Paralel hesaplama çerçeveleri
Data Engineering'e Giriş

Vincent Vankrunkelsven
Data Engineer @ DataCamp
![]()
HDFS
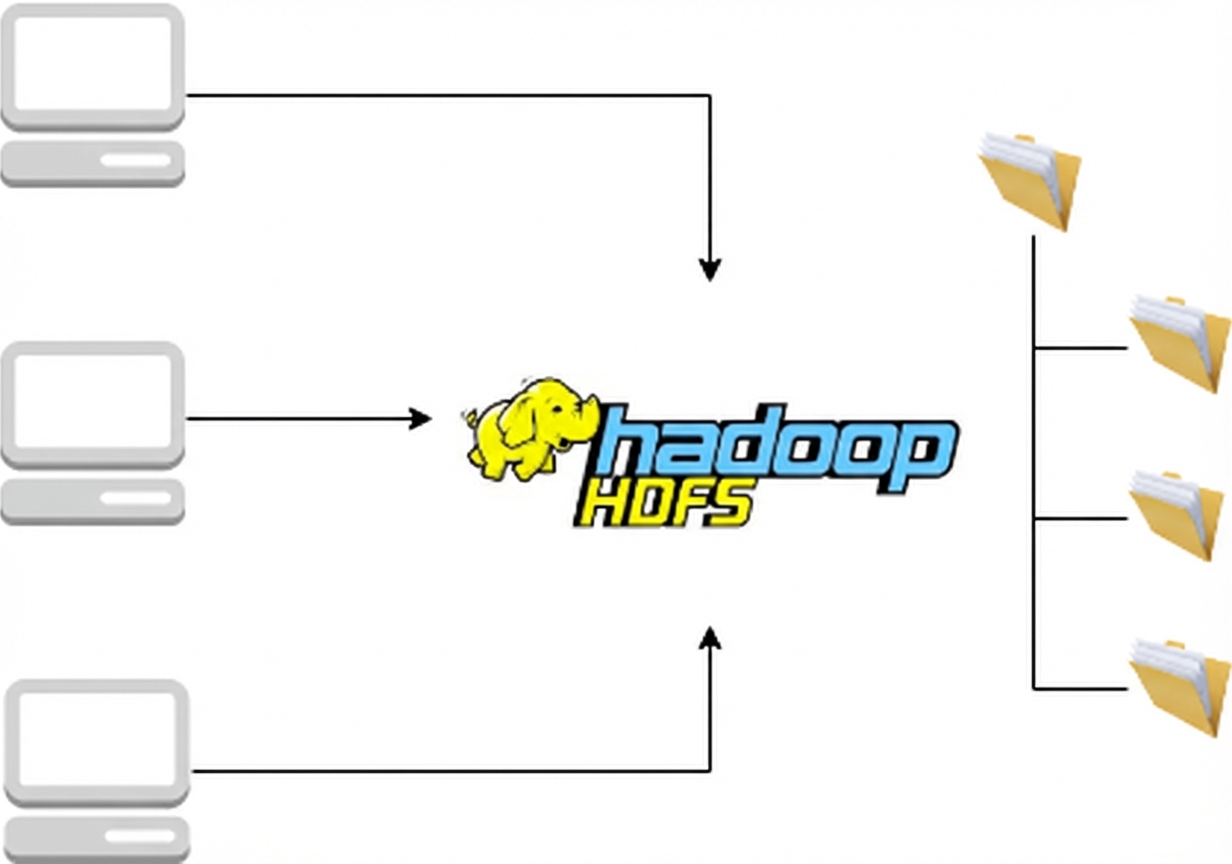
MapReduce
![]()

Hive
- Hadoop üzerinde çalışır
- Yapılandırılmış Sorgu Dili: Hive SQL
- Başta MapReduce, şimdi diğer araçlar da
![]()
Hive: bir örnek
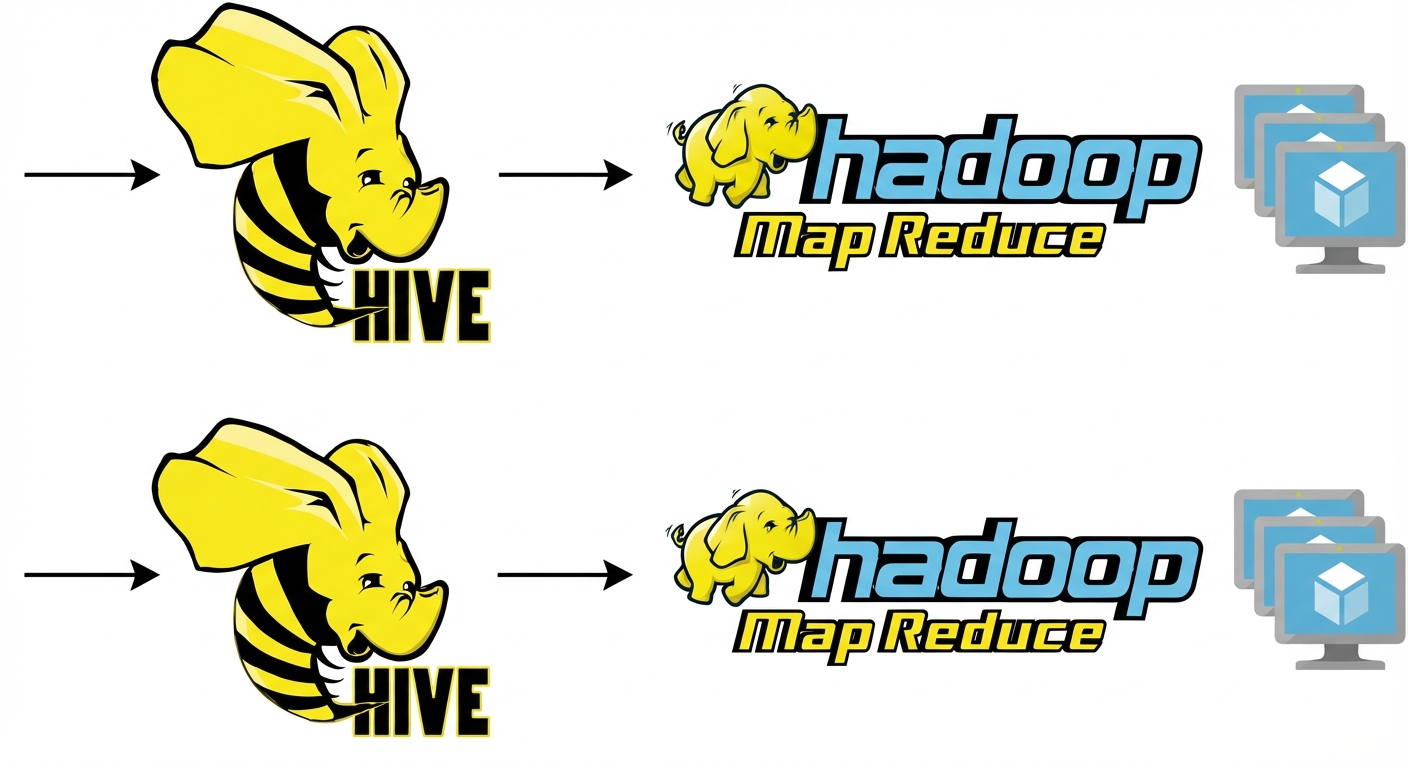
![]()
- Disk yazımlarından kaçınır
- Apache Software Foundation tarafından geliştirilir

