Gelişmiş bölme yöntemleri
LangChain ile Retrieval Augmented Generation (RAG)

Meri Nova
Machine Learning Engineer
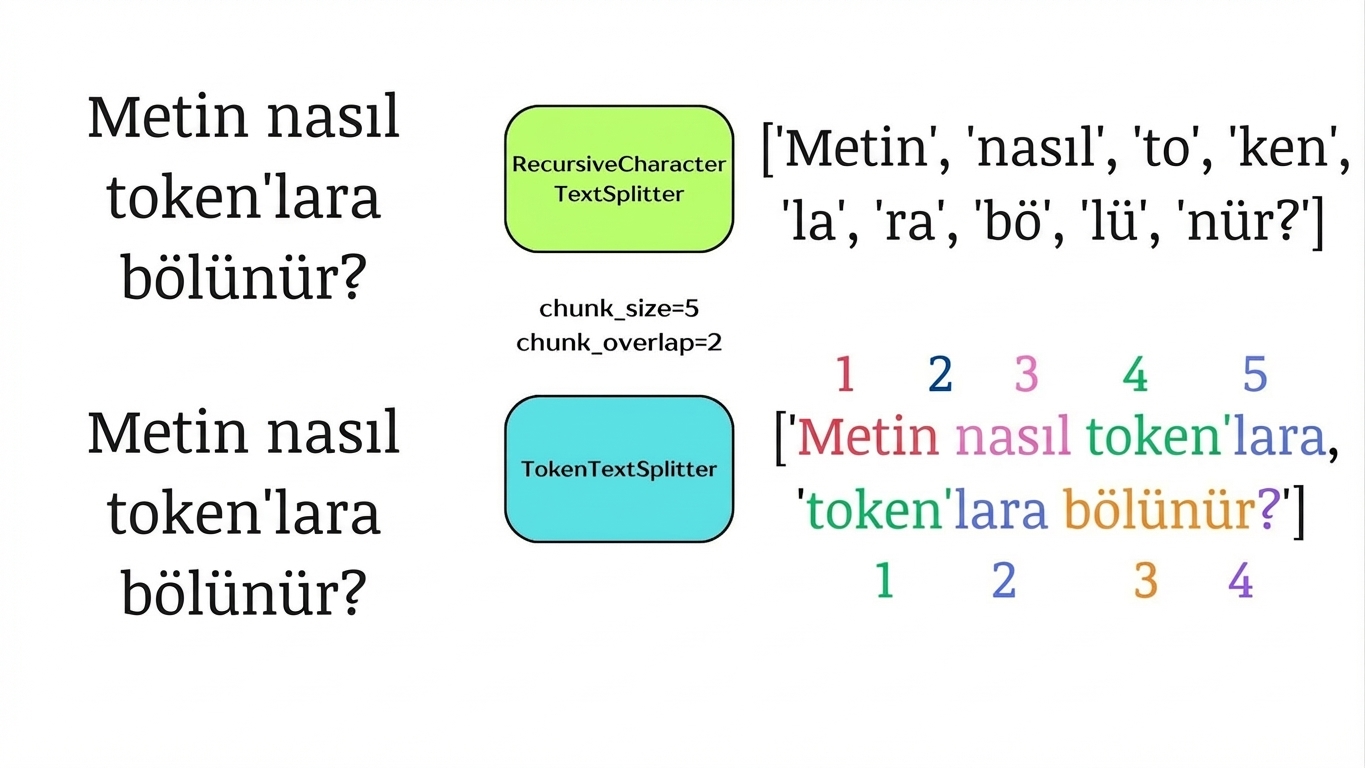
Tokenlara göre bölme

Tokenlara göre bölme
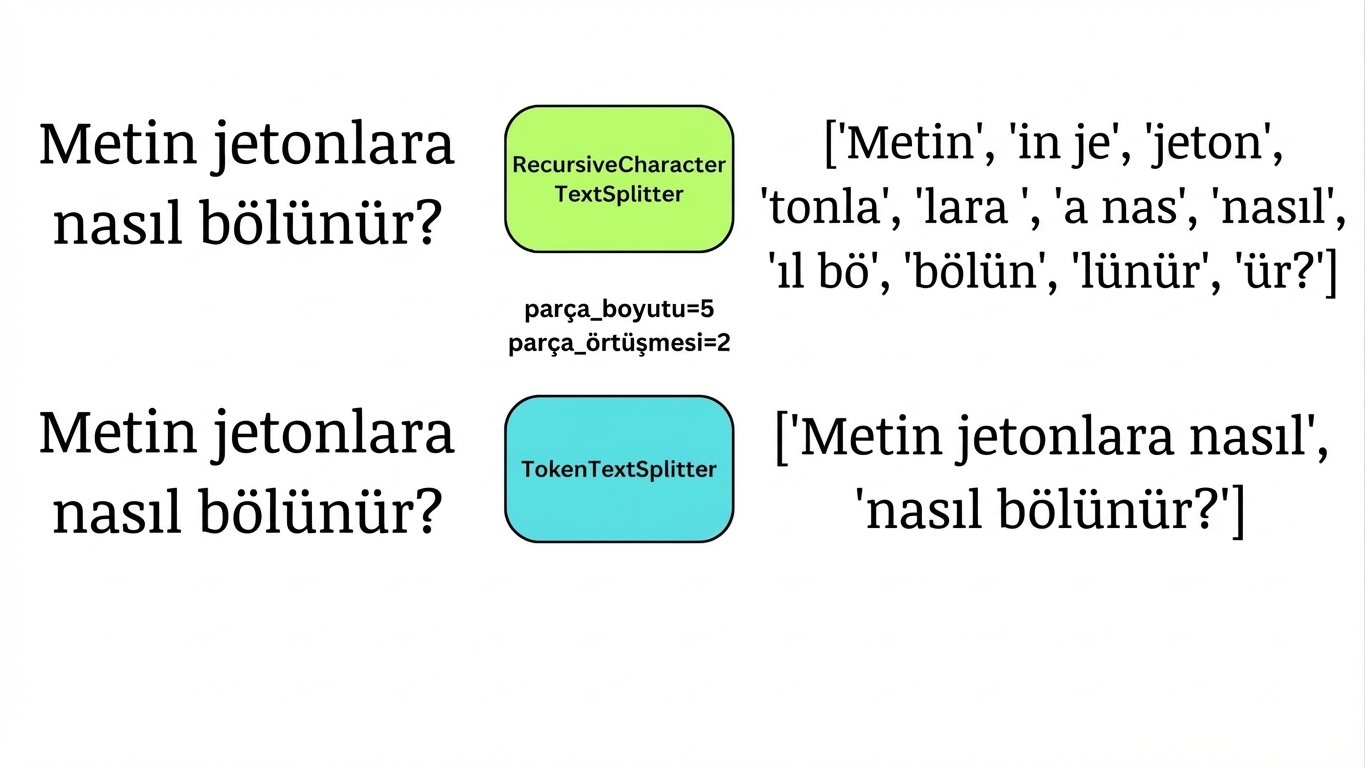
Tokenlara göre bölme
Anlamsal bölme

Anlamsal bölme

Anlamsal bölme

LangChain ile Retrieval Augmented Generation (RAG)
Meri Nova
Machine Learning Engineer

