Hipotez testleri ve z-skorları
Python'da Hipotez Testi

James Chapman
Curriculum Manager, DataCamp
A/B testi

1 Görsel kredisi: "Electronic Arts" majaX1 CC BY-NC-SA 2.0
Perakende web sayfası A/B testi
Kontrol:

Tedavi:
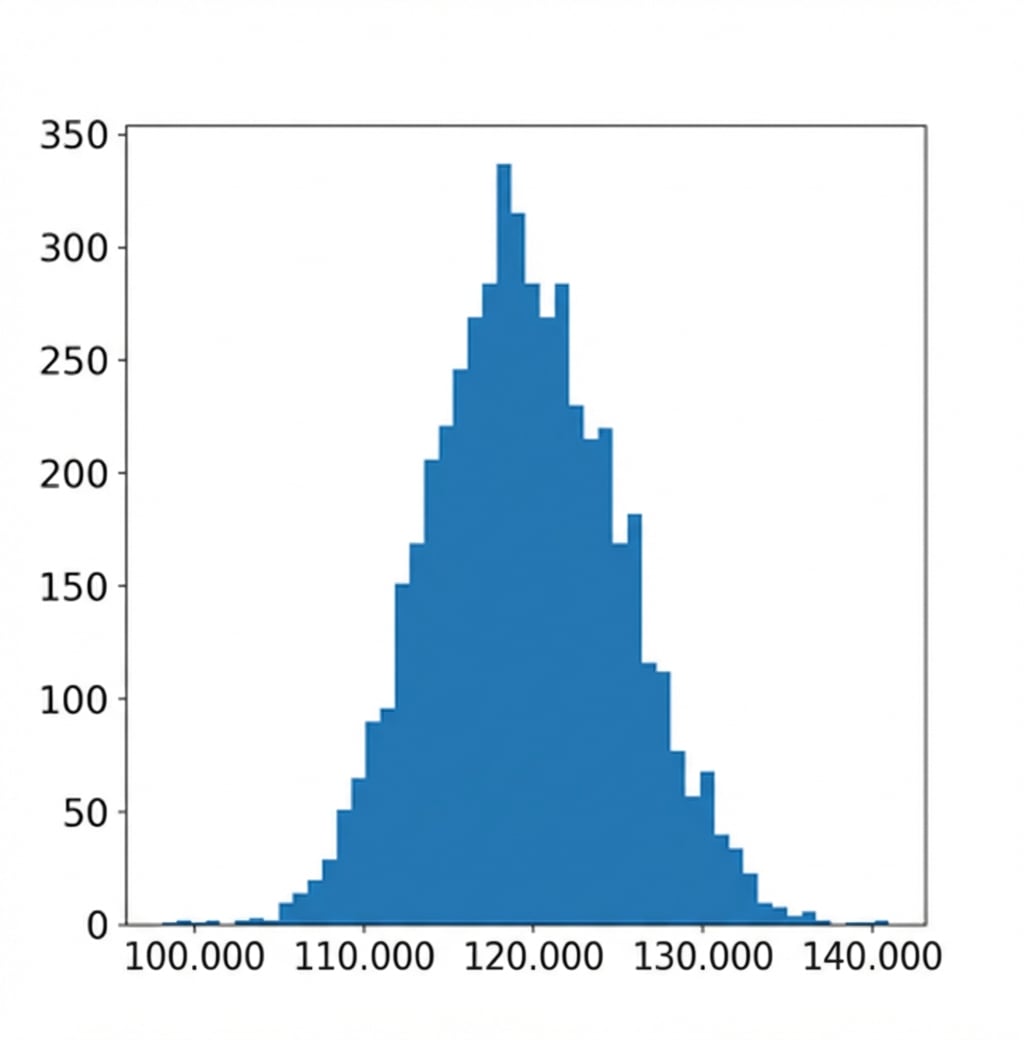
Bootstrap dağılımını görselleştirme
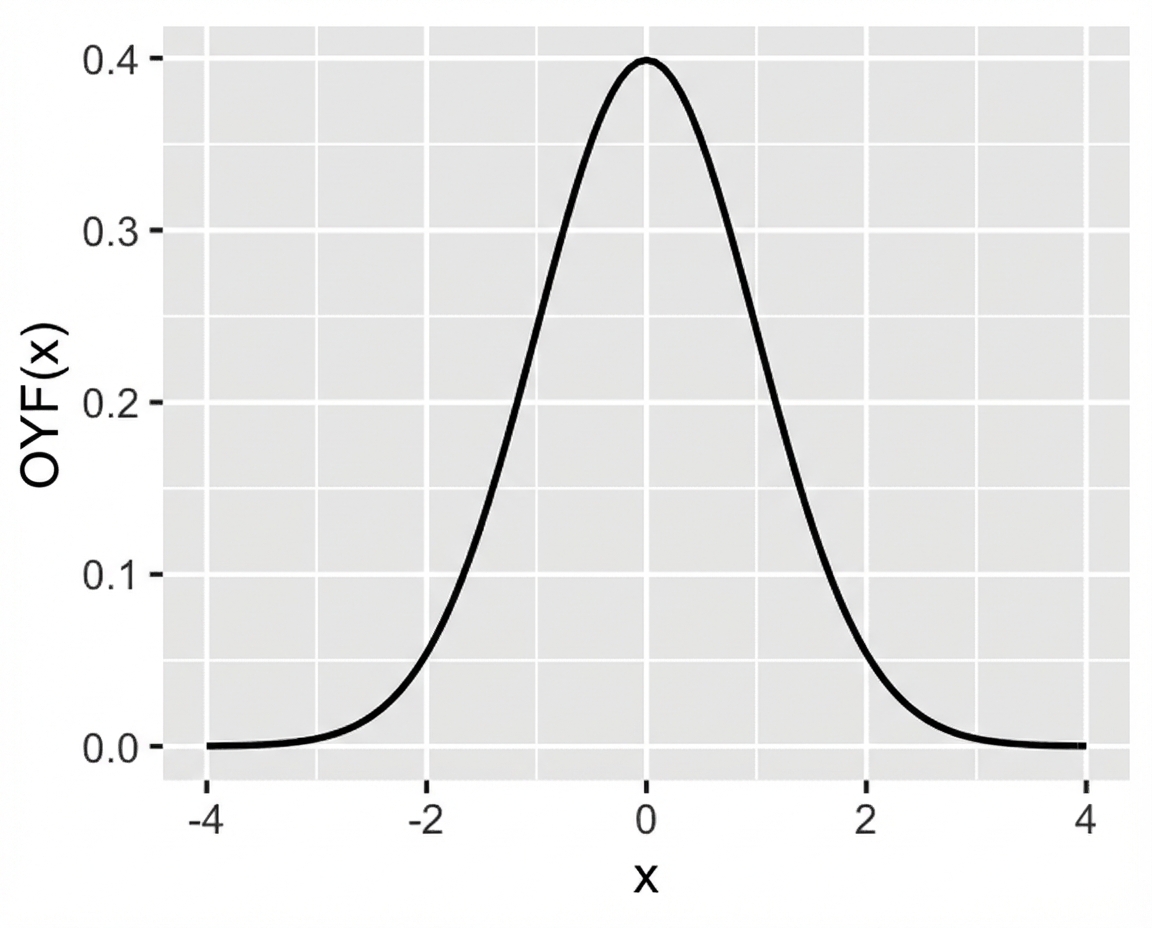
Standart normal (z) dağılımı
Standart normal dağılım: ortalama = 0 ve standart sapma = 1 olan normal dağılım