Beklenen SARSA
Python ile Gymnasium'da Reinforcement Learning

Fouad Trad
Machine Learning Engineer
Beklenen SARSA
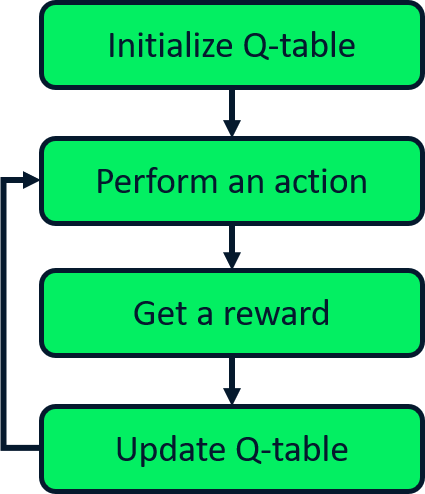
Beklenen SARSA güncellemesi
SARSA

Q-öğrenme

Beklenen SARSA
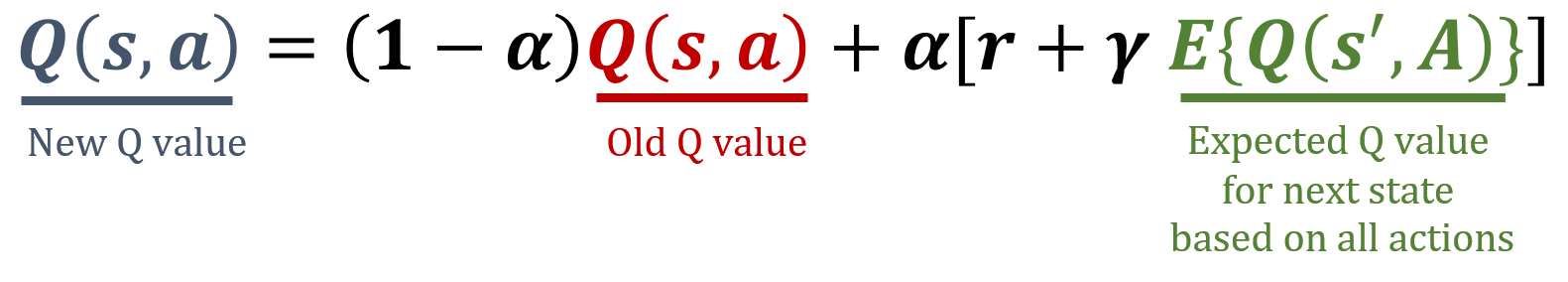
Sonraki durumun beklenen değeri
- Tüm eylemleri dikkate alır

- Rastgele eylemler → eşit olasılıklar

Frozen Lake ile uygulama

Beklenen SARSA güncelleme kuralı
def update_q_table(state, action, next_state, reward):expected_q = np.mean(Q[next_state])Q[state, action] = (1-alpha) * Q[state, action] + alpha * (reward + gamma * expected_q)
Ajanın politikası