Deneyim tekrarlamalı DQN
Python ile Deep Reinforcement Learning

Timothée Carayol
Principal Machine Learning Engineer, Komment
Deneyim Tekrarına Giriş

Çift Uçlu Kuyruk (Deque)
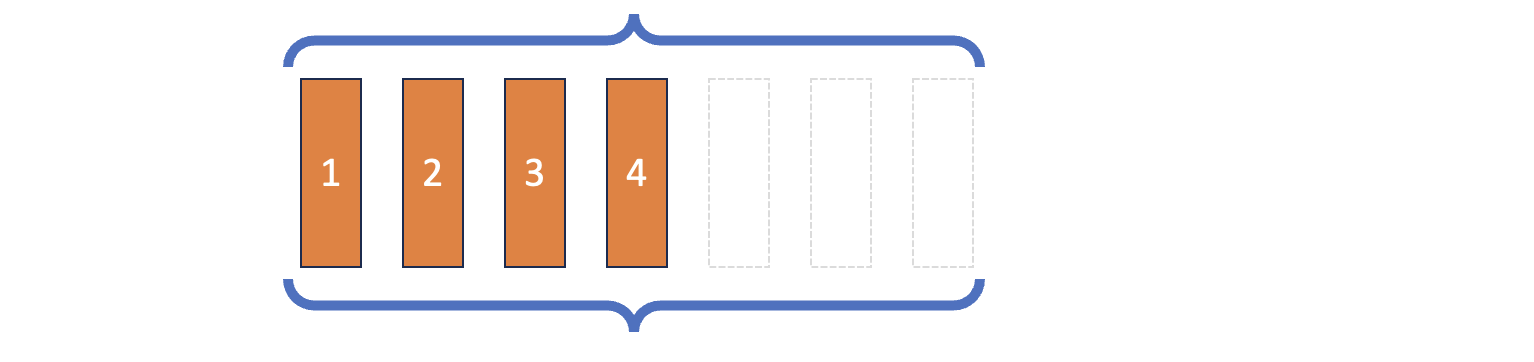
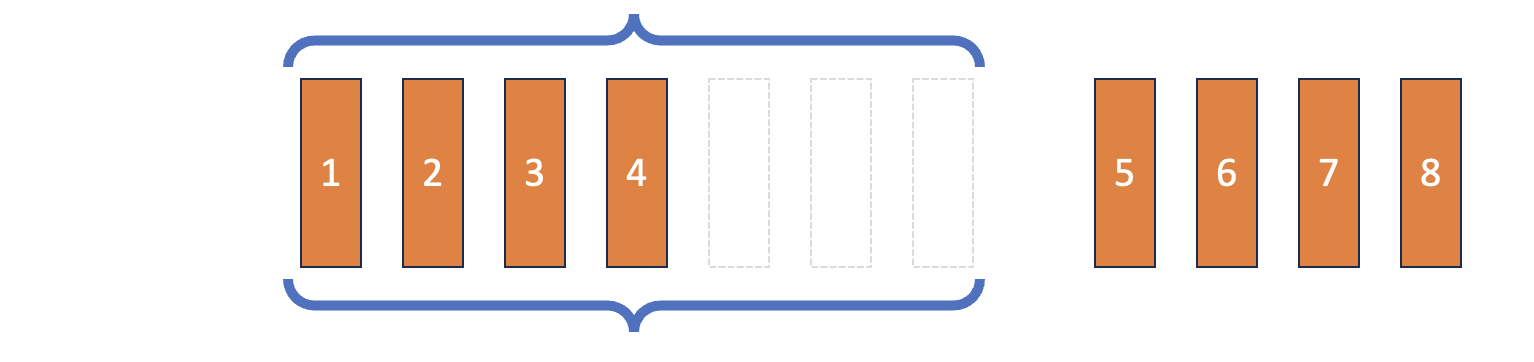
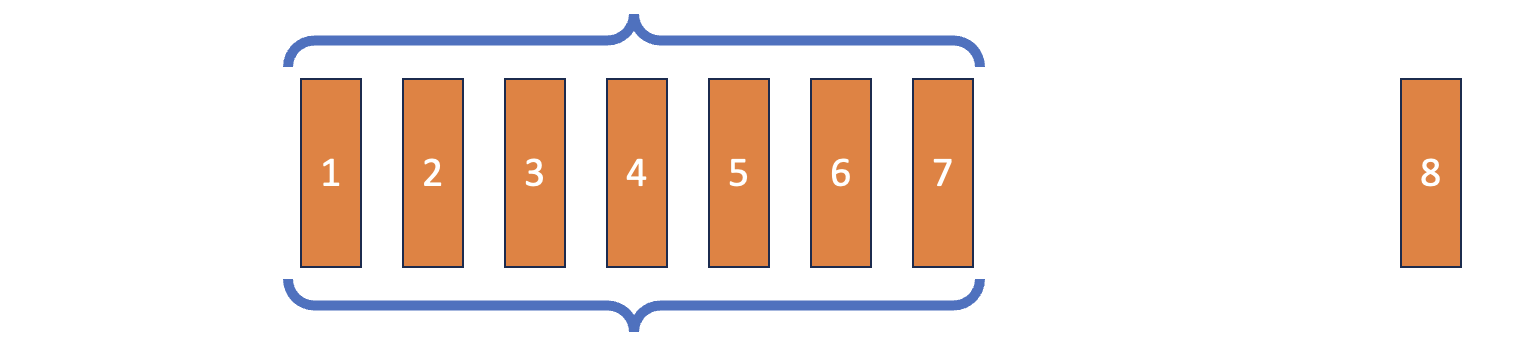
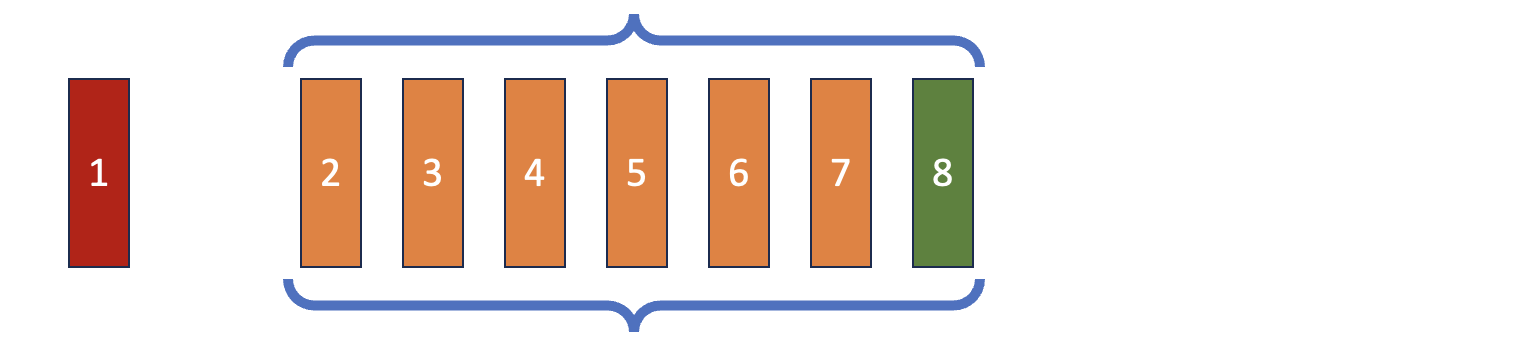
Python ile Deep Reinforcement Learning
Timothée Carayol
Principal Machine Learning Engineer, Komment

