Derin Q öğrenmeye giriş
Python ile Deep Reinforcement Learning

Timothée Carayol
Principal Machine Learning Engineer, Komment
Derin Q Öğrenme nedir?
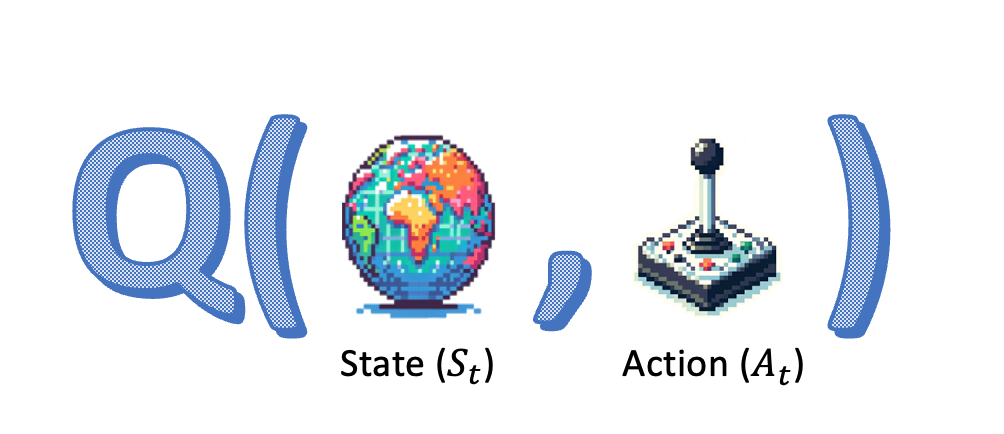
Q-Öğrenme özeti

Q-Öğrenme özeti


- Bellman denklemi: $Q$ için özyinelemeli formül
- Bellman’ın sağ tarafı: “TD-hedefi”
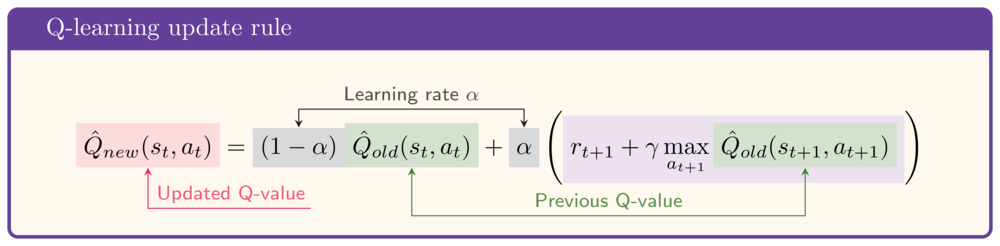
- Her adımdan sonra TD-hedefi ile $\hat{Q}$’yu güncelleyin
Q-Ağı
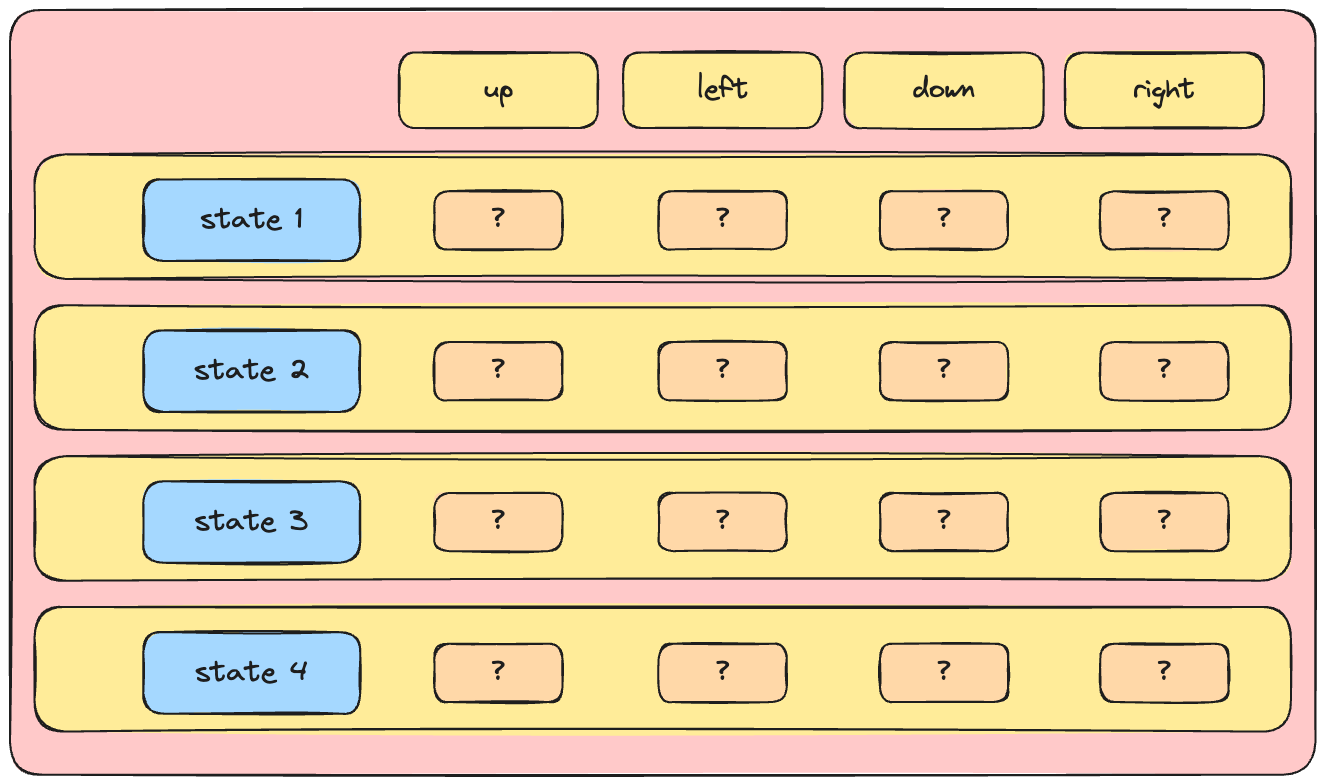
Q-Ağı
Q-Ağı
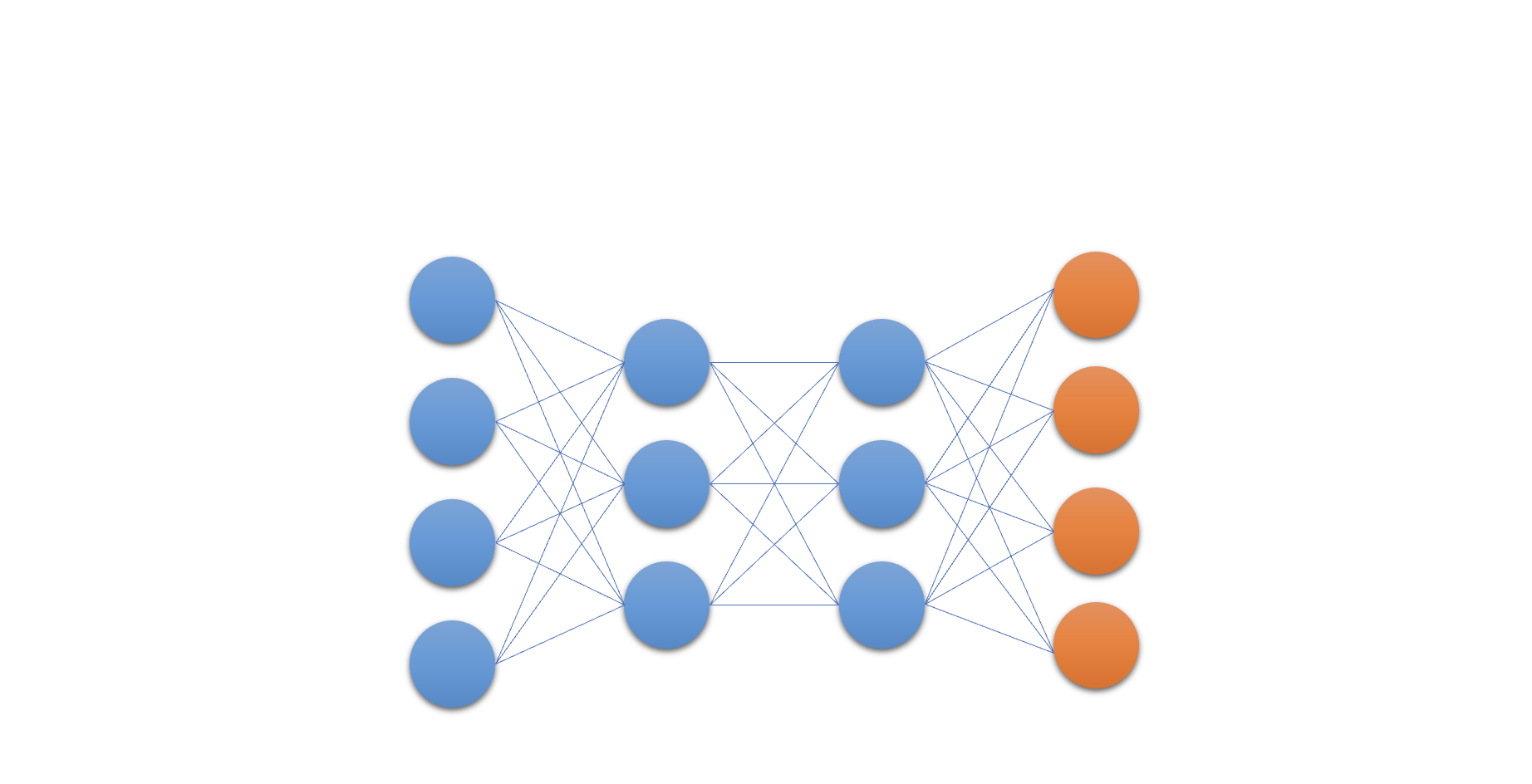
Q-Ağı
- Derin Q Öğrenmenin özünde: bir sinir ağı
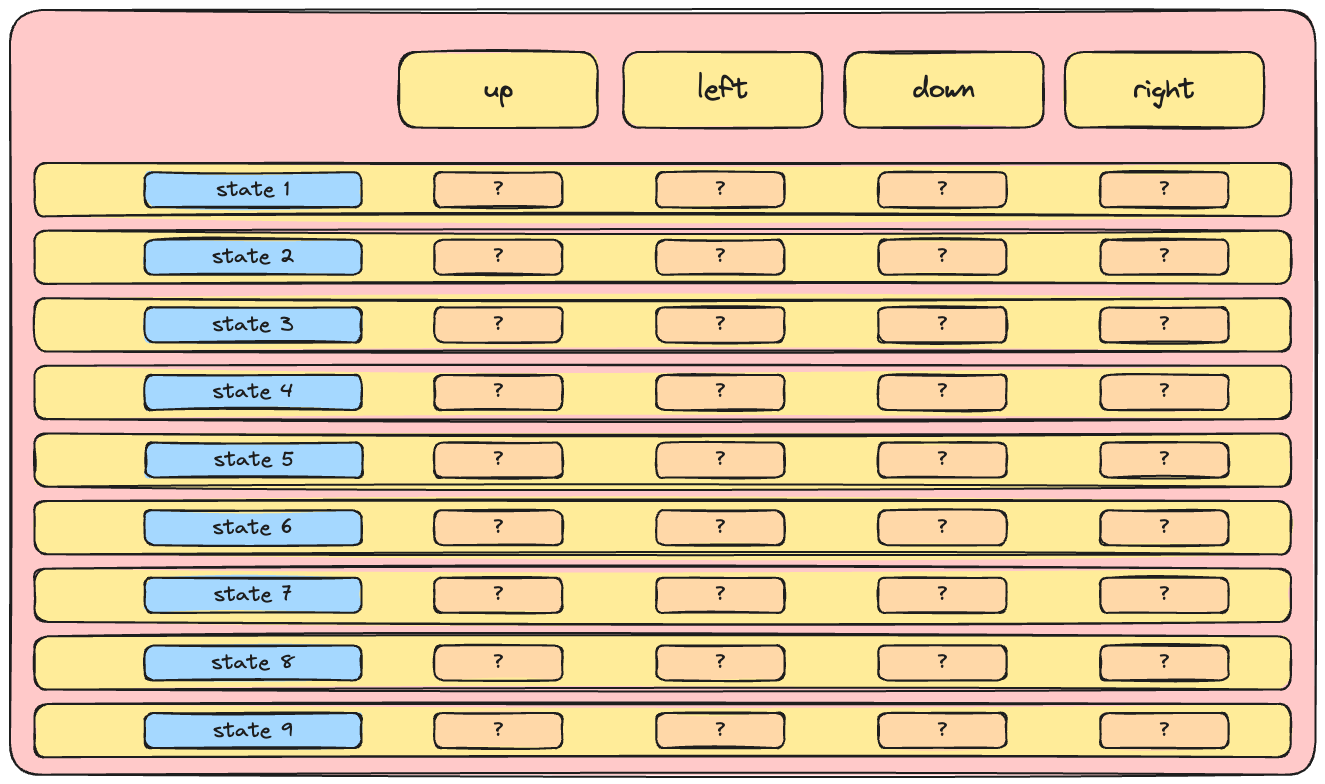
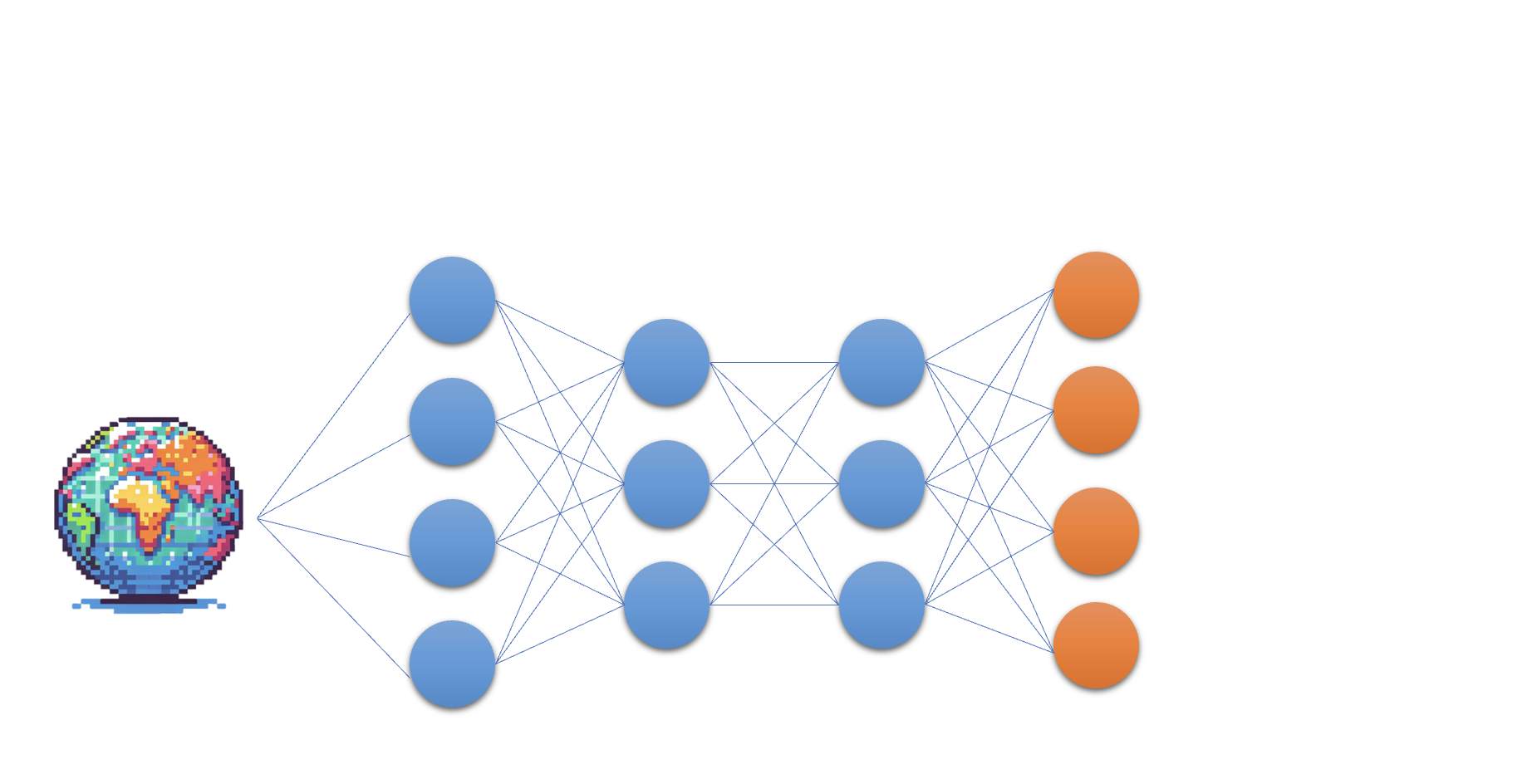
Q-Ağı
- Derin Q Öğrenmenin özünde: bir sinir ağı
Q-Ağı
- Derin Q Öğrenmenin özünde: durumu Q-değerlerine eşleyen bir sinir ağı
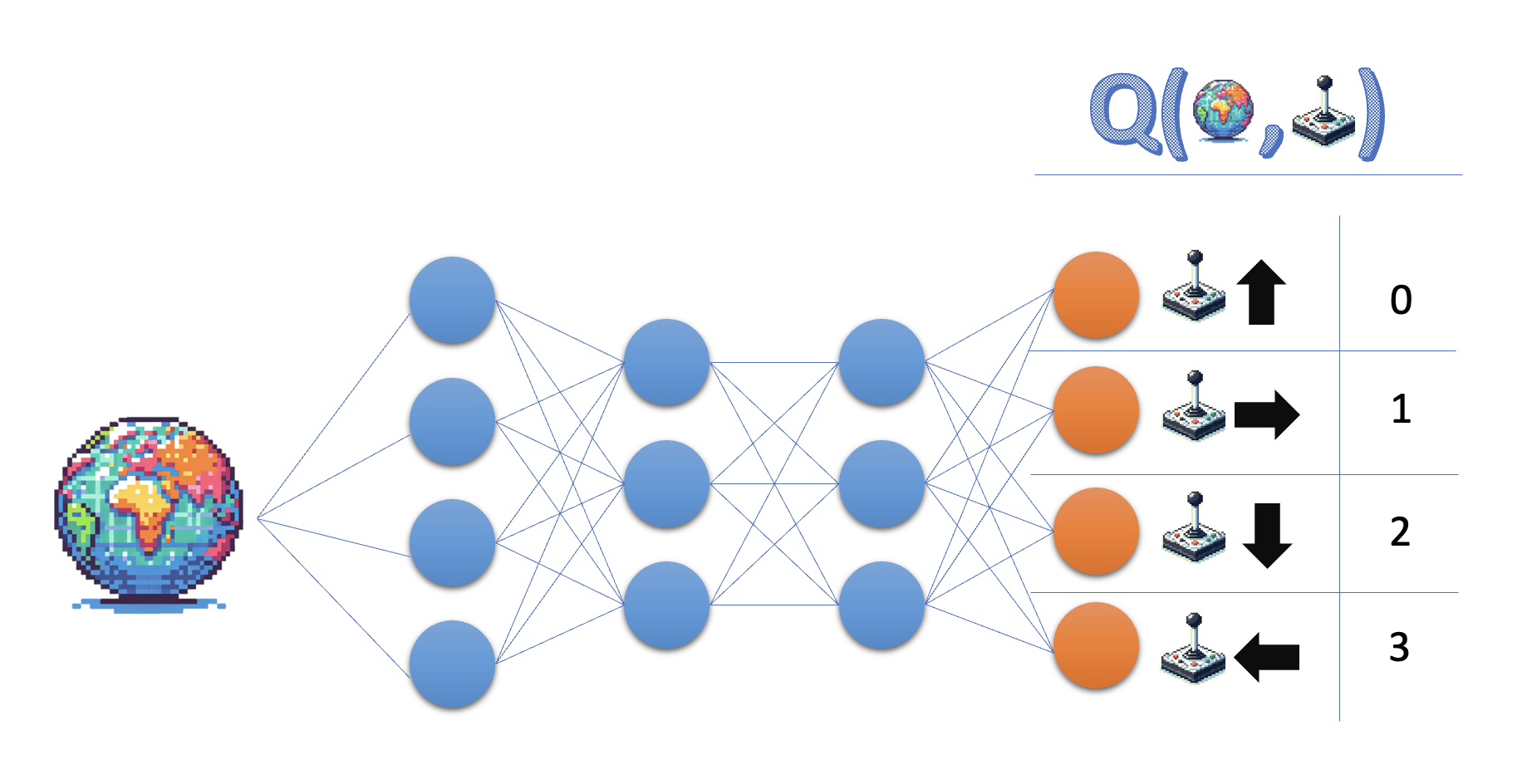
- Eylem-değer fonksiyonunu yaklaştıran ağa “Q-ağı” denir
- Q-ağları, DQN gibi Derin Q Öğrenme algoritmalarında yaygındır

