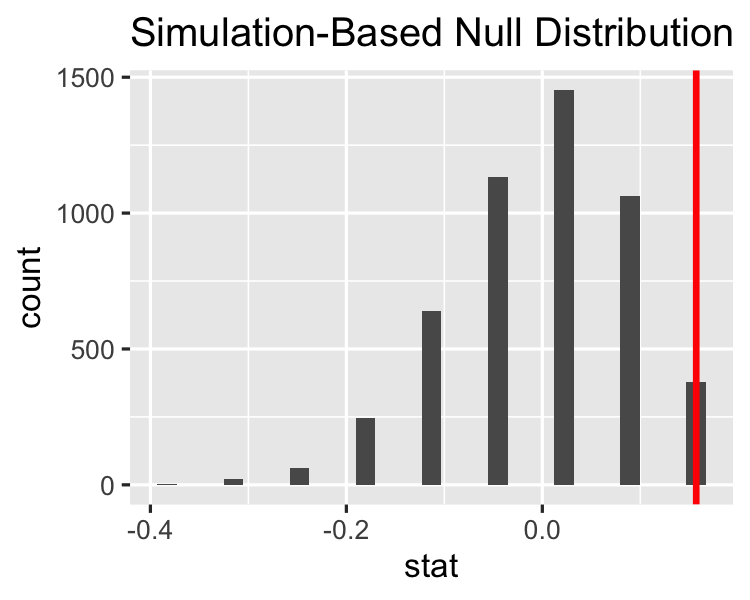
infer hattına devam
R ile Hipotez Testi

Richie Cotton
Data Evangelist at DataCamp
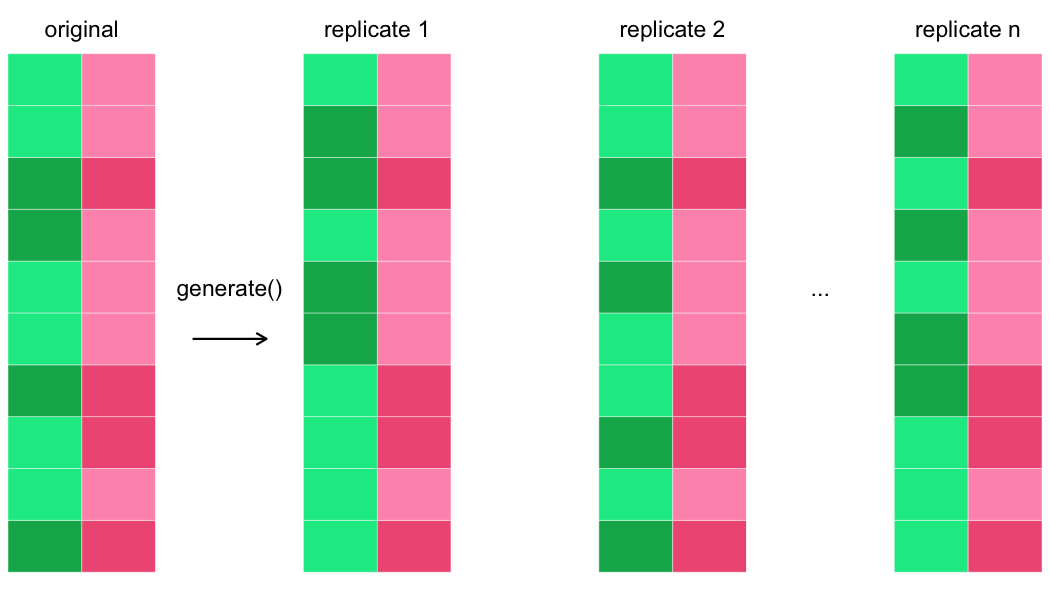
Birçok çoğaltım üretme
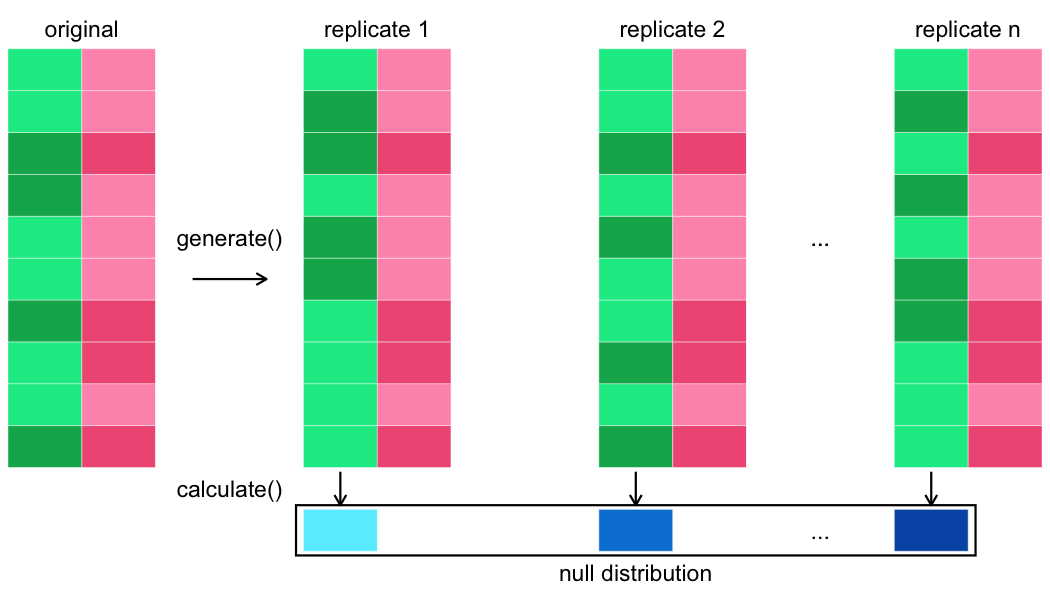
Test istatistiğini hesaplama
Sıfır dağılımını görselleştirme
visualize(null_distn)
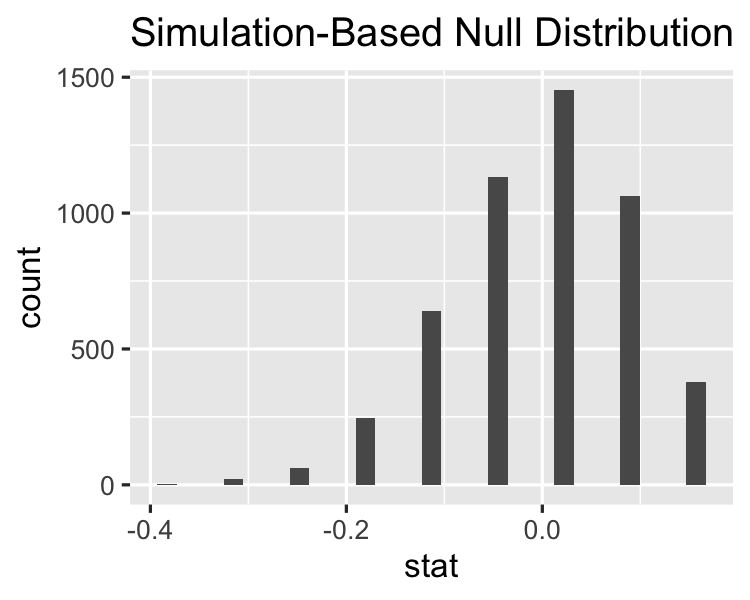
Test istatistiğini özgün veri setinde hesaplama
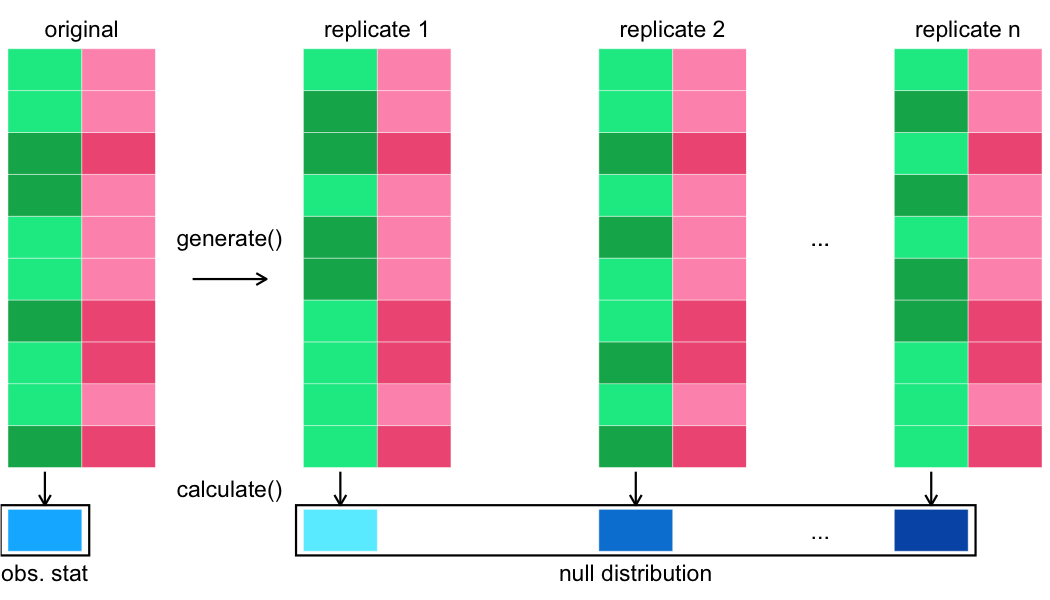
Sıfır dağılımı vs gözlenen istatistik