Model değerlendirme ve görselleştirme
Uçtan Uca Machine Learning

Joshua Stapleton
Machine Learning Engineer
Doğruluk
- Doğru doğruluk metrikleri, sağlam model değerlendirmesi için kritiktir
- Sonuçlar kolayca yanlış yorumlanabilir veya gizlenebilir
Standart doğruluk:
- Standart doğruluk = doğru yanıt sayısı / toplam yanıt
- Standart doğruluk yanıltıcı olabilir
Örnek:
# 99 pozitif ve 1 negatiften oluşan dengesiz veri kümesinde ~%99 doğruluk elde eder
for patient_datapoint in heart_disease_dataset:
model.prediction(patient_datapoint) = 'positive'
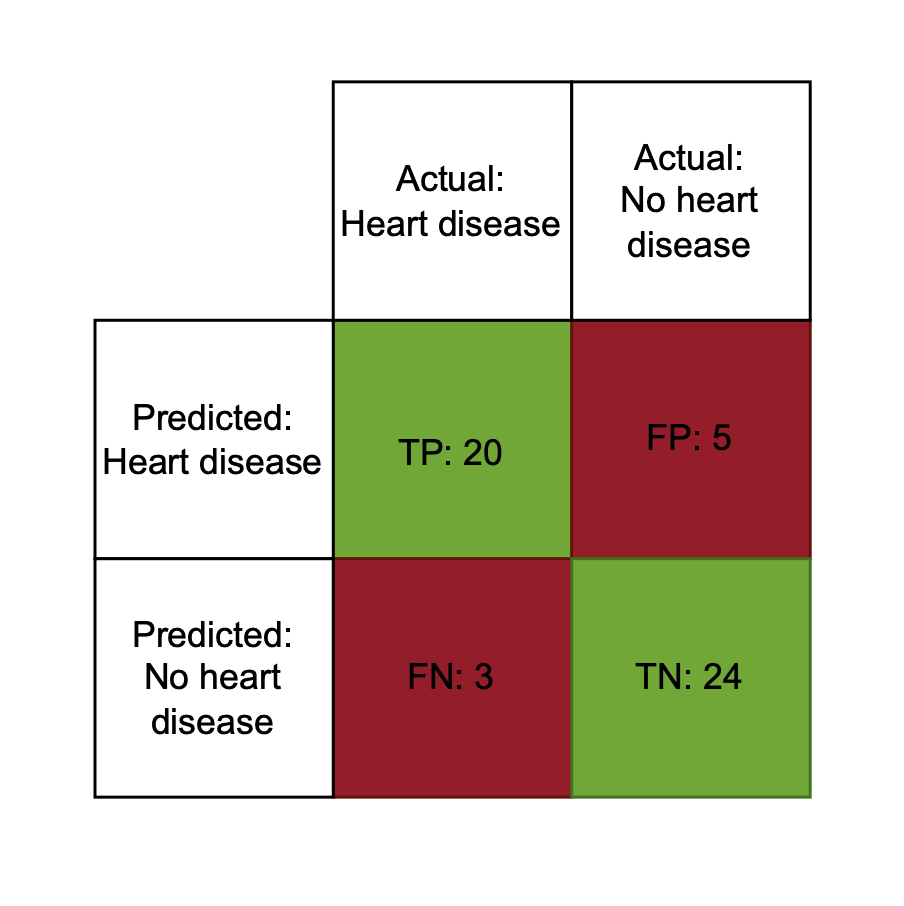
Karmaşıklık matrisi
Doğru pozitifler (TP)
- Model tahmini = gerçek sınıf = pozitif
- Model kalp hastalığı tahmin etti, hastada kalp hastalığı vardı
Yanlış pozitifler (FP)
- Model tahmini = pozitif, gerçek sınıf = negatif
- Model kalp hastalığı tahmin etti, hastada kalp hastalığı yoktu
Yanlış negatifler (FN)
- Model tahmini = negatif, gerçek sınıf = pozitif
- Model kalp hastalığı yok dedi, hastada kalp hastalığı vardı
Doğru negatifler (TN)
- Model tahmini = gerçek sınıf = negatif
- Model kalp hastalığı yok dedi, hastada kalp hastalığı yoktu
Dengelemeli doğruluk
- Çoğu ikili sınıflandırma için düz doğruluktan daha iyi metriktir
- Her iki sınıf için ağırlıklı ortalama sağlar
- Dengelemeli doğruluk = (TP + TN) / 2
from sklearn.metrics import balanced_accuracy_score
# y_test gerçek etiketler, y_pred tahminlerdir
y_pred = model.predict(X_test)
bal_accuracy = balanced_accuracy_score(y_test, y_pred)
print(f"Balanced Accuracy: {bal_accuracy:.2f}")
Balanced Accuracy: 0.85
Karmaşıklık matrisi kullanımı
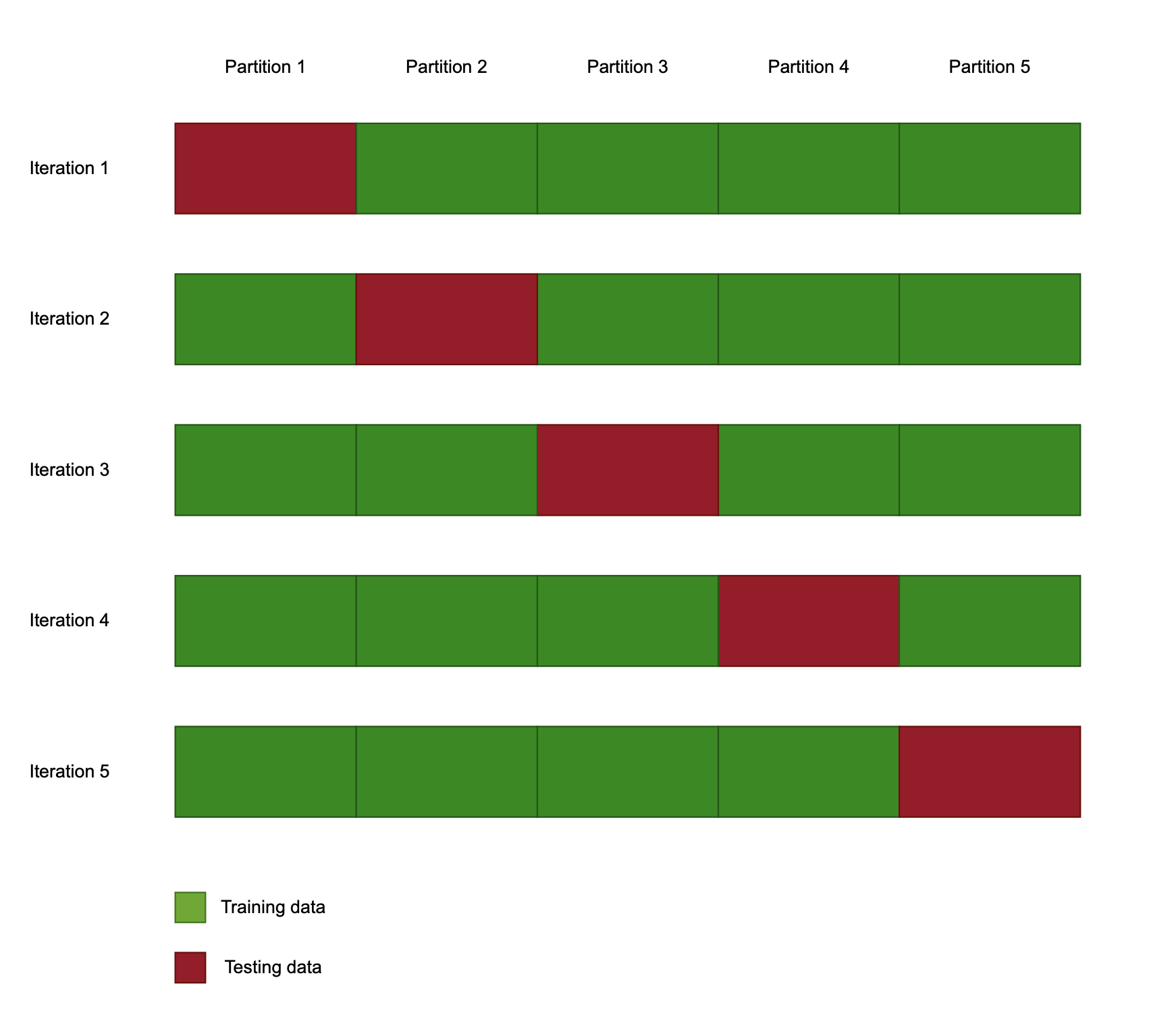
Çapraz doğrulama
Çapraz doğrulama
- Yeniden örnekleme yöntemi
- Sonuçların sağlamlığını artırır
k-katlı çapraz doğrulama
- 'k' parametresi = veri kümesi bölünme sayısı
- Her modelleme çalışmasında yeni eğitim/test bölmesi
Çapraz doğrulama kullanımı
- sklearn ile k-katlı çapraz doğrulamanın kolay uygulanması
- Modele bağımsız puanlama
Kullanım:
from sklearn.model_selection import cross_val_score, KFold # veriyi 5 eşit parçaya böl kfold = KFold(n_splits=5, shuffle=True, random_state=42)# bir model için çapraz doğrulama doğruluğunu al cv_results = cross_val_score(model, heart_disease_X, heart_disease_y, cv=kfold, scoring='balanced_accuracy')
Hiperparametre ayarı
Hiperparametre:
- Küresel model parametresi (eğitim sırasında değişmez)
- Model performansını iyileştirmek için ayarlanır
# Test edilecek hiperparametreler
C_values = [0.001, 0.01, 0.1, 1, 10, 100, 1000]
# Hiperparametreleri elle yinele
for C in C_values:
model = LogisticRegression(max_iter=200, C=C)
model.fit(X_train, y_train)
accuracy = cross_val_score(model, X, y, cv=kfold, scoring='balanced_accuracy')
print(f"C = {C}: Bal Acc: {accuracy.mean():.4f} (+/- {accuracy.std():.4f})")
Hiperparametre ayarı örneği
Hiperparametre ayarı için örnek çıktı:
C = 0.001: Bal Acc: 0.6200 (+/- 0.0215)
C = 0.01: Bal Acc: 0.7325 (+/- 0.0234)
C = 0.1: Bal Acc: 0.7923 (+/- 0.0202)
C = 1: Bal Acc: 0.8050 (+/- 0.0191)
C = 10: Bal Acc: 0.8034 (+/- 0.0185)
C = 100: Bal Acc: 0.8021 (+/- 0.0187)
C = 1000: Bal Acc: 0.8017 (+/- 0.0188)
Hadi pratik yapalım!
Uçtan Uca Machine Learning

