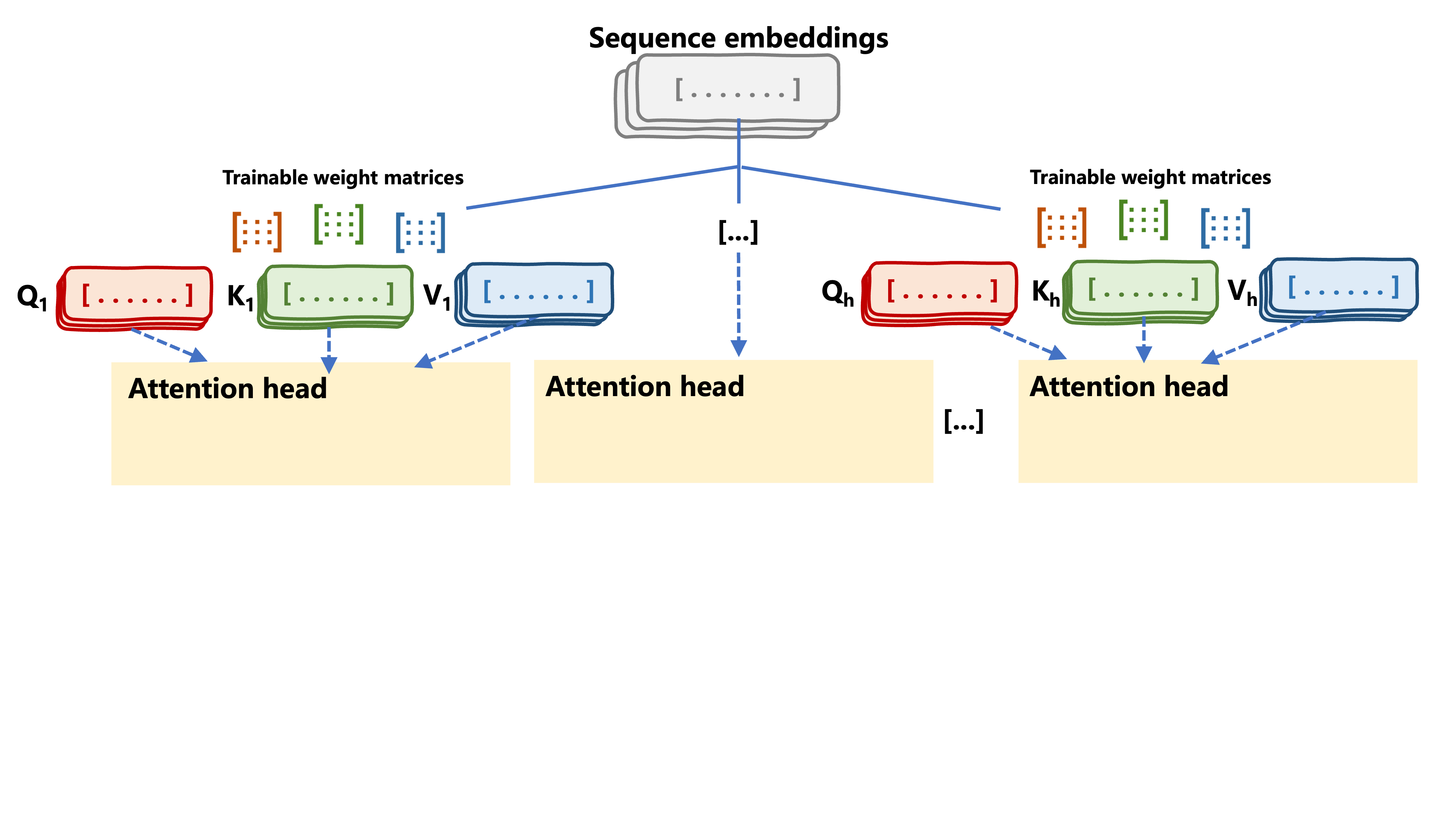
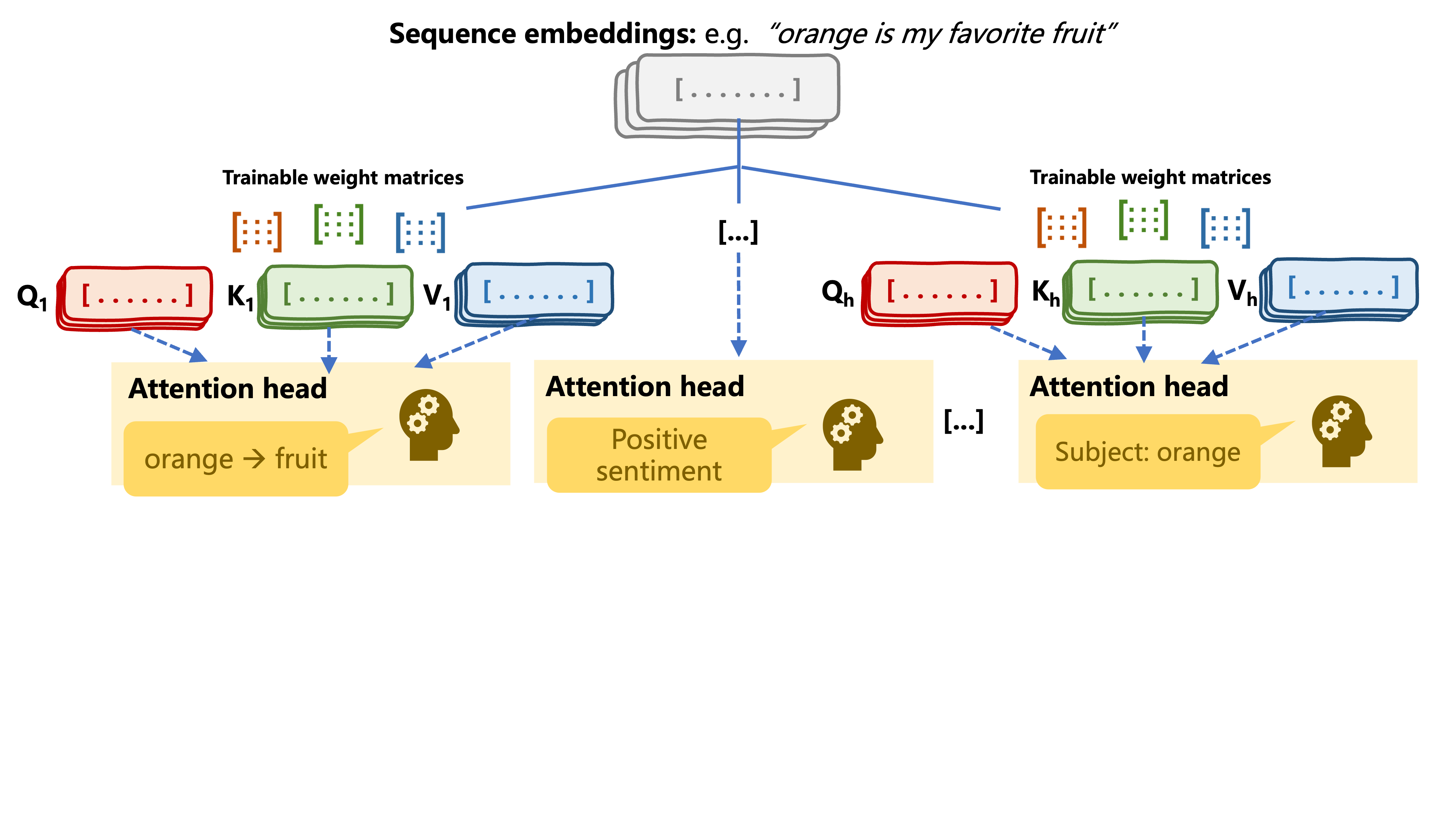
def split_heads(self, x, batch_size):
seq_length = x.size(1)
x = x.reshape(batch_size, seq_length, self.num_heads, self.head_dim)
return x.permute(0, 2, 1, 3)
def compute_attention(self, query, key, value, mask=None):
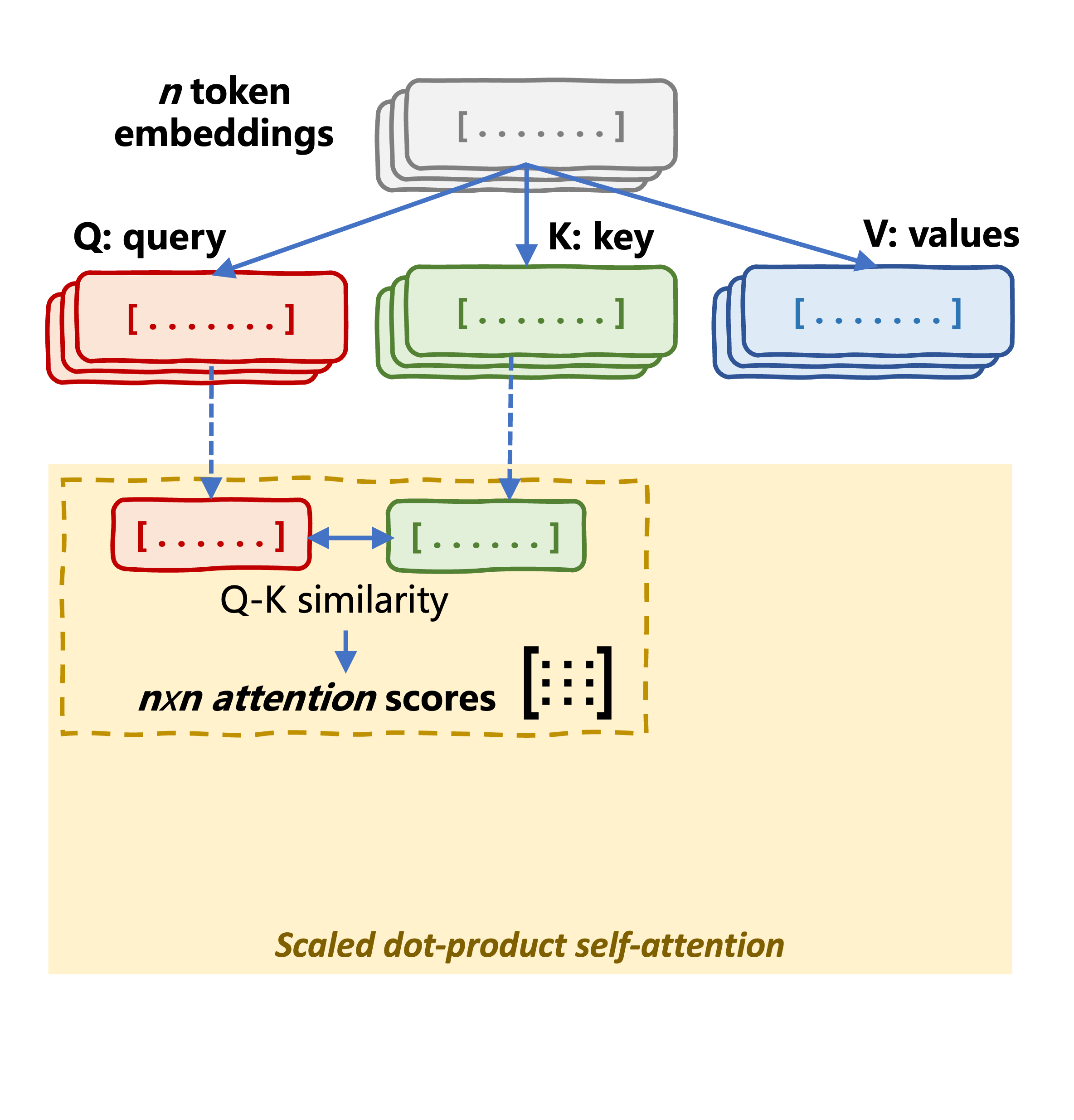
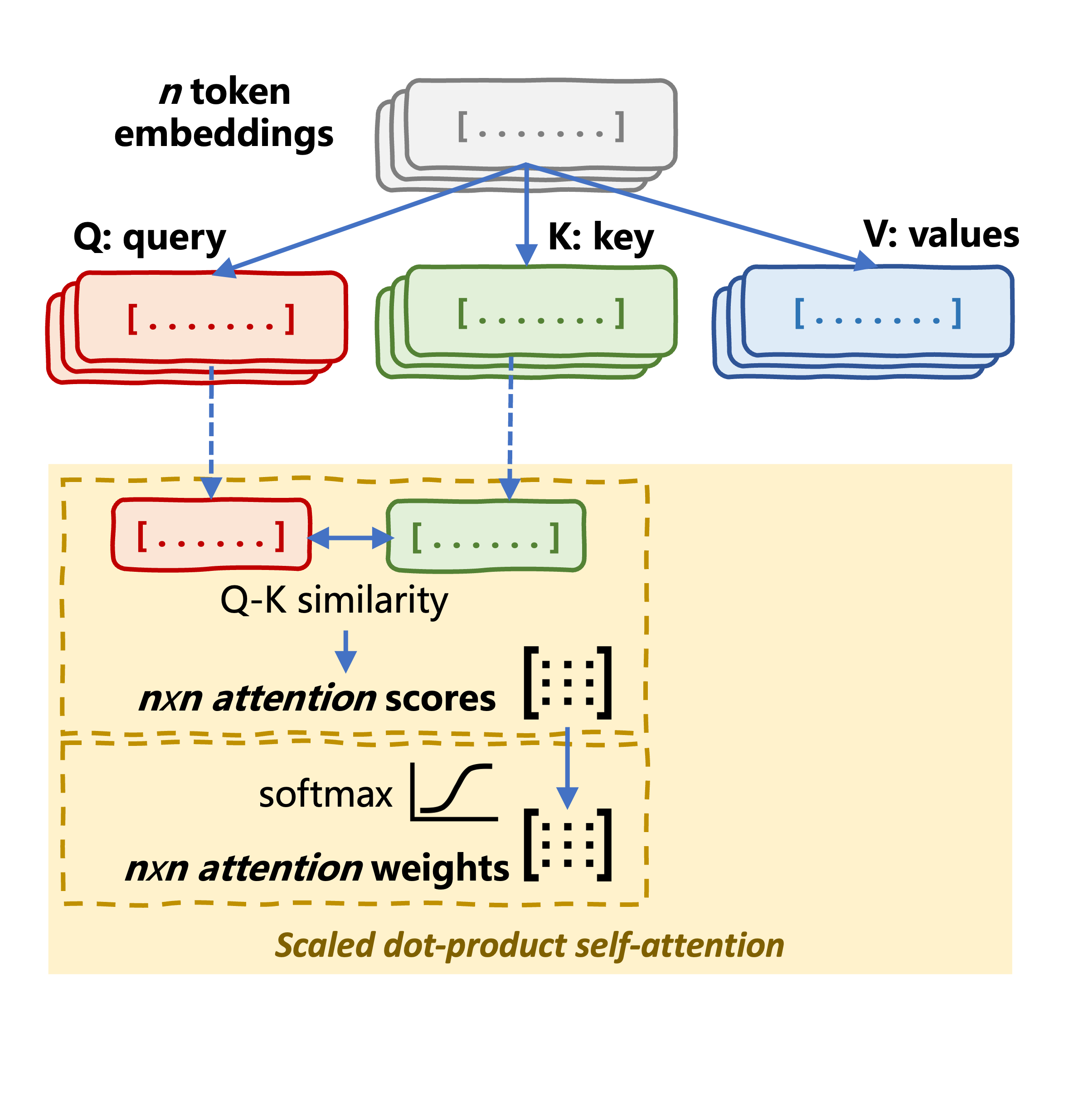
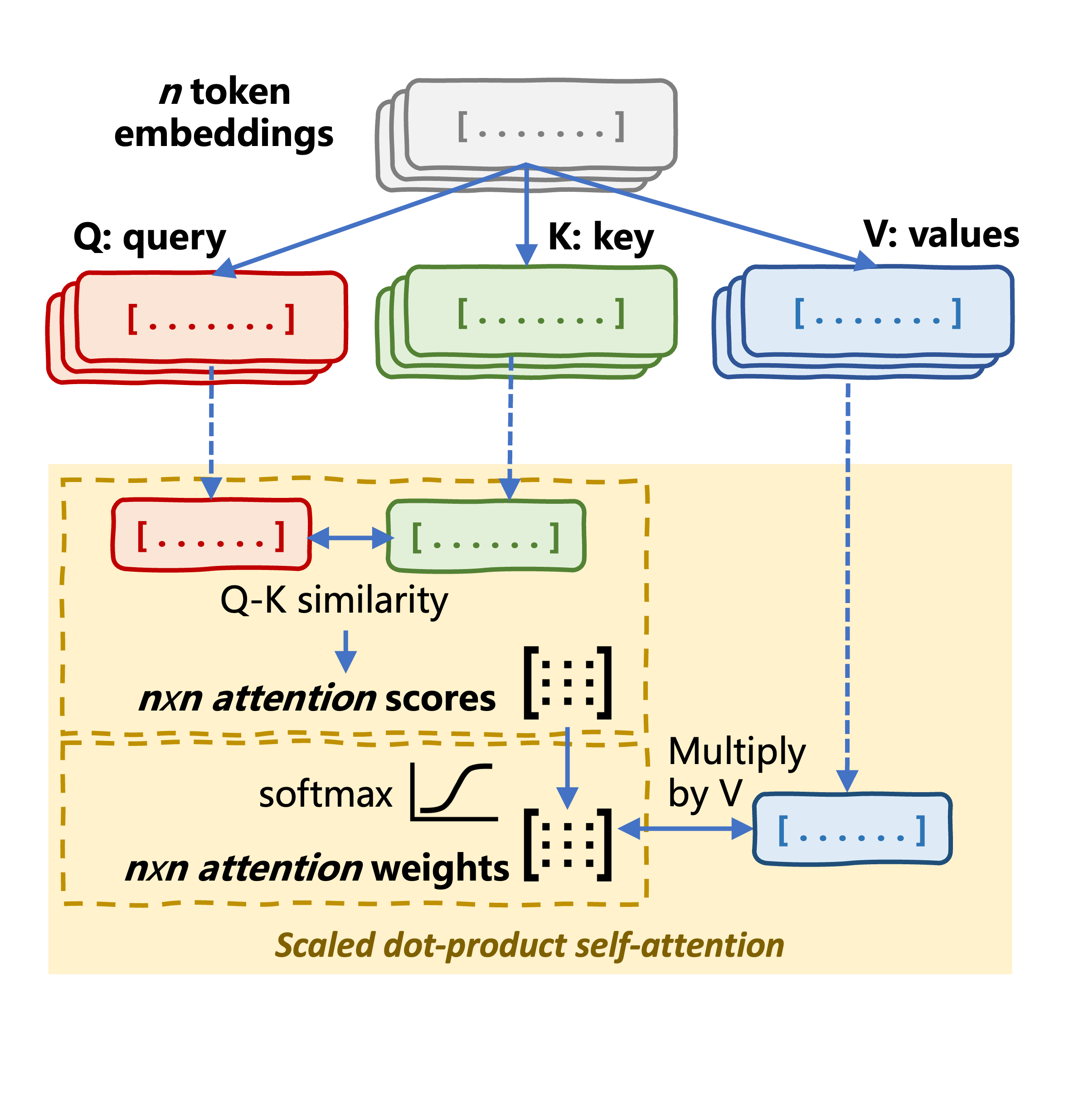
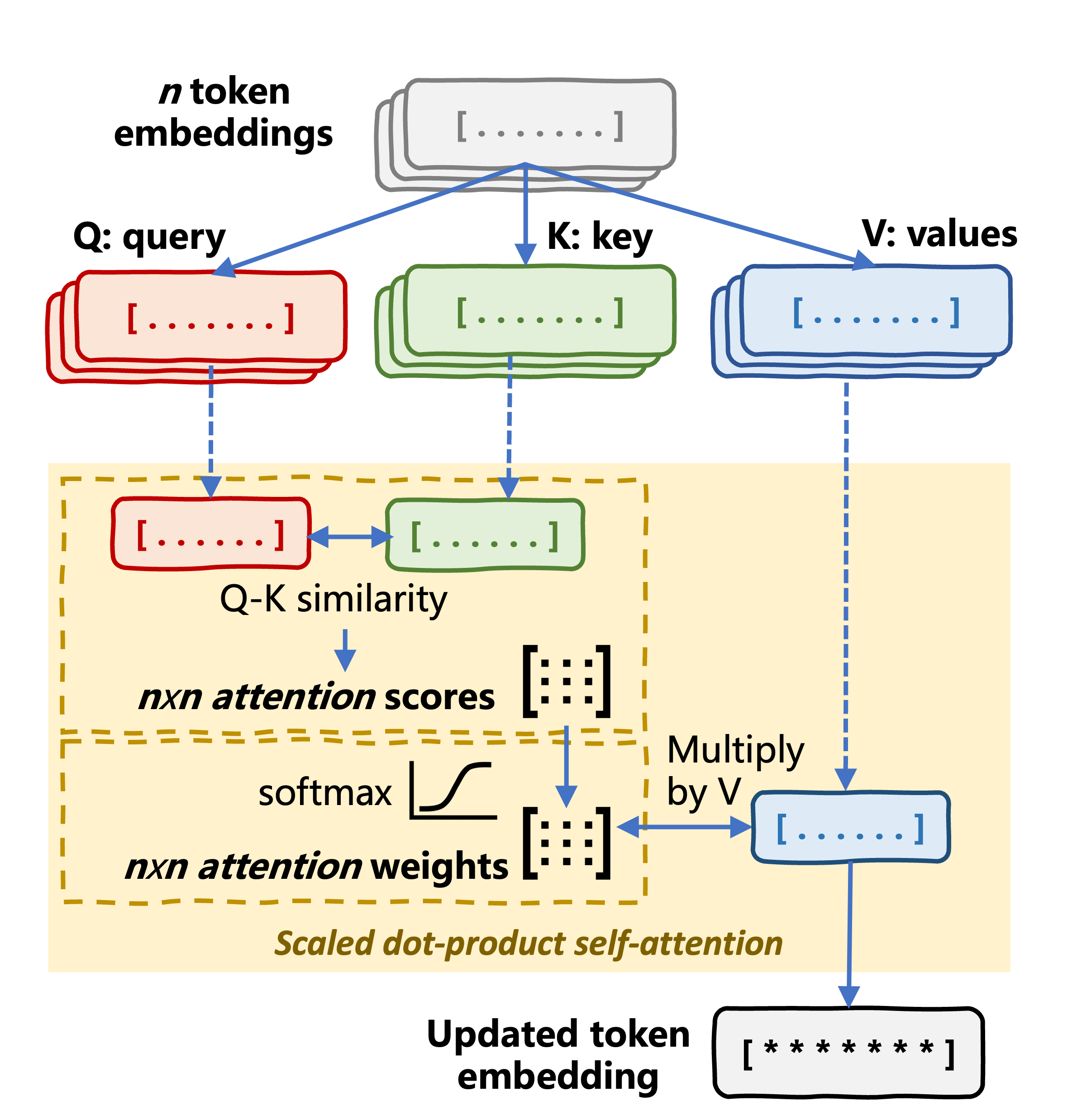
scores = torch.matmul(query, key.transpose(-2, -1)) / (self.head_dim ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attention_weights = F.softmax(scores, dim=-1)
return torch.matmul(attention_weights, value)
def combine_heads(self, x, batch_size):
x = x.permute(0, 2, 1, 3).contiguous()
return x.view(batch_size, -1, self.d_model)
compute_attention(): F.softmax() ile dikkat ağırlıklarını hesaplartorch.matmul(attention_weights, value): değerlerin ağırlıklı toplamı