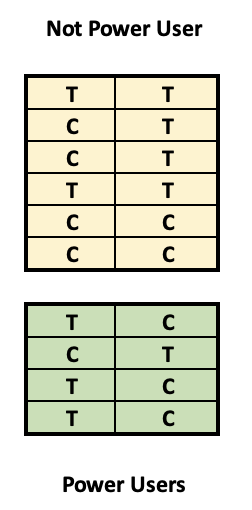
Deneysel veri kurulumu
Python ile Deney Tasarımı

James Chapman
Curriculum Manager, DataCamp
Rastgeleleştirmenin sorunu
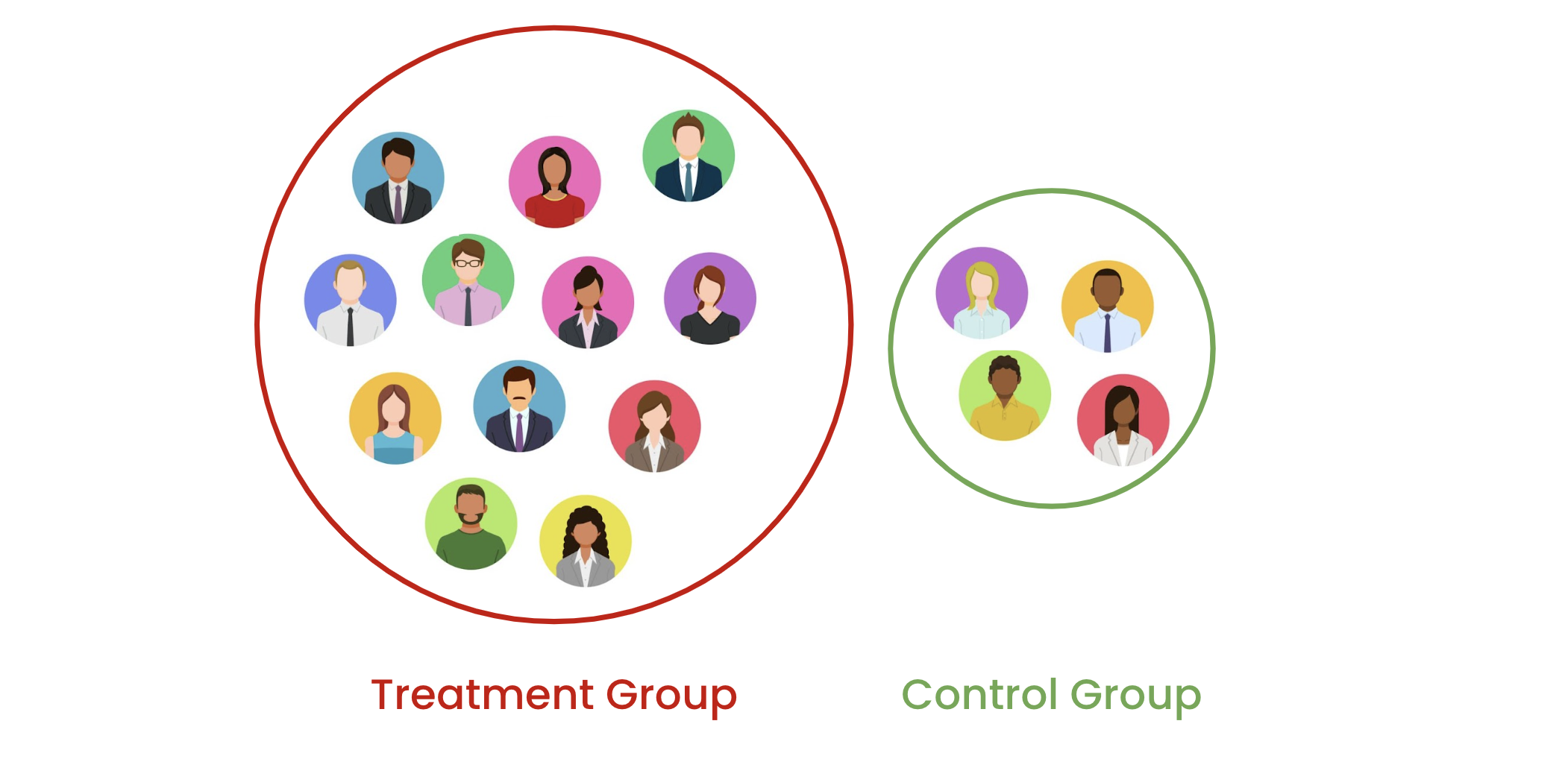
Rastgeleleştirmenin sorunu
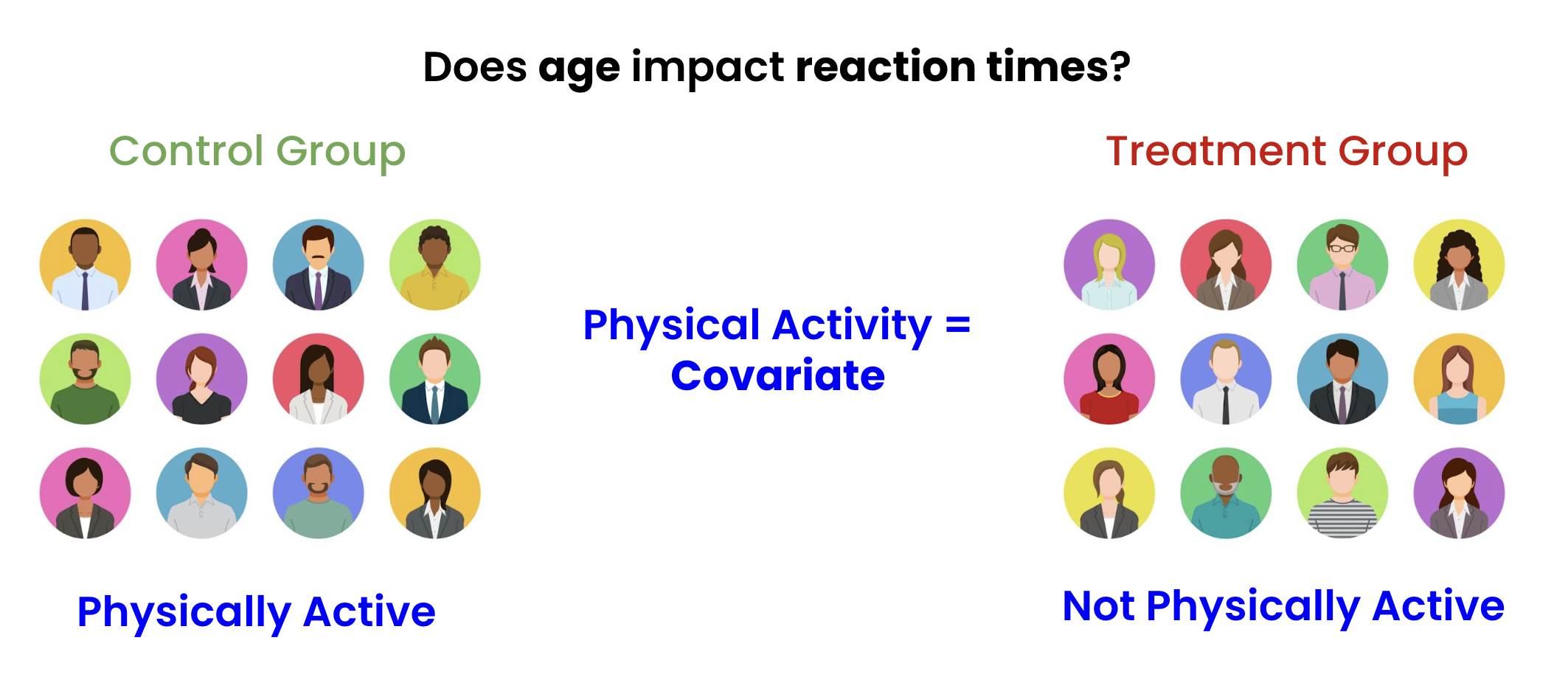
Sonuç: tedavi etkisini ölçmek daha zor!
Blok rastgeleleştirme
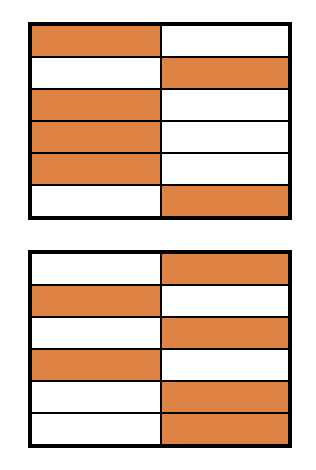
- 24 denek iki gruba ayrılır, sonra rastgeleleştirilir
Bölünmeleri görselleştirme
Tabakalı rastgeleleştirme