PySpark RDD’ye Giriş
PySpark ile Big Data Temelleri

Upendra Devisetty
Science Analyst, CyVerse
RDD nedir?
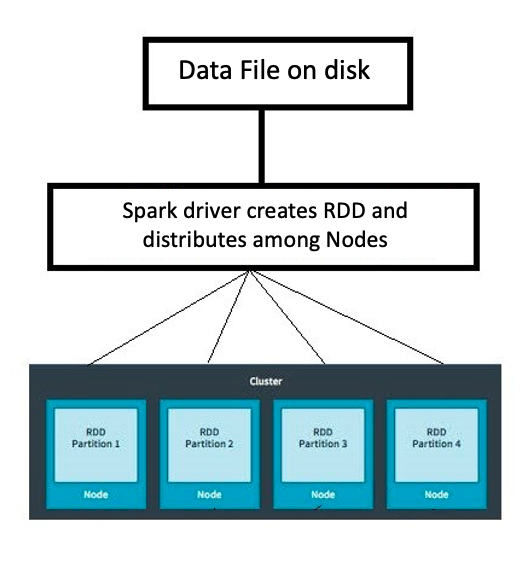
- RDD = Resilient Distributed Datasets (Dayanıklı Dağıtık Veri Kümeleri)
PySpark ile Big Data Temelleri
Upendra Devisetty
Science Analyst, CyVerse

