Politika gradyanında yığın (batch) güncellemeleri
Python ile Deep Reinforcement Learning

Timothée Carayol
Principal Machine Learning Engineer, Komment
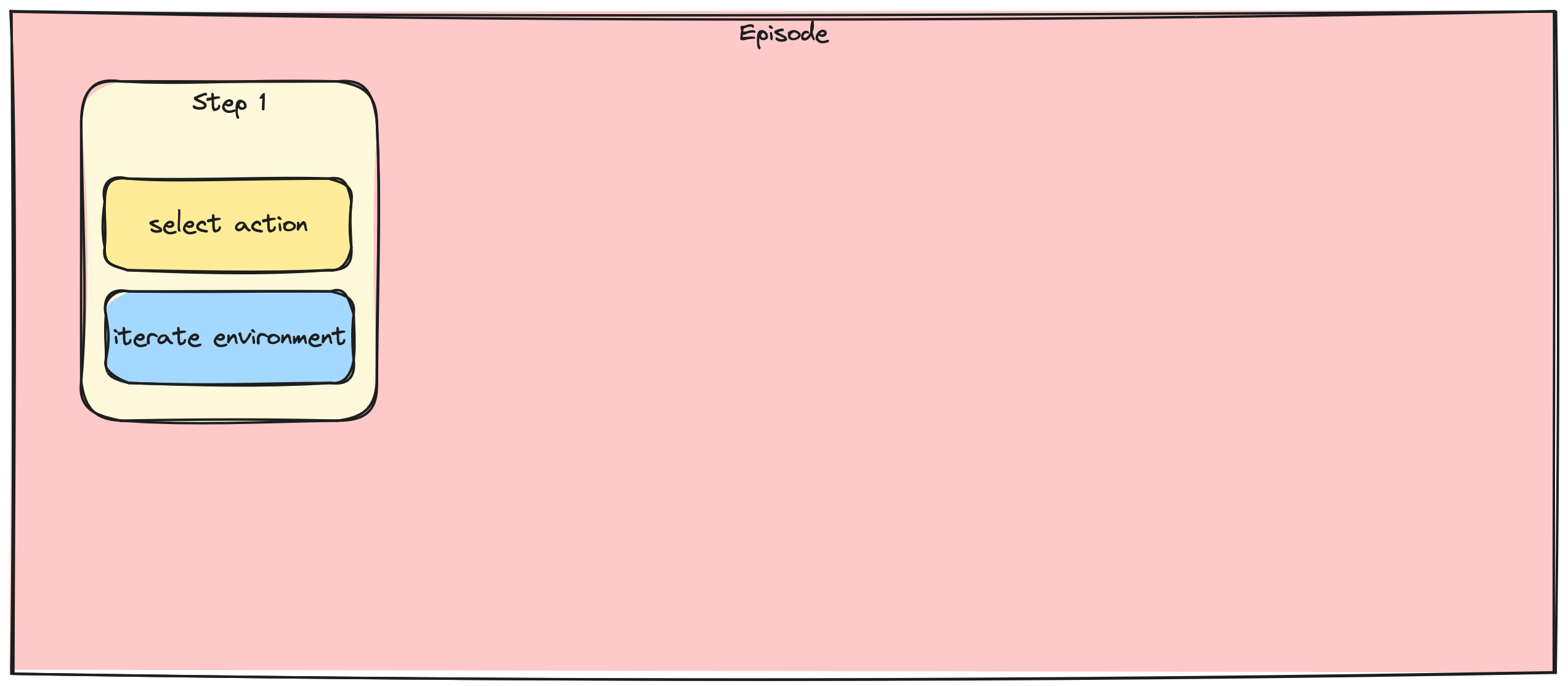
Adım adım ve yığın gradyan güncellemeleri

Adım adım ve yığın gradyan güncellemeleri

Adım adım ve yığın gradyan güncellemeleri
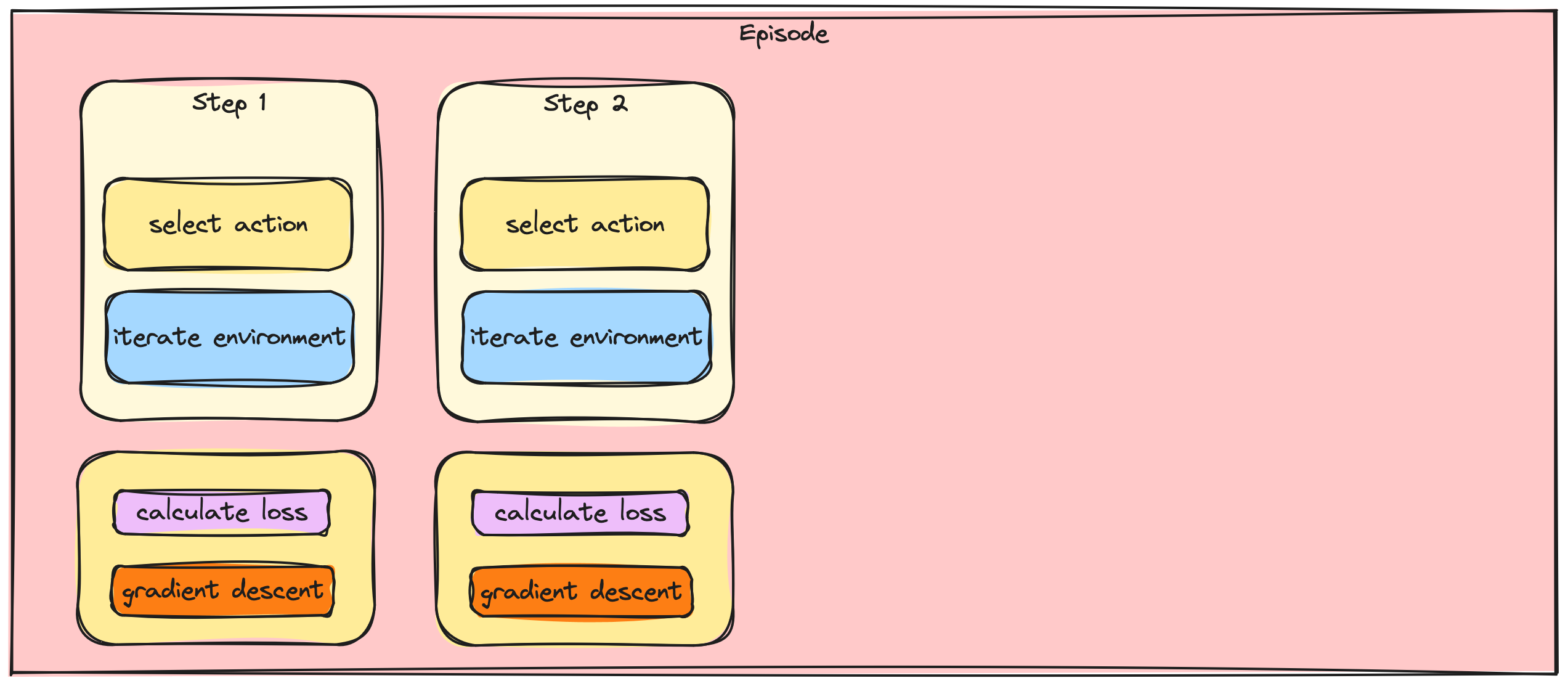
Adım adım ve yığın gradyan güncellemeleri

Adım adım ve yığın gradyan güncellemeleri
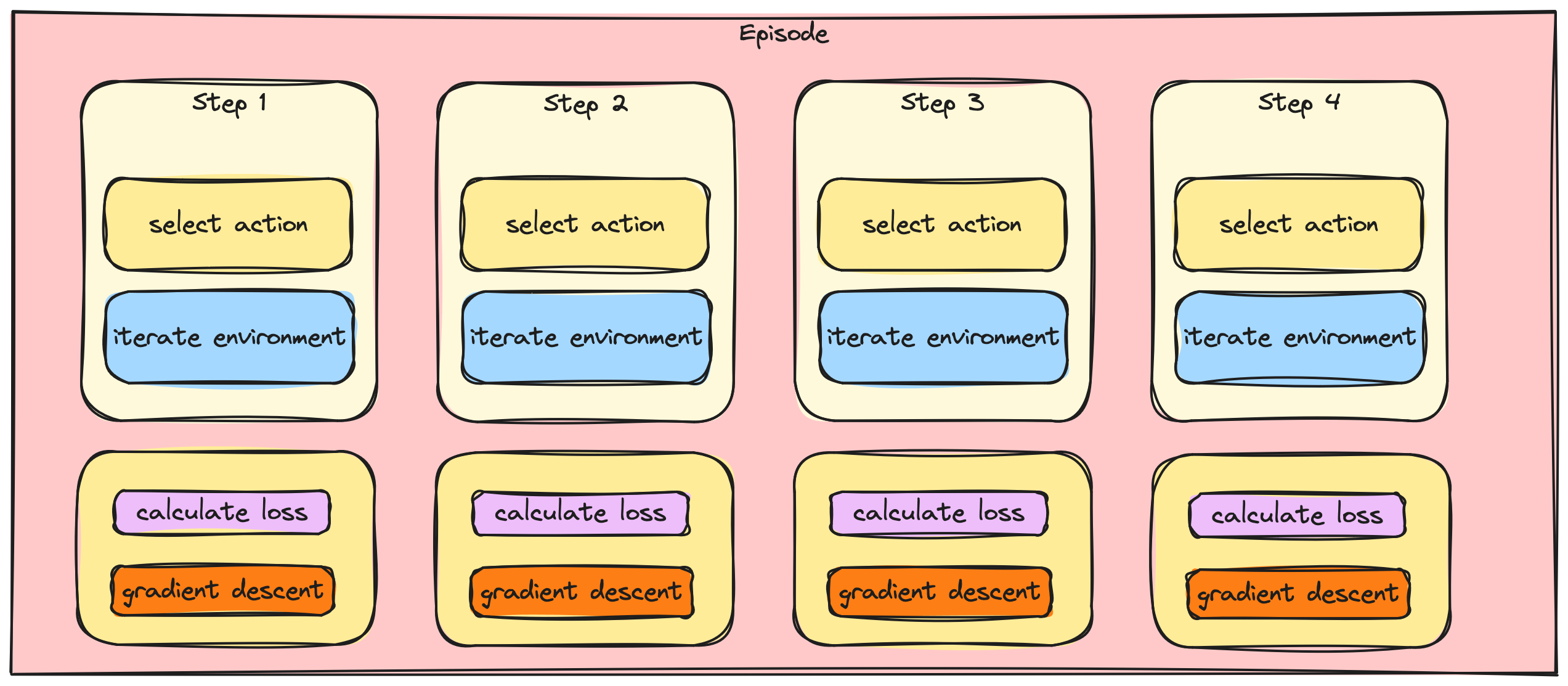
Adım adım ve yığın gradyan güncellemeleri
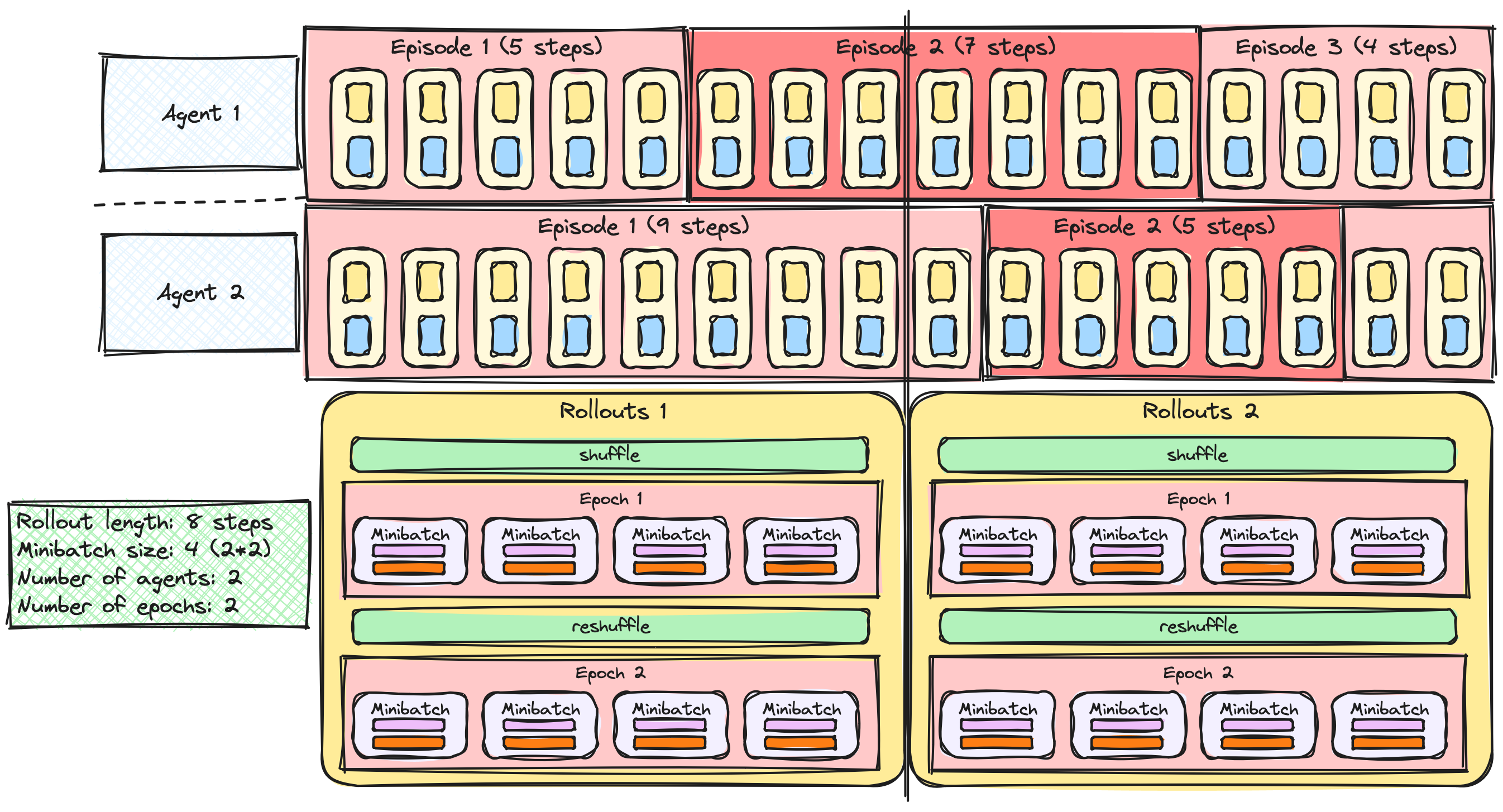
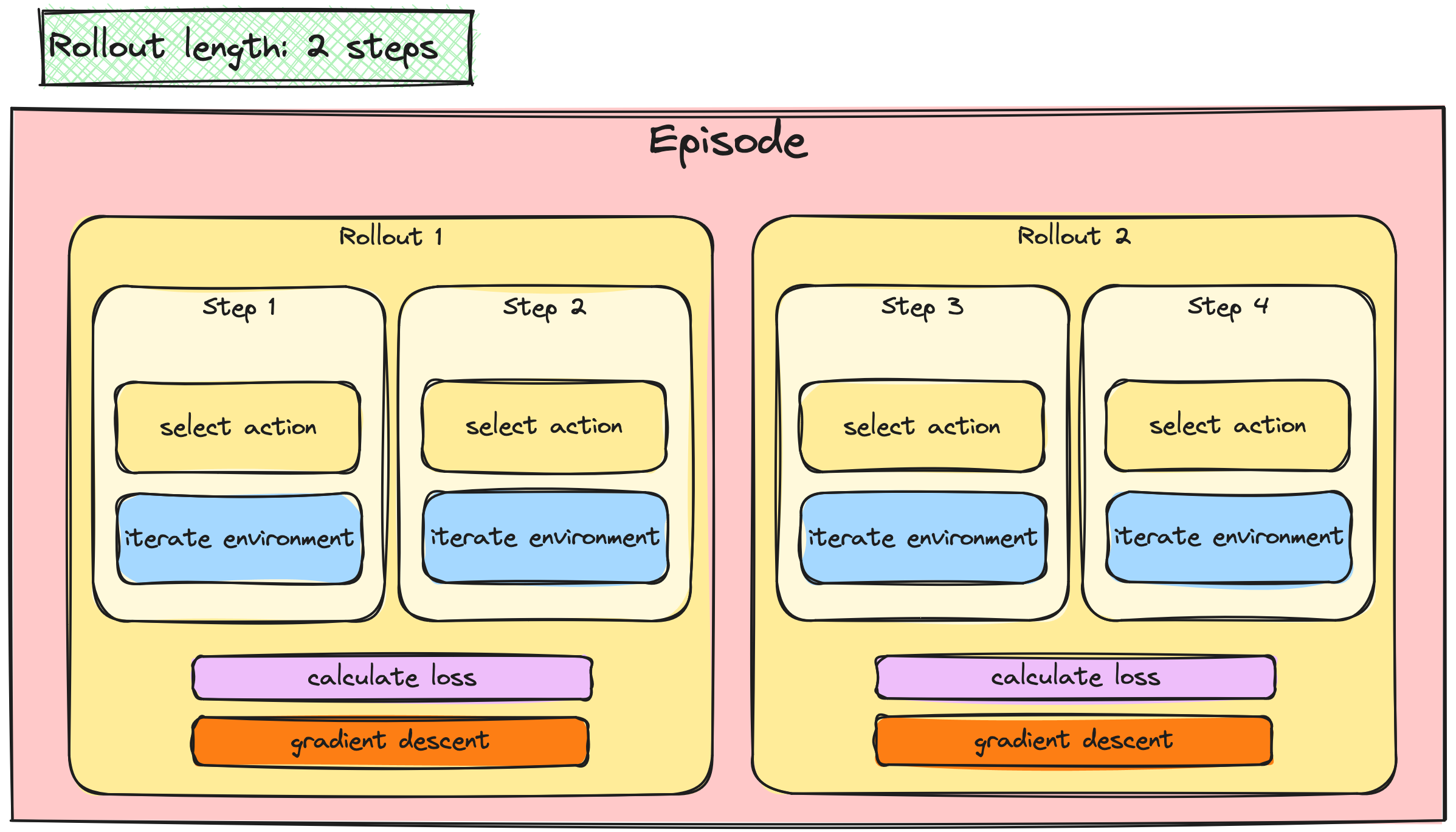
A2C / PPO güncellemelerini yığınlama
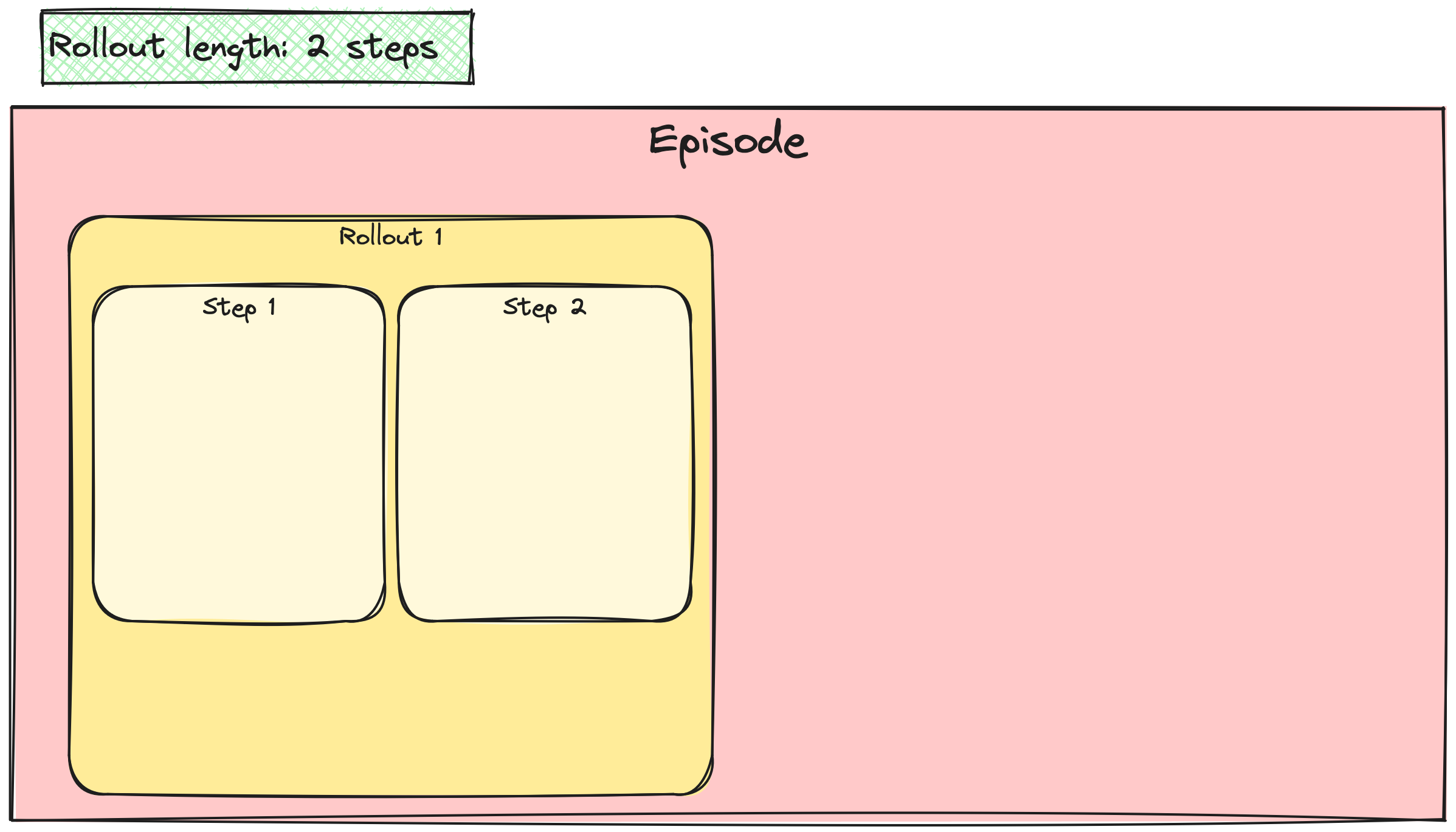
A2C / PPO güncellemelerini yığınlama
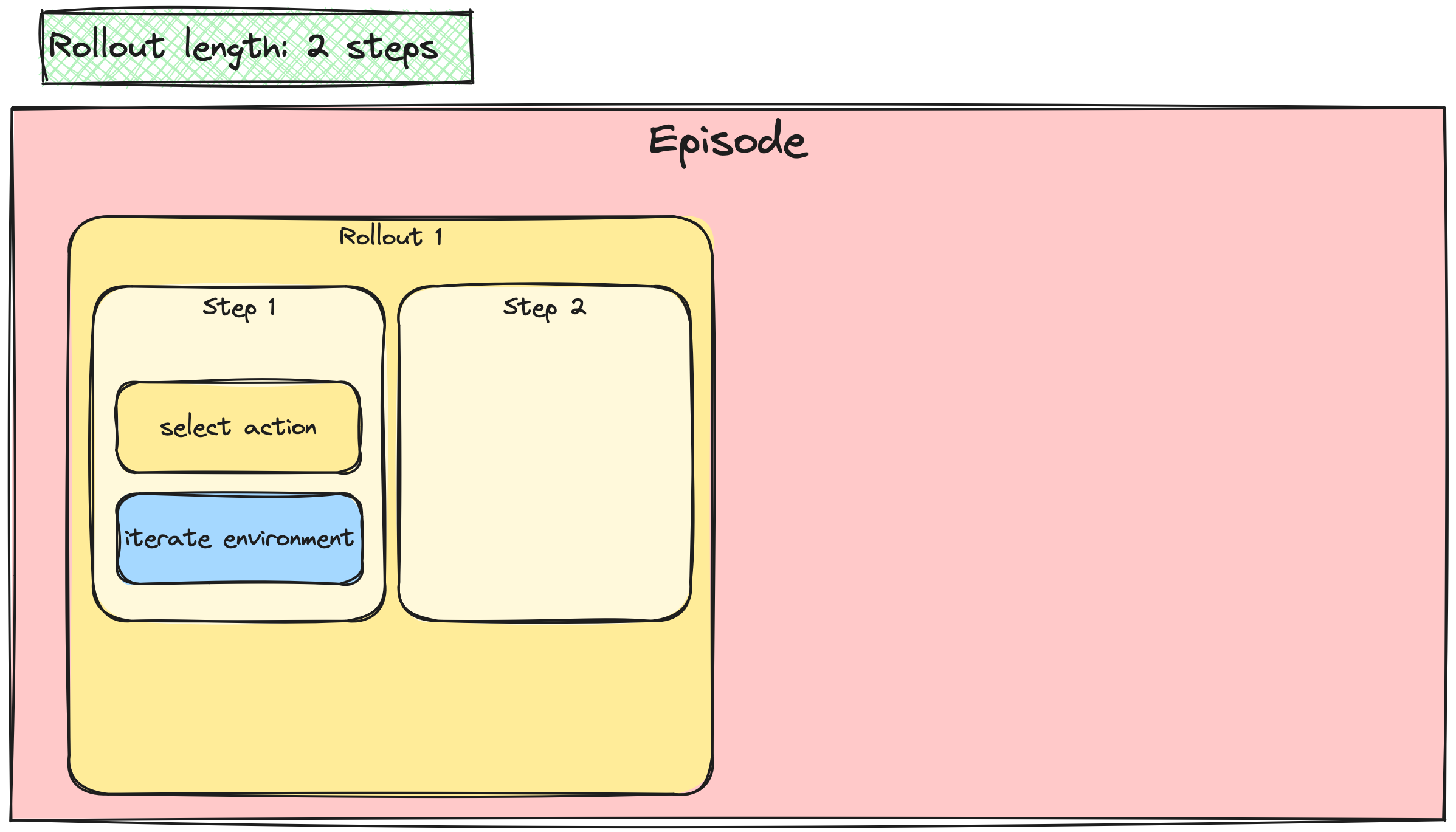
A2C / PPO güncellemelerini yığınlama
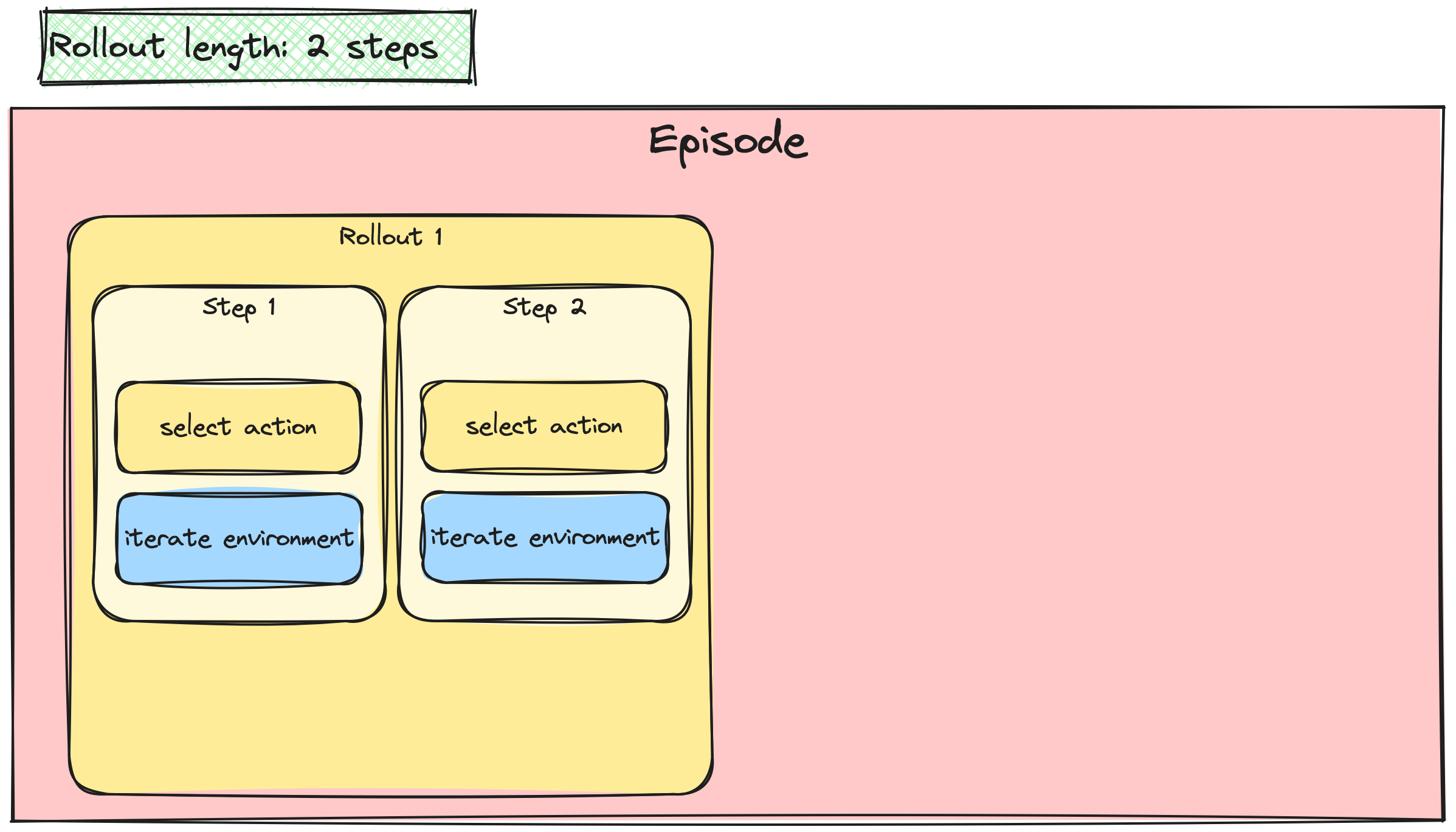
A2C / PPO güncellemelerini yığınlama
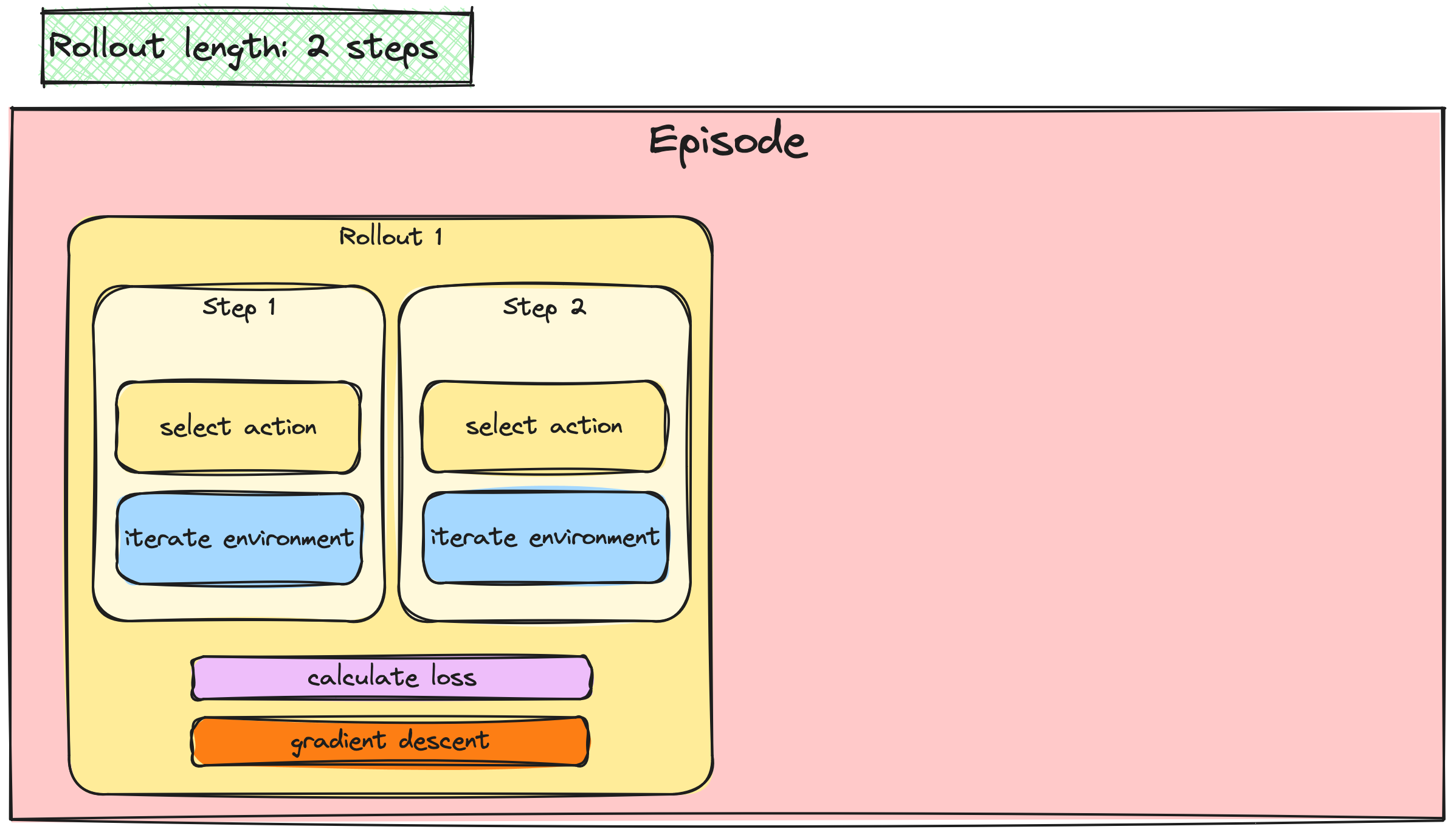
A2C / PPO güncellemelerini yığınlama
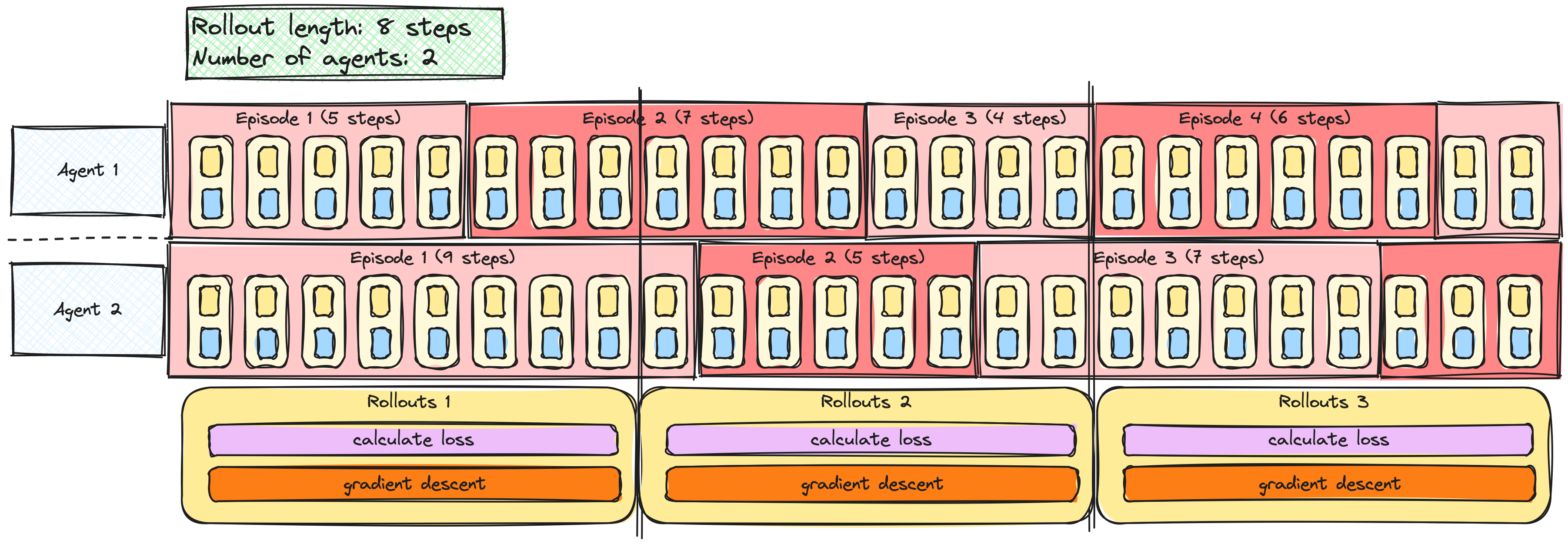
Birden çok ajanla A2C / PPO
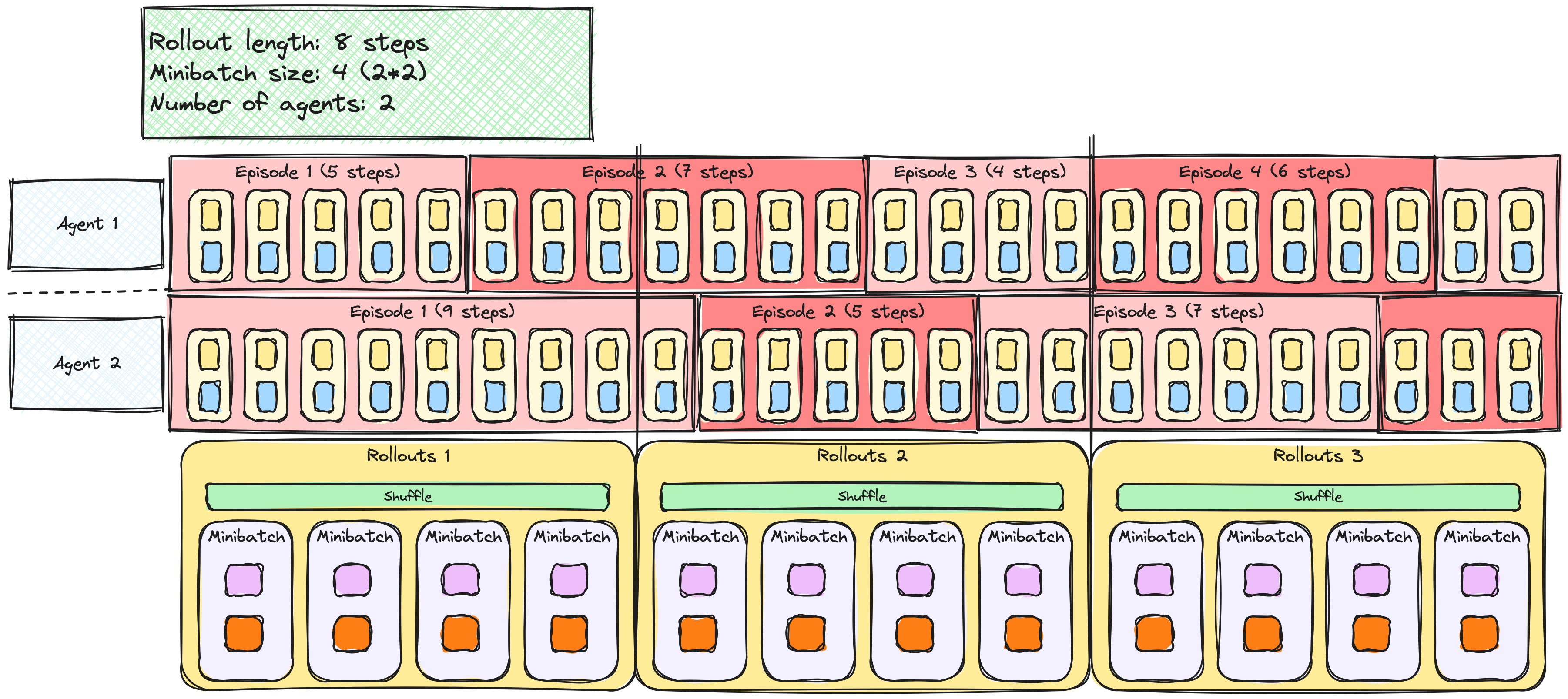
Yuvarlamalar ve mini-yığınlar
Birden çok dönemle PPO