Keşif ve sömürü dengesini kurma
Python ile Gymnasium'da Reinforcement Learning

Fouad Trad
Machine Learning Engineer
Rastgele eylemlerle eğitim

Keşif–sömürü ödünleşimi

Yemek seçimi

Epsilon-greedy stratejisi
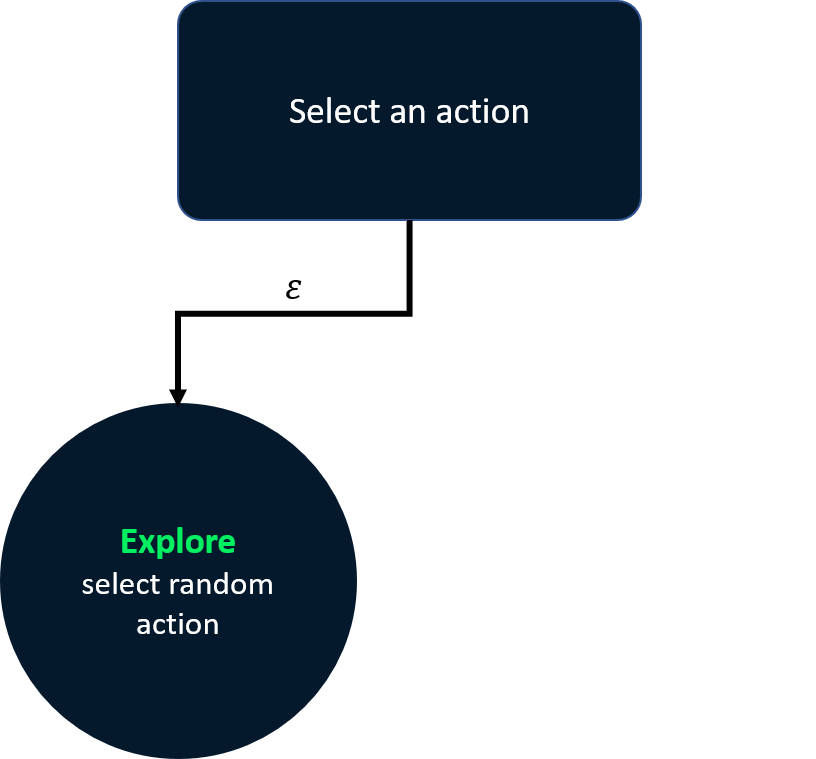
Epsilon-greedy stratejisi
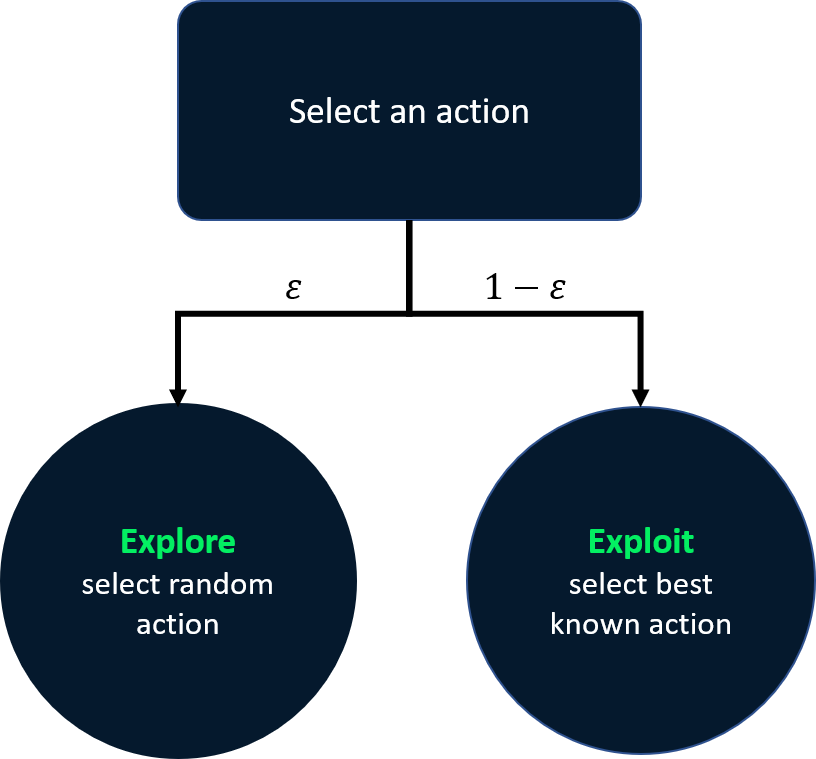
Azalan epsilon-greedy stratejisi

Frozen Lake ile uygulama

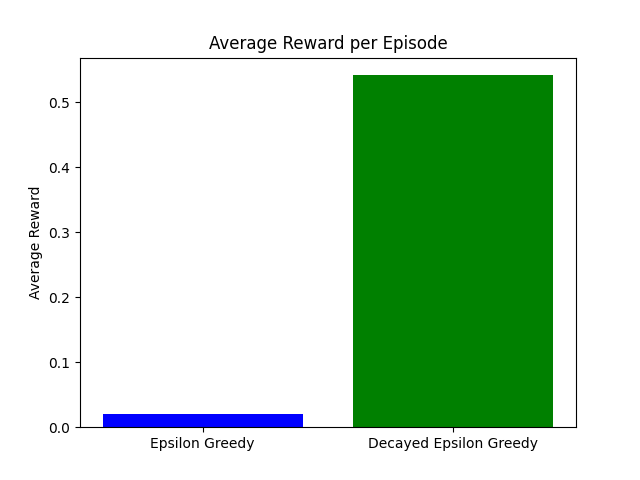
Stratejileri karşılaştırma