Monte Carlo yöntemleri
Python ile Gymnasium'da Reinforcement Learning

Fouad Trad
Machine Learning Engineer
Tekrar: modele dayalı öğrenme
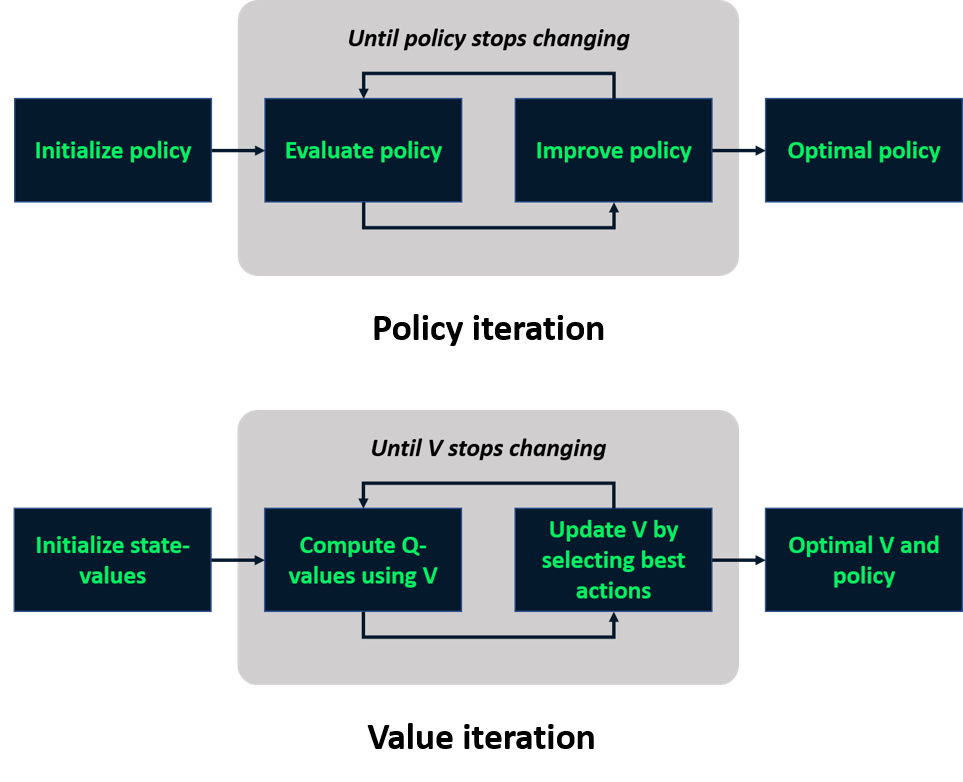
Modelden bağımsız öğrenme

Monte Carlo yöntemleri
- Modelden bağımsız teknikler
- Q-değerlerini bölümlerden tahmin eder
Monte Carlo yöntemleri
- Modelden bağımsız teknikler
- Q-değerlerini bölümlerden tahmin eder

Monte Carlo yöntemleri
- Modelden bağımsız teknikler
- Q-değerlerini bölümlerden tahmin eder

- İki yöntem: ilk-ziyaret, her-ziyaret
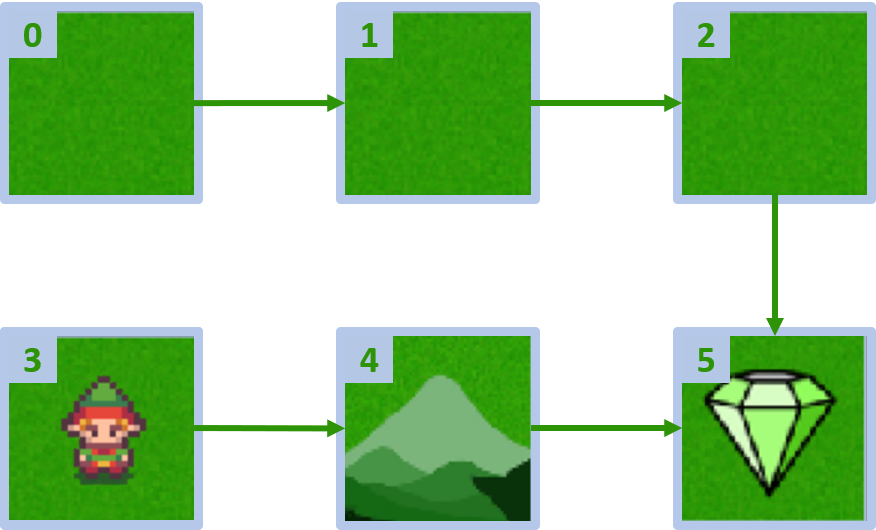
Özel ızgara dünya
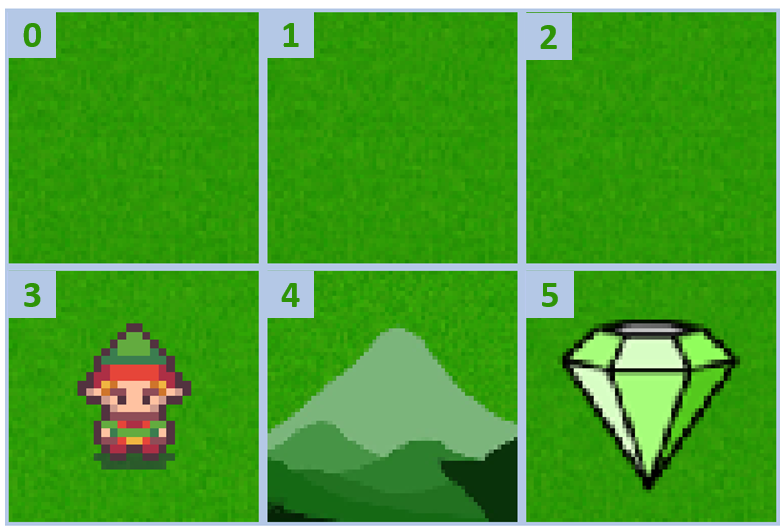
İki bölüm toplama
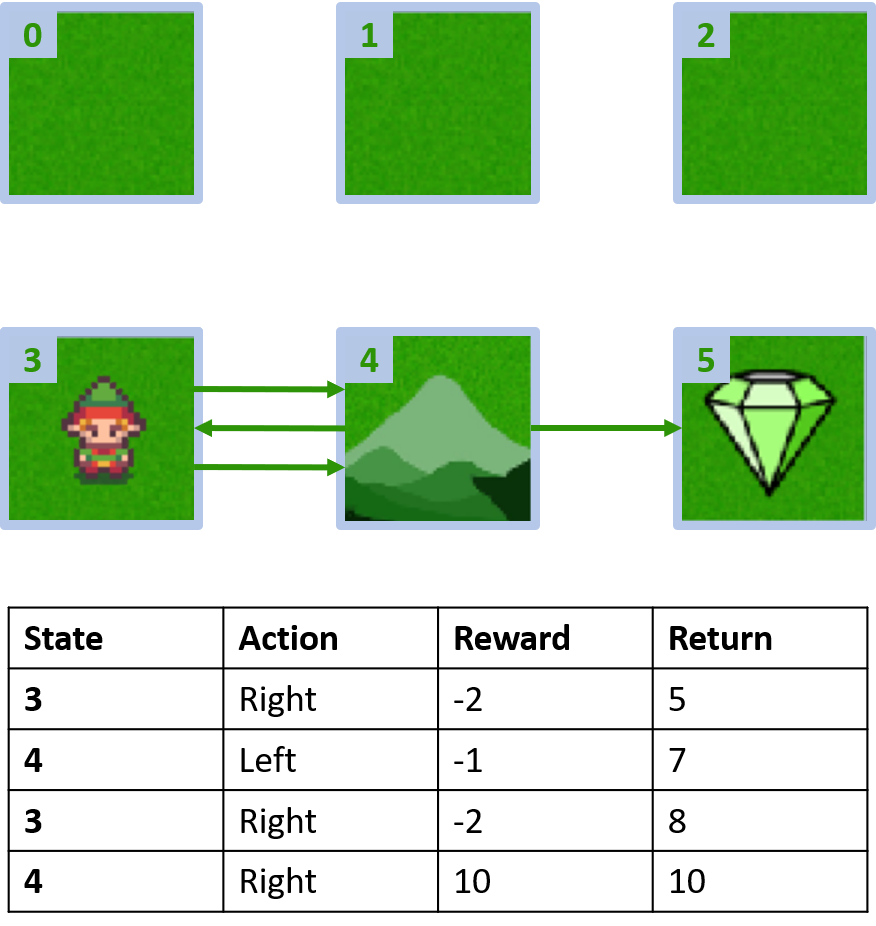
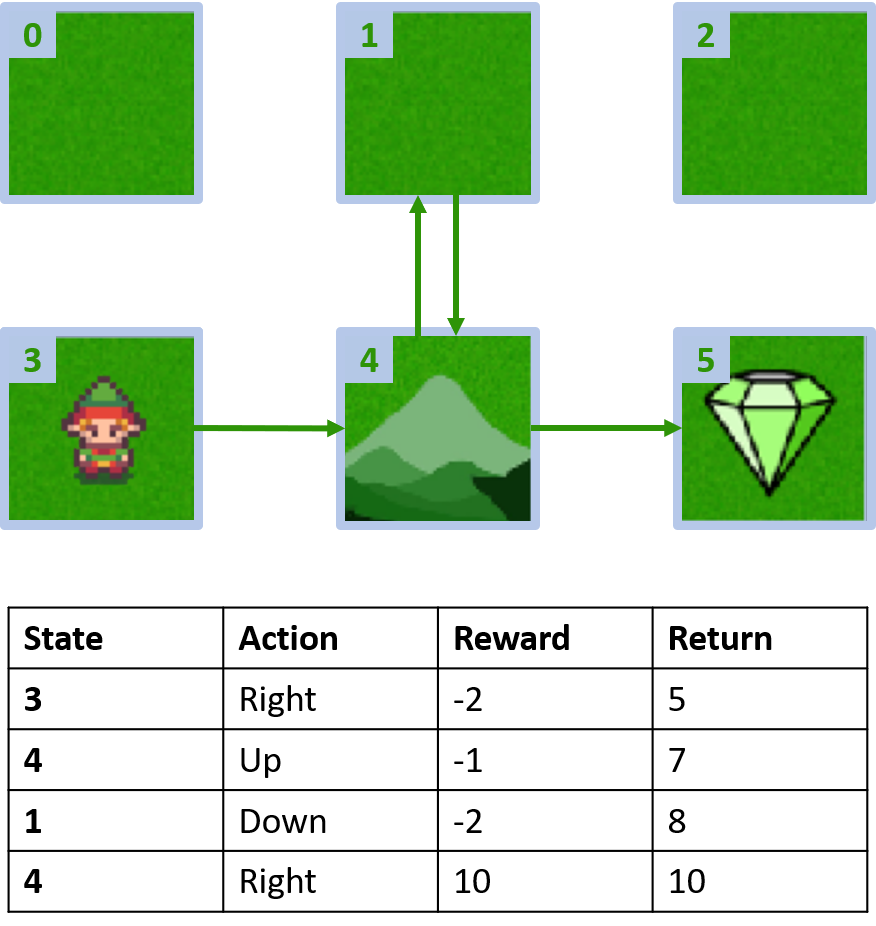
Q-değerlerini tahmin etme
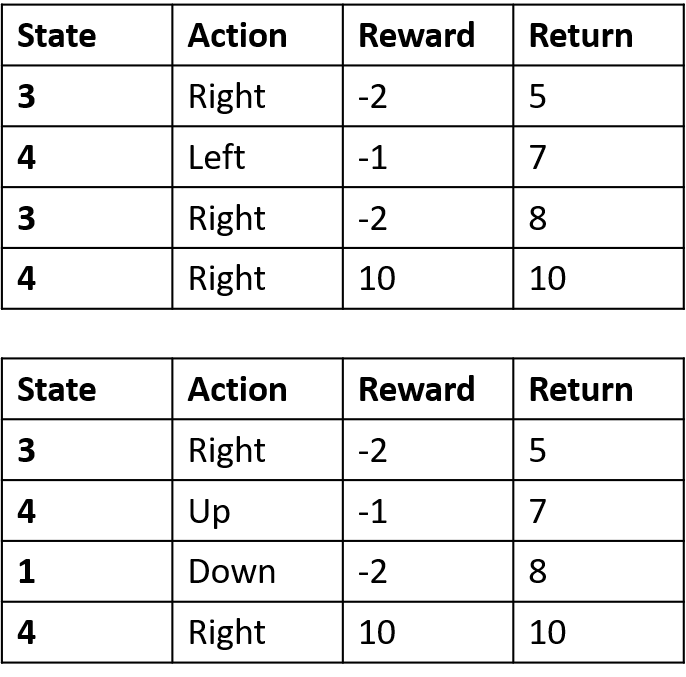
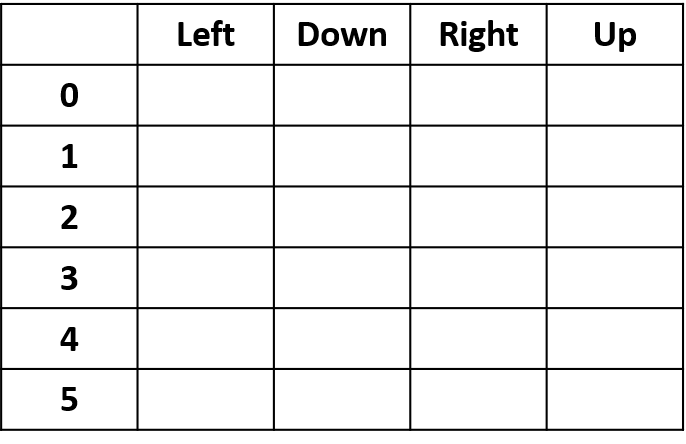
- Q-tablosu: Q-değerleri tablosu
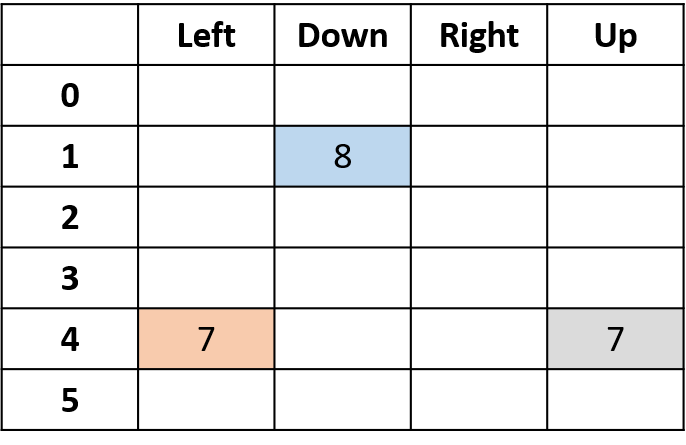
Q(4, sol), Q(4, yukarı) ve Q(1, aşağı)
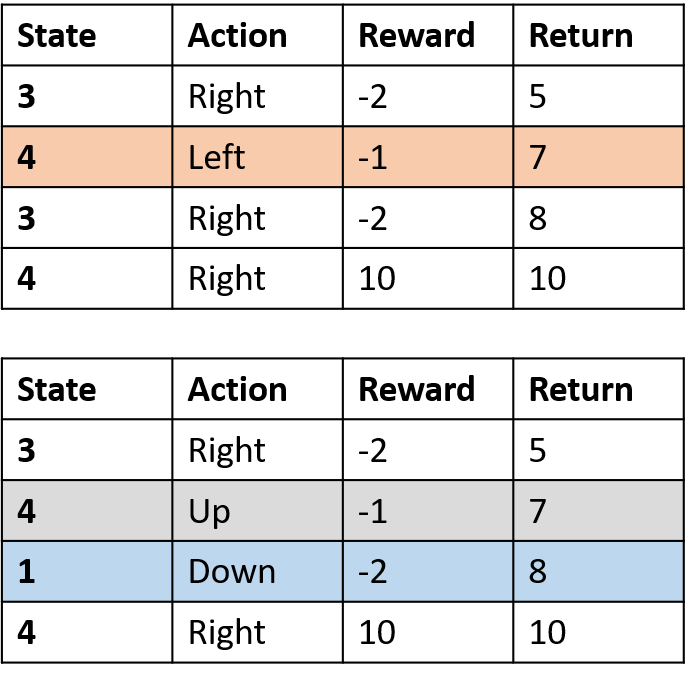
- (s,a) bir kez görünür -> getiriyle doldur
Q(4, sağ)
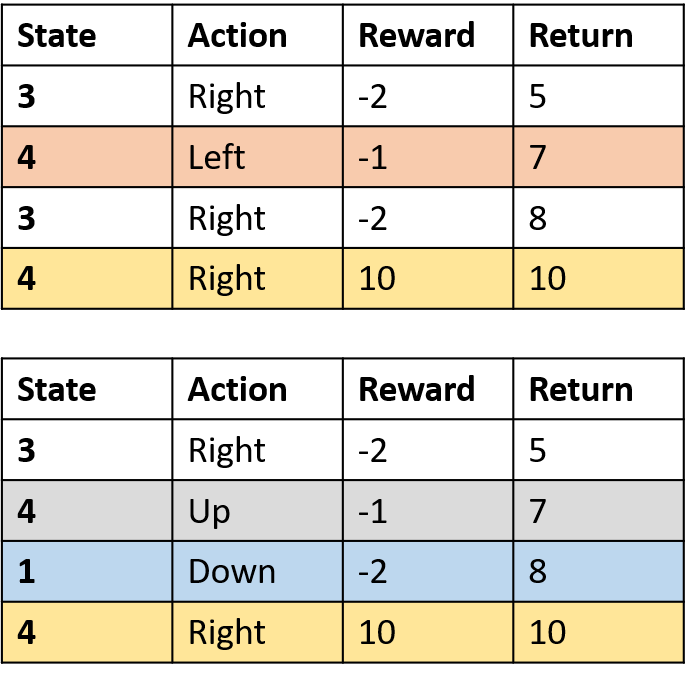
- (s,a) bölüm başına bir kez -> ortalama al
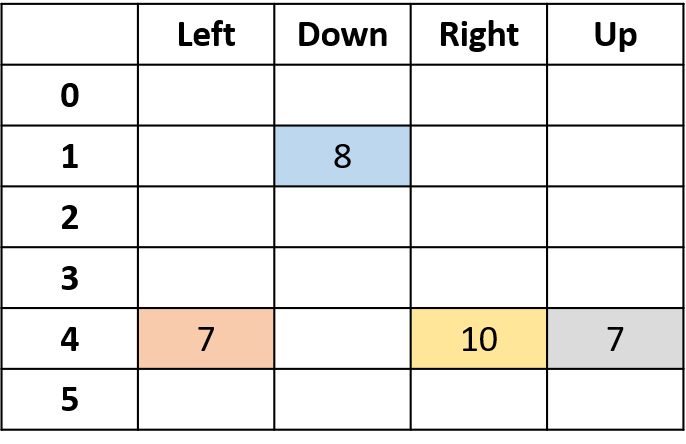
Q(3, sağ) - ilk-ziyaret Monte Carlo
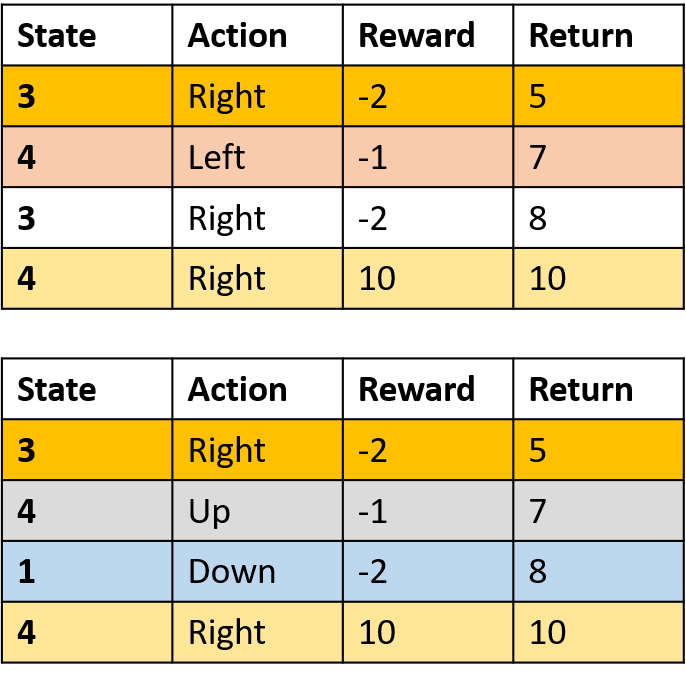
- Bölüm içinde (s,a) için ilk ziyareti ortala
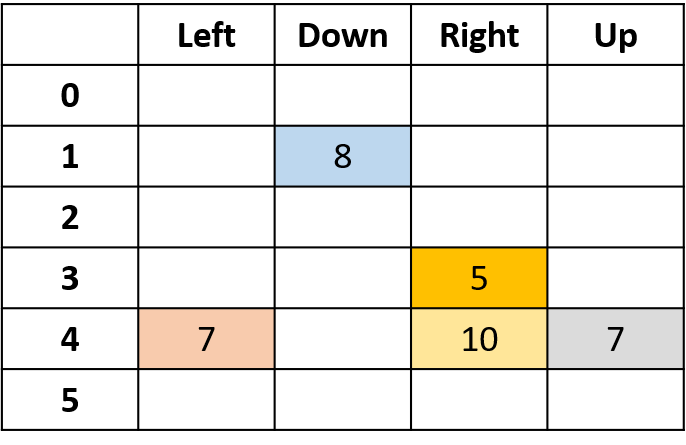
Q(3, sağ) - her-ziyaret Monte Carlo
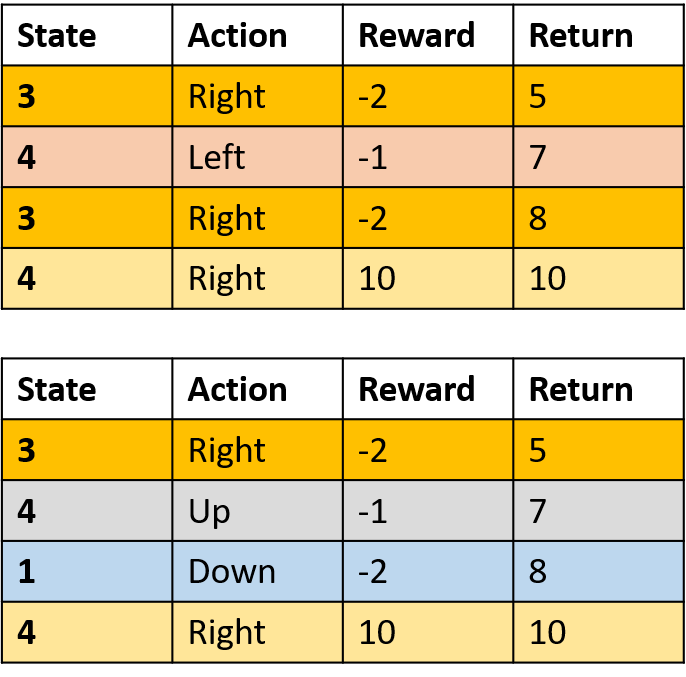
- Bölüm içinde (s,a) için her ziyareti ortala
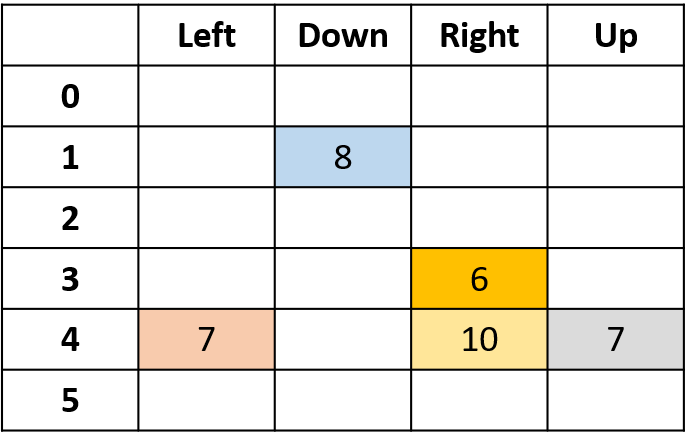
Hepsini birleştirme