Tam DQN algoritması
Python ile Deep Reinforcement Learning

Timothée Carayol
Principal Machine Learning Engineer, Komment
DQN algoritması


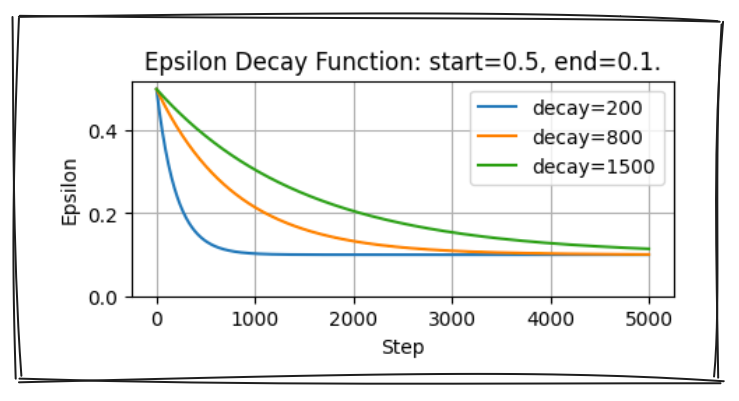
DQN’de epsilon-açgözlülük
- $\varepsilon = end + (start-end) \cdot e^{-\frac{step}{decay}}$
- Olasılık $\varepsilon$ ile rastgele eylem alın
- Olasılık $1 - \varepsilon$ ile en yüksek değerli eylemi alın
Sabit Q-hedefleri

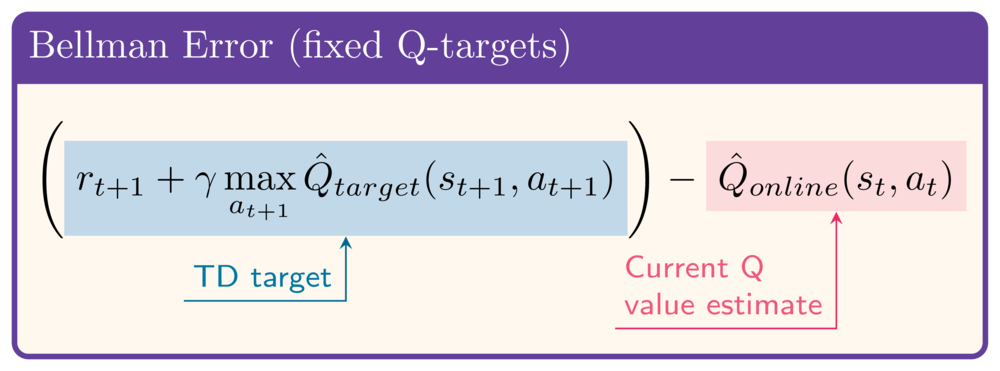
Sabit Q-hedeflerinin uygulanması
- Başta Çevrimiçi Ağ = Hedef Ağ
- Bir ağın state dict’i tüm ağırlıkları içerir:

- Her adımda Hedef Ağın her ağırlığı Çevrimiçi Ağa biraz yaklaşır

