Q-öğrenme
Python ile Gymnasium'da Reinforcement Learning

Fouad Trad
Machine Learning Engineer
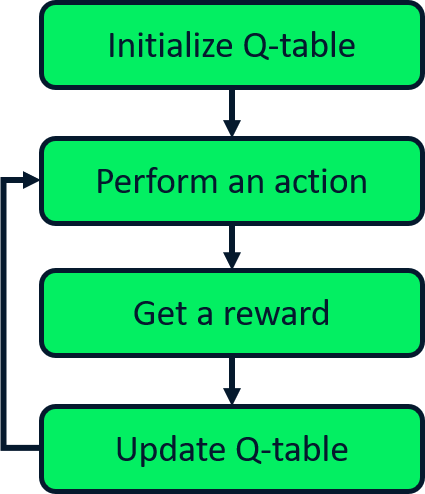
Q-öğrenmeye giriş
Q-öğrenme vs. SARSA
SARSA

- Alınan eyleme göre günceller
- On-policy öğrenici
Q-öğrenme

- Alınan eylemlerden bağımsız günceller
- Off-policy öğrenici
Q-öğrenme güncellemesi
def update_q_table(state, action, reward, new_state):old_value = Q[state, action]next_max = max(Q[new_state])Q[state, action] = (1 - alpha) * old_value + alpha * (reward + gamma * next_max)
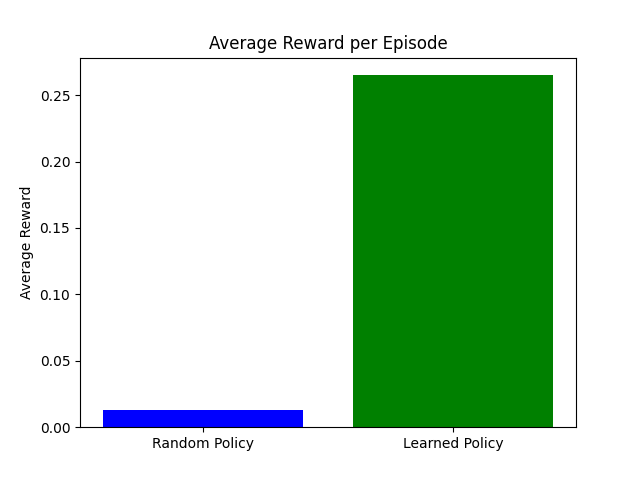
Q-öğrenme değerlendirmesi