Çift Q-öğrenme
Python ile Gymnasium'da Reinforcement Learning

Fouad Trad
Machine Learning Engineer
Q-öğrenme
- En uygun eylem-değer fonksiyonunu tahmin eder
- Maks Q’ya göre güncellediği için Q-değerlerini fazla tahmin eder
- Alt-optimal politika öğrenimine yol açabilir

Çift Q-öğrenme
- İki Q-tablosu kullanır
- Her tablo diğeri temel alınarak güncellenir
- Q-değerlerini fazla tahmin etme riskini azaltır
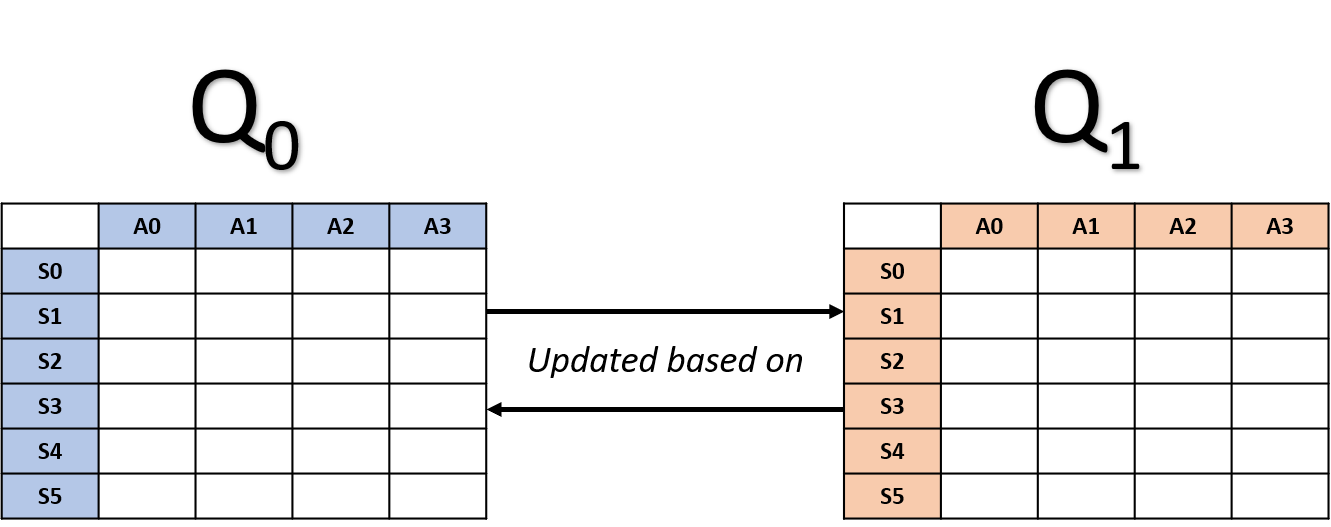
Çift Q-öğrenme güncellemeleri
- Rastgele bir tablo seçin
Q0 güncellemesi
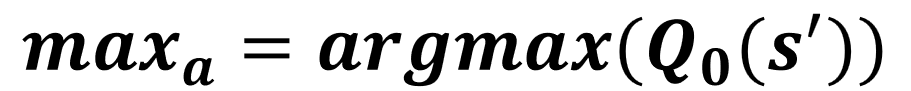
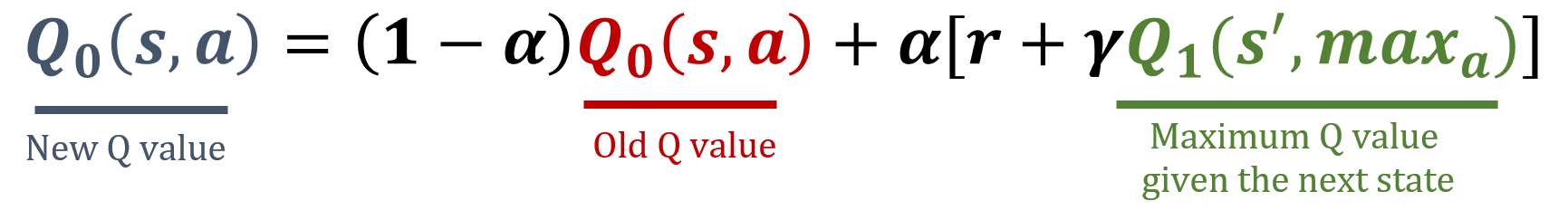
Q1 güncellemesi
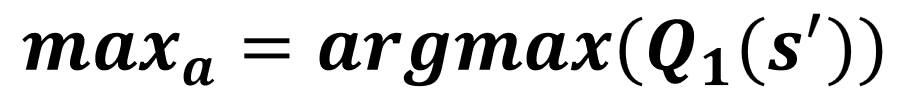
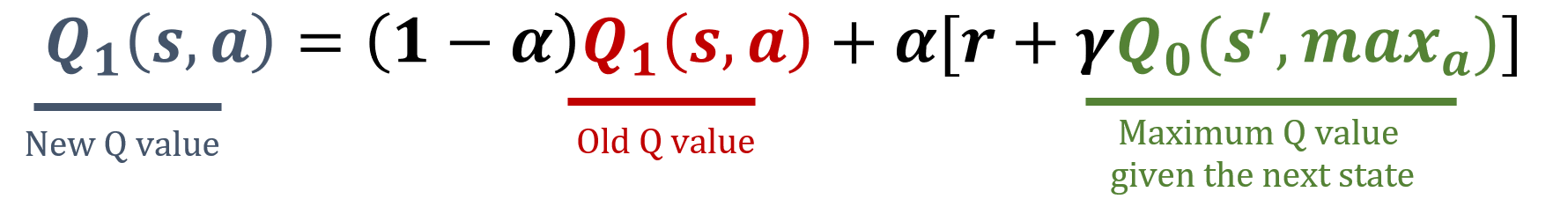
Çift Q-öğrenme
- Aşırı tahmin yanlılığını azaltır
- Q0 ve Q1 güncellemeleri dönüşümlü yapılır
- Her iki tablo da öğrenmeye katkı sağlar
Frozen Lake ile uygulama

update_q_tables() uygulaması
def update_q_tables(state, action, reward, next_state): # Rastgele bir Q-tablosu indeksi seçin (0 veya 1) i = np.random.randint(2)# İlgili Q-tablosunu güncelleyin best_next_action = np.argmax(Q[i][next_state])Q[i][state, action] = (1 - alpha) * Q[i][state, action] + alpha * (reward + gamma * Q[1-i][next_state, best_next_action])
Ajanın politikası