Politika yinelemesi ve değer yinelemesi
Python ile Gymnasium'da Reinforcement Learning

Fouad Trad
Machine Learning Engineer
Politika yinelemesi
- En iyi politikayı bulmak için yinelemeli süreç

Politika yinelemesi
- En iyi politikayı bulmak için yinelemeli süreç

Politika yinelemesi
- En iyi politikayı bulmak için yinelemeli süreç
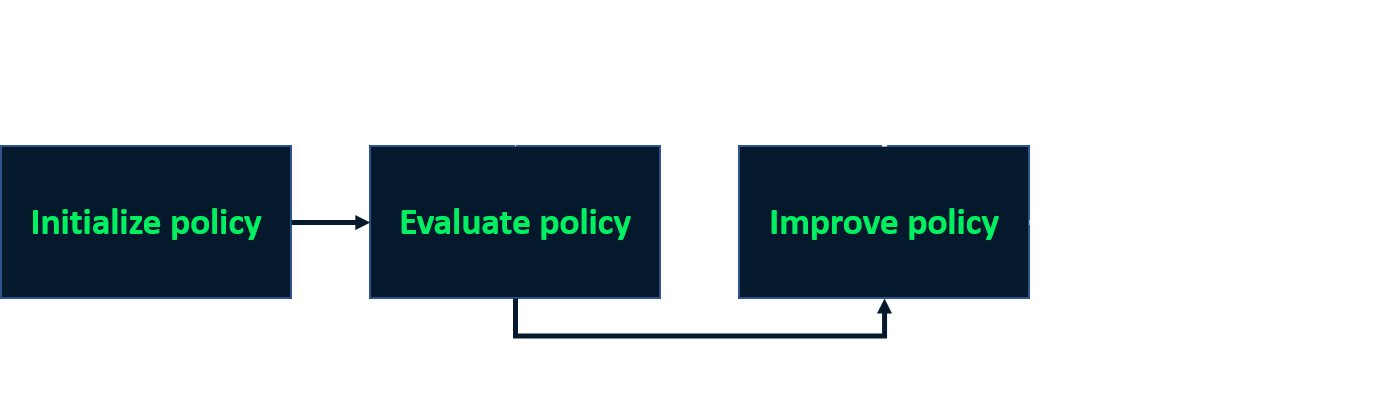
Politika yinelemesi
- En iyi politikayı bulmak için yinelemeli süreç
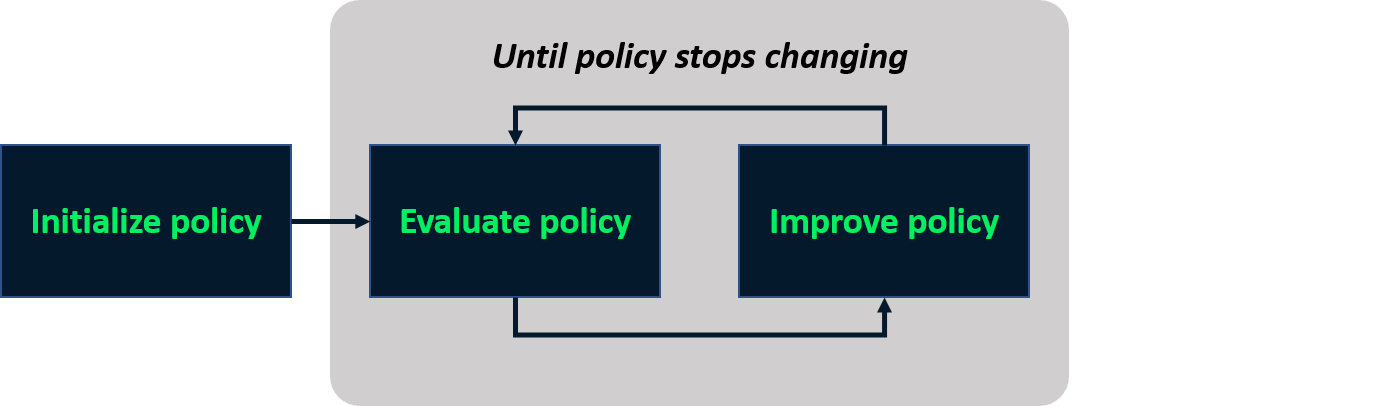
Politika yinelemesi
- En iyi politikayı bulmak için yinelemeli süreç
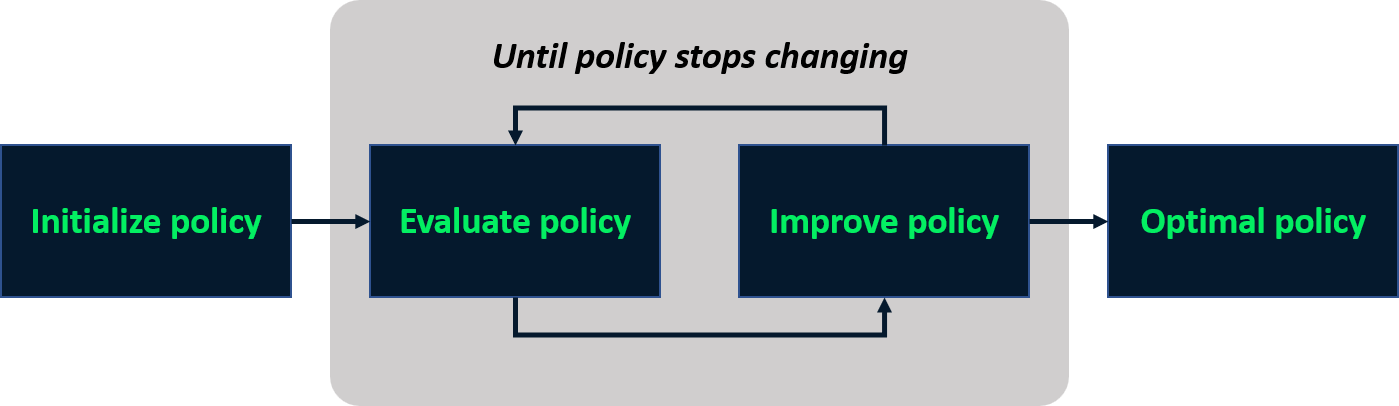
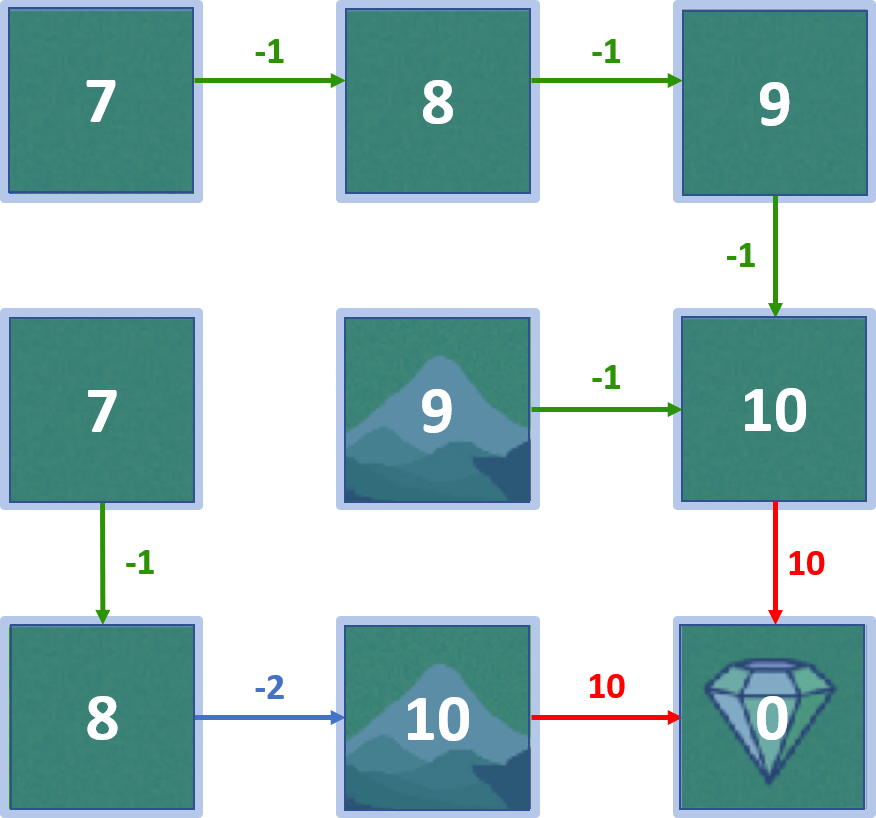
Izgara dünyası
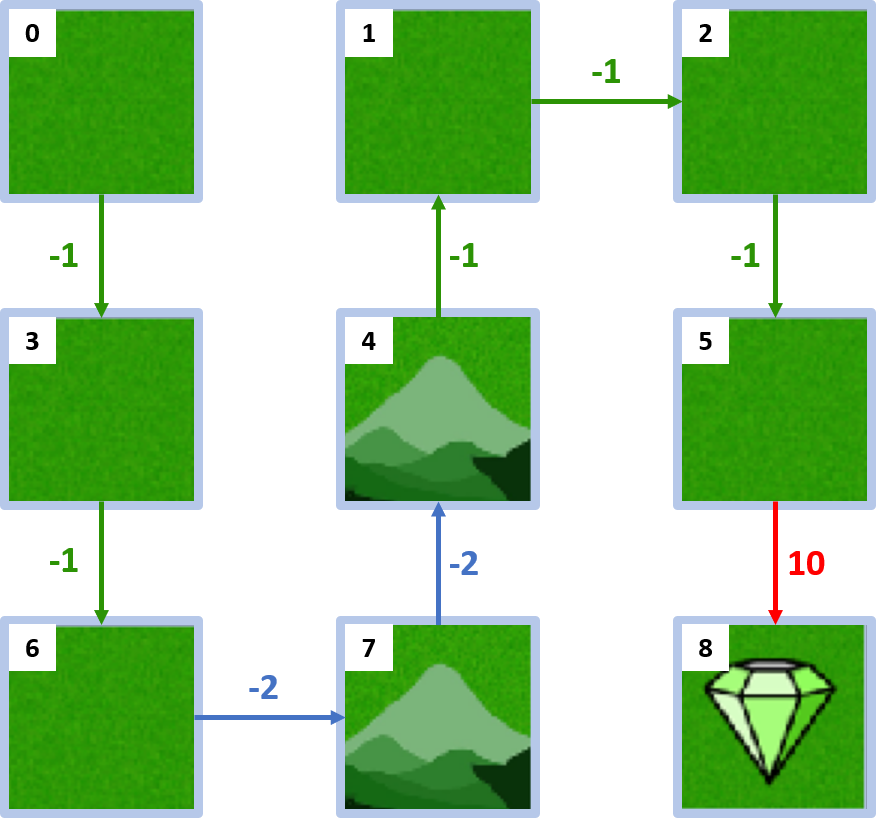
En iyi politika
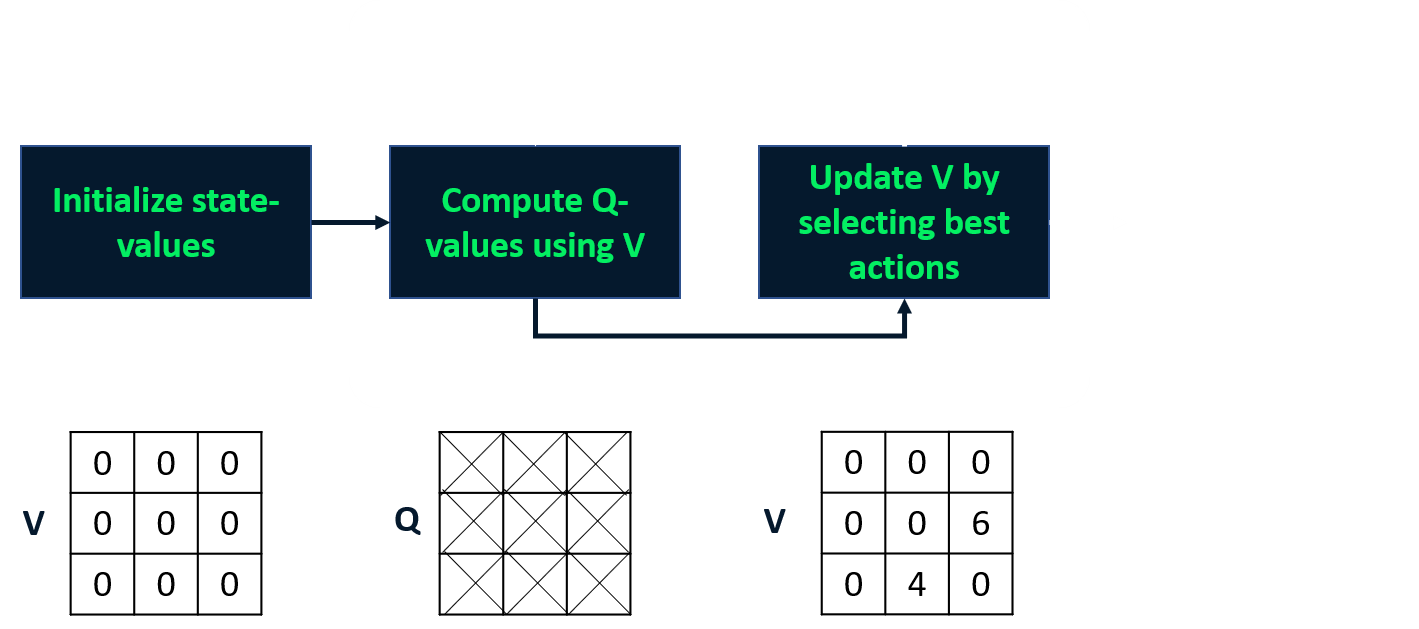
Değer yinelemesi
- Değerlendirme ve iyileştirmeyi tek adımda birleştirir
- En iyi durum-değer fonksiyonunu hesaplar
- Politikayı buradan türetir

Değer yinelemesi
- Değerlendirme ve iyileştirmeyi tek adımda birleştirir.
- En iyi durum-değer fonksiyonunu hesaplar
- Politikayı buradan türetir

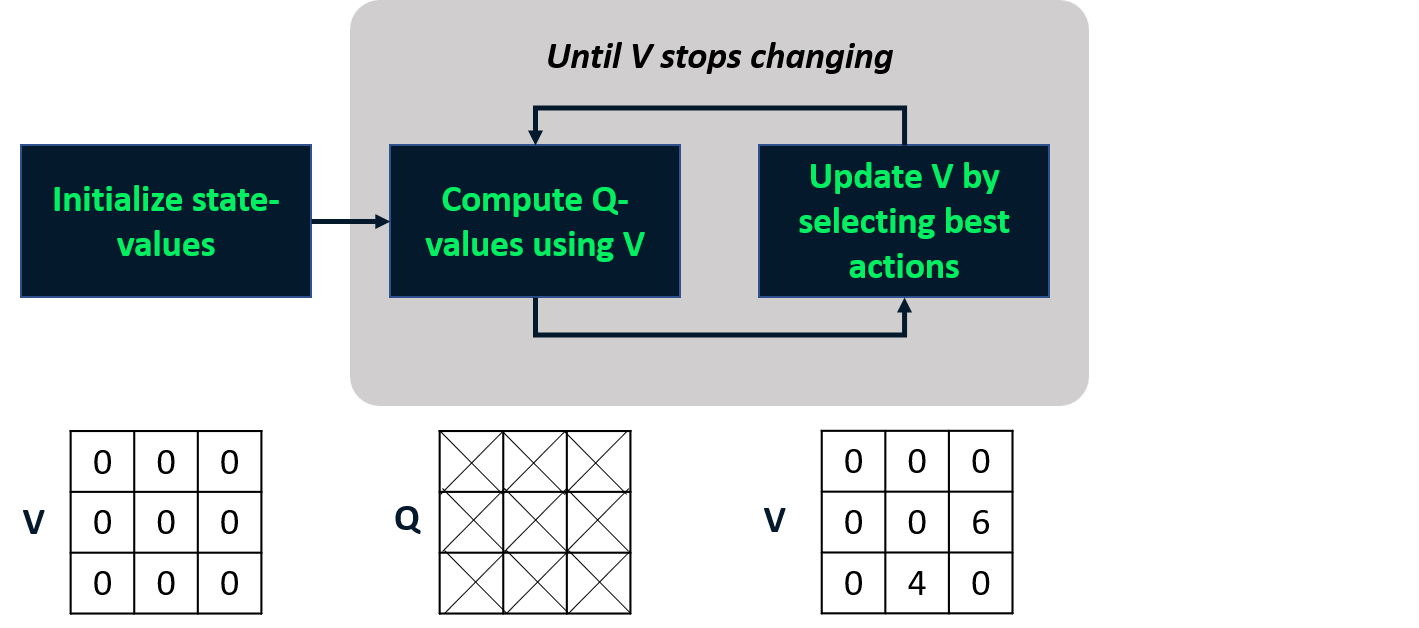
Değer yinelemesi
- Değerlendirme ve iyileştirmeyi tek adımda birleştirir.
- En iyi durum-değer fonksiyonunu hesaplar
- Politikayı buradan türetir
Değer yinelemesi
- Değerlendirme ve iyileştirmeyi tek adımda birleştirir.
- En iyi durum-değer fonksiyonunu hesaplar
- Politikayı buradan türetir
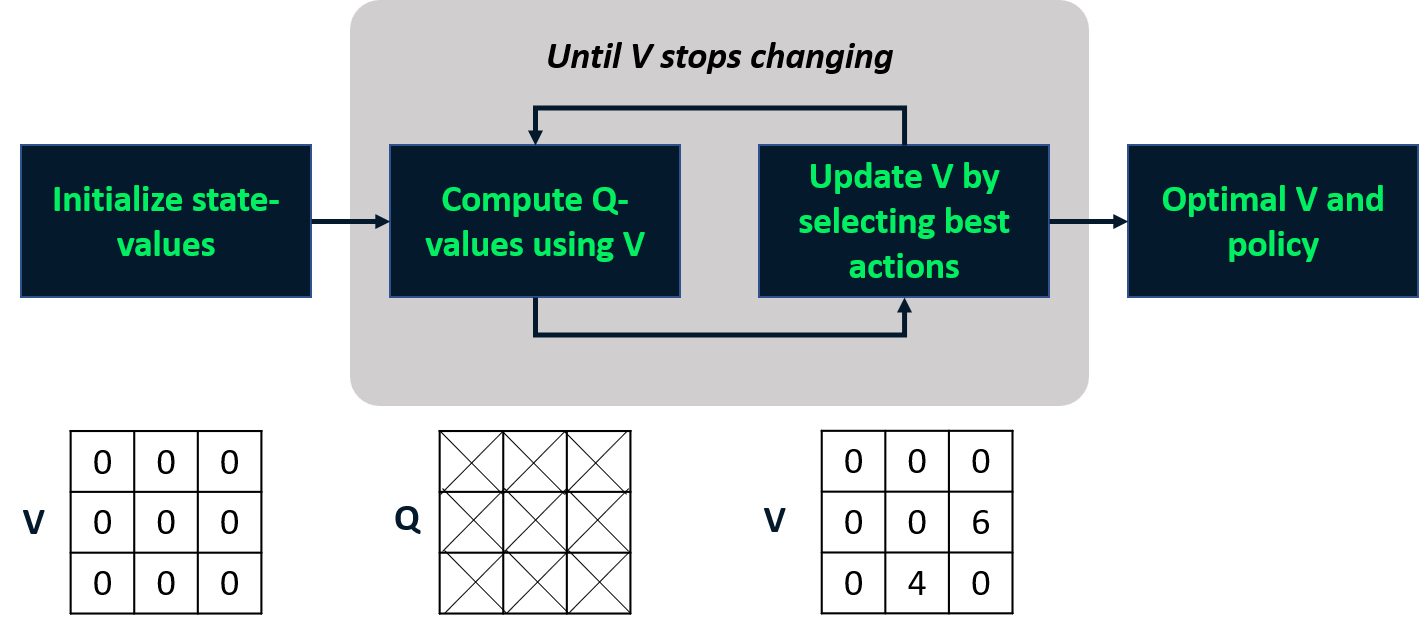
Değer yinelemesi
- Değerlendirme ve iyileştirmeyi tek adımda birleştirir.
- En iyi durum-değer fonksiyonunu hesaplar
- Politikayı buradan türetir
En iyi politika

