Simpson Paradoksu
R'de Orta Düzey Regresyon

Richie Cotton
Data Evangelist at DataCamp
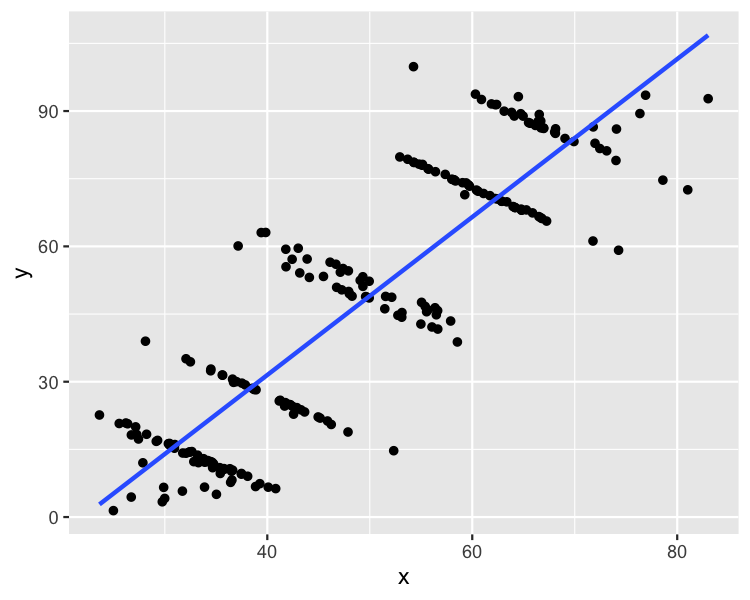
Tüm veri setini çizmek
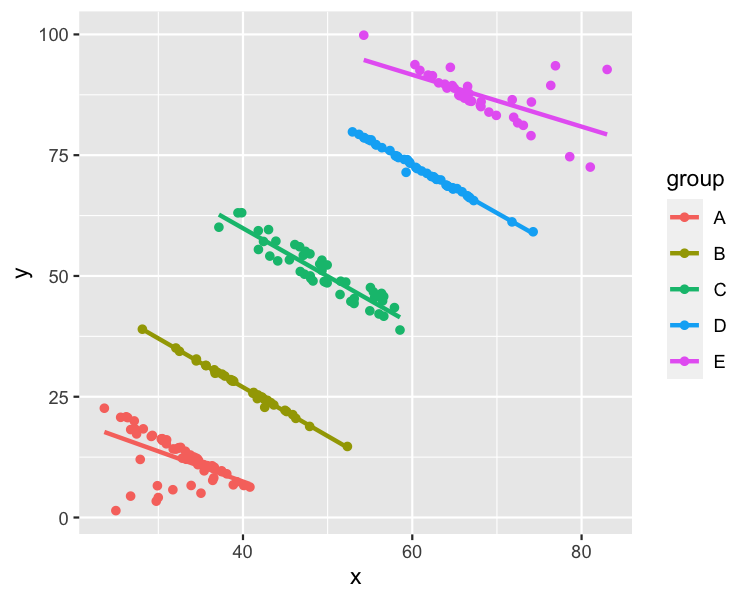
Gruba göre çizmek
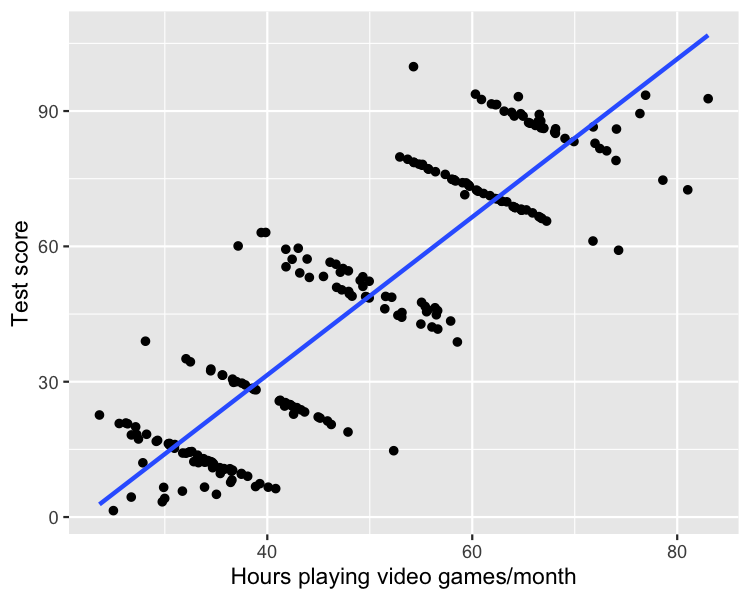
Test puanı örneği
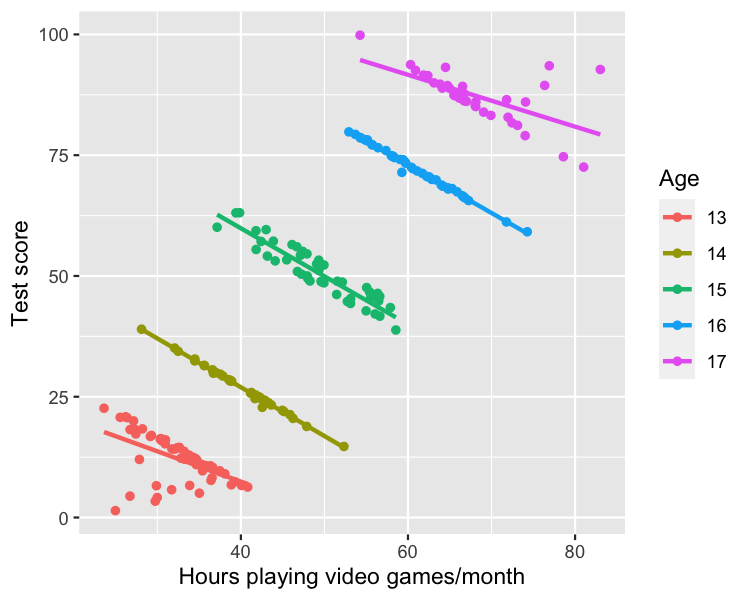
Bulaşıcı hastalık örneği
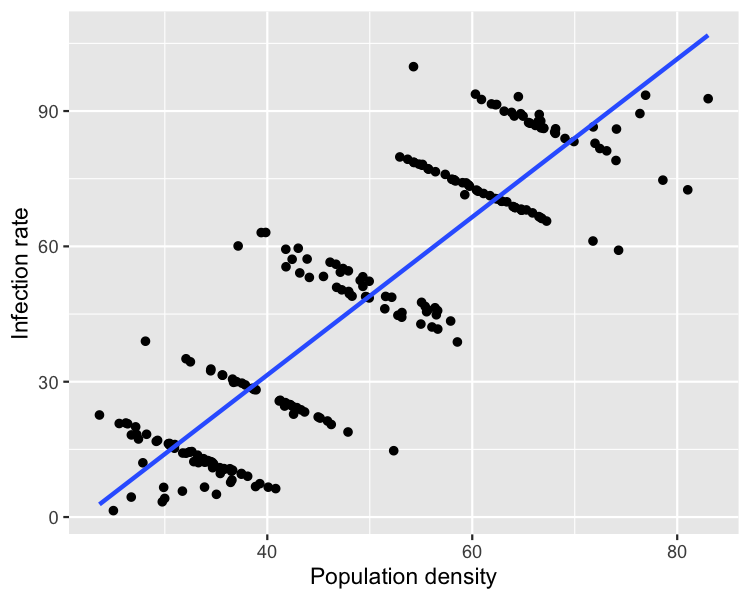
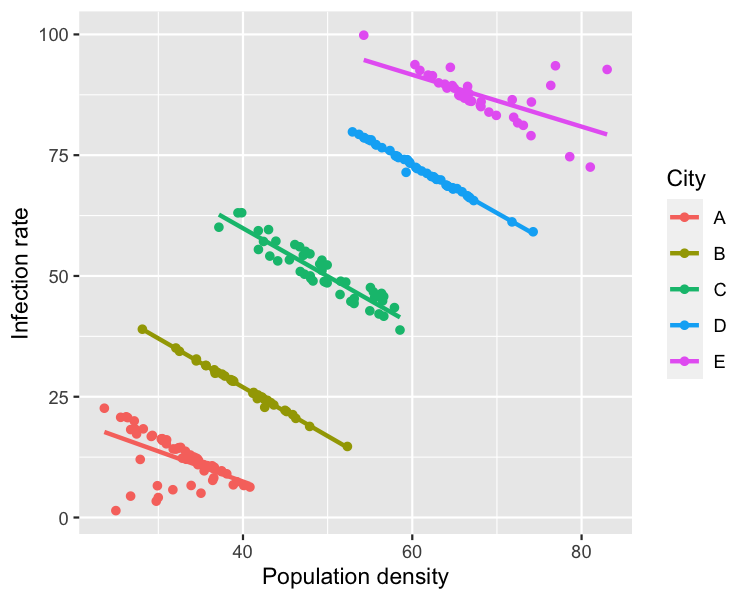
1 https://stats.stackexchange.com/questions/478463/examples-of-simpsons-paradox-being-resolved-by-choosing-the-aggregate-data

