 = []
for i in range(5000):
mean_flavors_5000.append(
np.mean(coffee_sample.sample(frac=1, replace=True)['flavor'])
)
bootstrap_distn = mean_flavors_5000
Ortalama tat bootstrap dağılımı
import matplotlib.pyplot as plt
plt.hist(bootstrap_distn, bins=15)
plt.show()
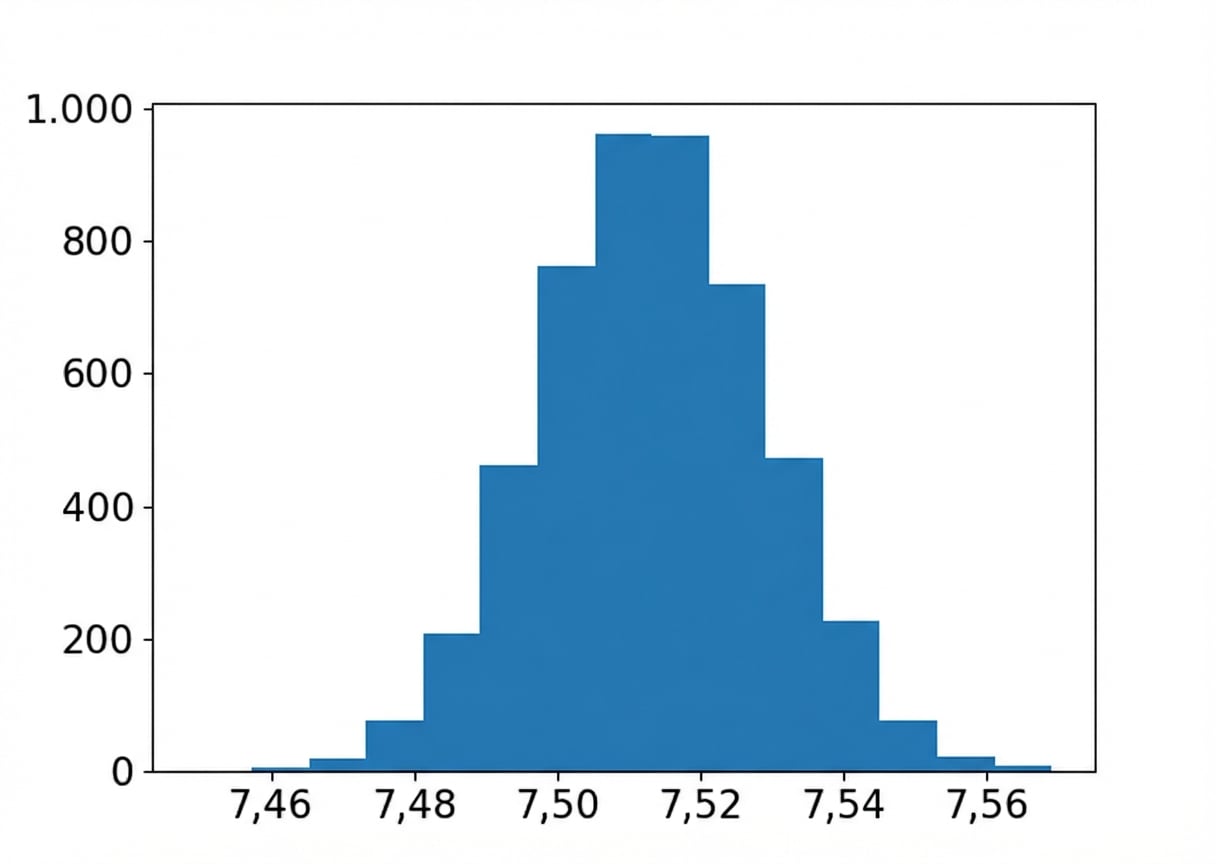
Örnek, bootstrap dağılımı, anakütle ortalamaları
Örnek ortalaması:
coffee_sample['flavor'].mean()
7.5132200000000005
Tahmini anakütle ortalaması:
np.mean(bootstrap_distn)
7.513357731999999
Gerçek anakütle ortalaması:
coffee_ratings['flavor'].mean()
7.526046337817639
Ortalamaları yorumlama
Bootstrap dağılımı ortalaması:
- Genellikle örnek ortalamasına yakındır
- Anakütle ortalamasını iyi tahmin etmeyebilir
Bootstrap, örneklemeden kaynaklı yanlılığı gideremez
Örnek ss vs. bootstrap dağılımı ss
Örnek standart sapması:
coffee_sample['flavor'].std()
0.3540883911928703
Tahmini anakütle standart sapması?
np.std(bootstrap_distn, ddof=1)
0.015768474367958217
Örnek, bootstrap dağılımı, anakütle ss
Örnek standart sapması:
coffee_sample['flavor'].std()
0.3540883911928703
Tahmini anakütle standart sapması:
standard_error = np.std(bootstrap_distn, ddof=1)
Standart hata, ilgi duyulan istatistiğin standart sapmasıdır
Gerçek standart sapma:
coffee_ratings['flavor'].std(ddof=0)
0.34125481224622645
standard_error * np.sqrt(500)
0.3525938058821761
Standart hata × örneklem büyüklüğünün karekökü, anakütle standart sapmasını tahmin eder
Standart hataları yorumlama
- Tahmini standart hata → örnek istatistiği için bootstrap dağılımının standart sapması
- $\text{Anakütle ss} \approx \text{Std. hata} \times \sqrt{\text{Örneklem büyüklüğü}}$
Hadi pratik yapalım!
Python'da Örnekleme

