Bootstrap'a giriş
R'de Örnekleme

Richie Cotton
Data Evangelist at DataCamp
Yerine koyarak ya da koymadan
Yerine koymadan örnekleme

Yerine koyarak örnekleme ("yeniden örnekleme")

Yerine koymadan basit rastgele örnekleme
Anakütle

Örnek

Yerine koyarak basit rastgele örnekleme
Anakütle
Örnek

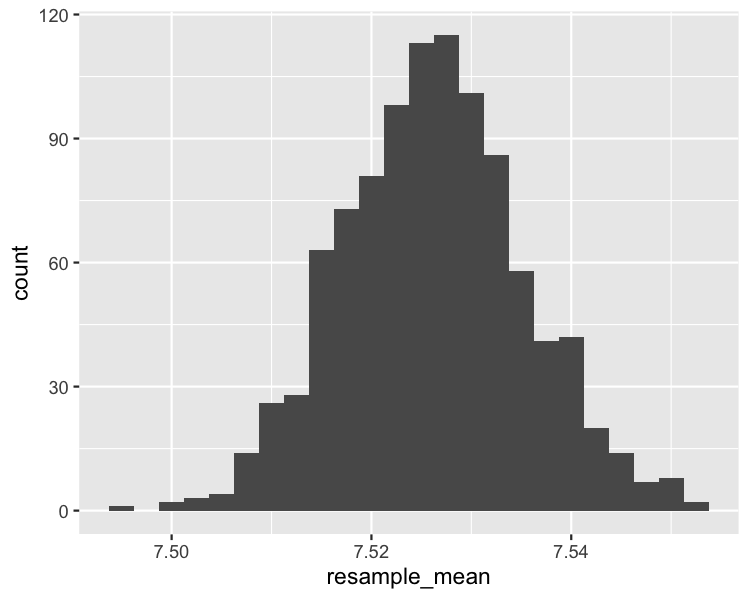
Bootstrap

Bootstrap dağılımı histogramı