PySpark'ta RDD işlemleri
PySpark ile Big Data Temelleri

Upendra Devisetty
Science Analyst, CyVerse
PySpark işlemlerine genel bakış

- Transformations yeni RDD'ler oluşturur
- Actions RDD'ler üzerinde hesaplama yapar
RDD Dönüşümleri
- Dönüşümler Lazy evaluation ile çalışır

Temel RDD Dönüşümleri
map(),filter(),flatMap()veunion()
map() Dönüşümü
- map() dönüşümü RDD'deki tüm öğelere bir işlev uygular
![]()
RDD = sc.parallelize([1,2,3,4])
RDD_map = RDD.map(lambda x: x * x)
filter() Dönüşümü
- filter dönüşümü, koşulu geçen öğelerle yeni bir RDD döndürür

RDD = sc.parallelize([1,2,3,4])
RDD_filter = RDD.filter(lambda x: x > 2)
flatMap() Dönüşümü
- flatMap() dönüşümü, her öğe için birden çok değer döndürür
![]()
RDD = sc.parallelize(["hello world", "how are you"])
RDD_flatmap = RDD.flatMap(lambda x: x.split(" "))
union() Dönüşümü
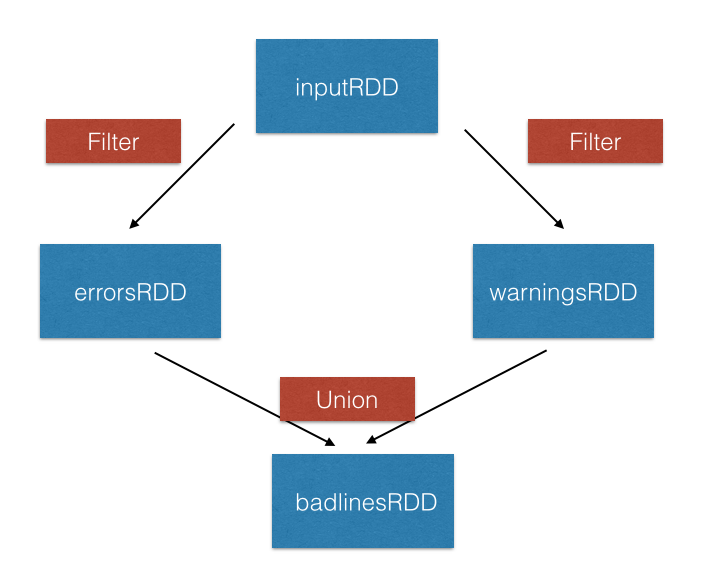
inputRDD = sc.textFile("logs.txt")
errorRDD = inputRDD.filter(lambda x: "error" in x.split())
warningsRDD = inputRDD.filter(lambda x: "warnings" in x.split())
combinedRDD = errorRDD.union(warningsRDD)

