Çift DQN
Python ile Deep Reinforcement Learning

Timothée Carayol
Principal Machine Learning Engineer, Komment
Çift Q-öğrenme
- Q-öğrenme Q-değerlerini fazla tahmin eder, öğrenme verimini düşürür
- Nedeni: maksimize etme yanlılığı
- Çift Q-öğrenme, eylem seçimi ile değer tahminini ayırarak yanlılığı giderir
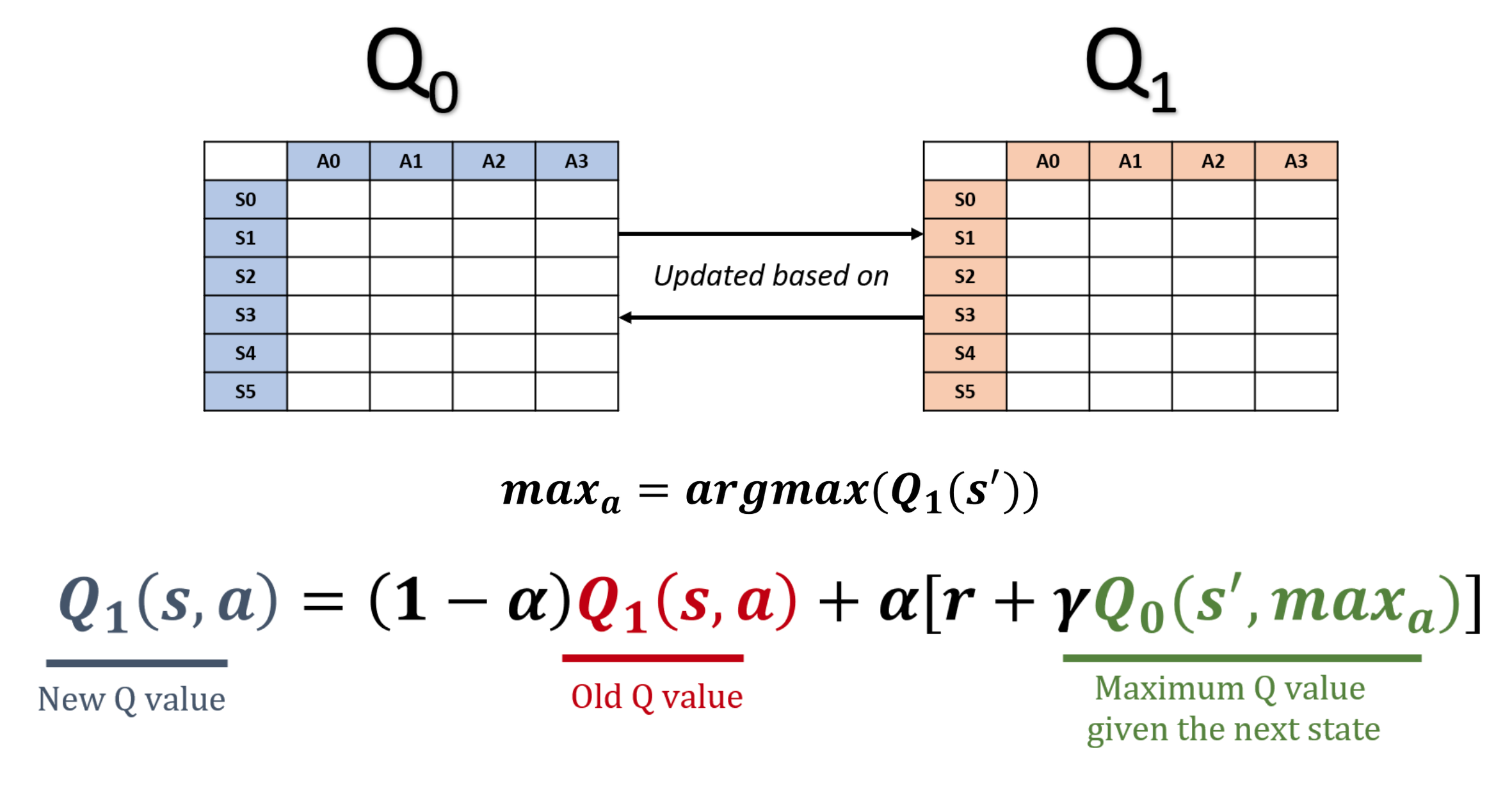
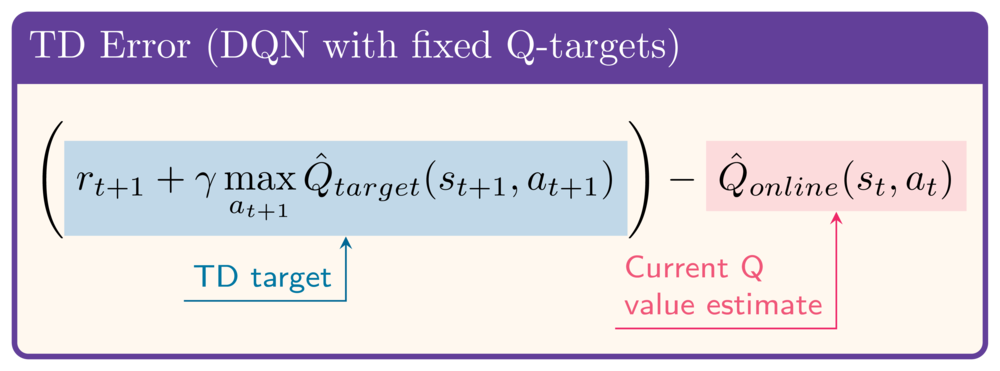
DDQN’in ardındaki fikir

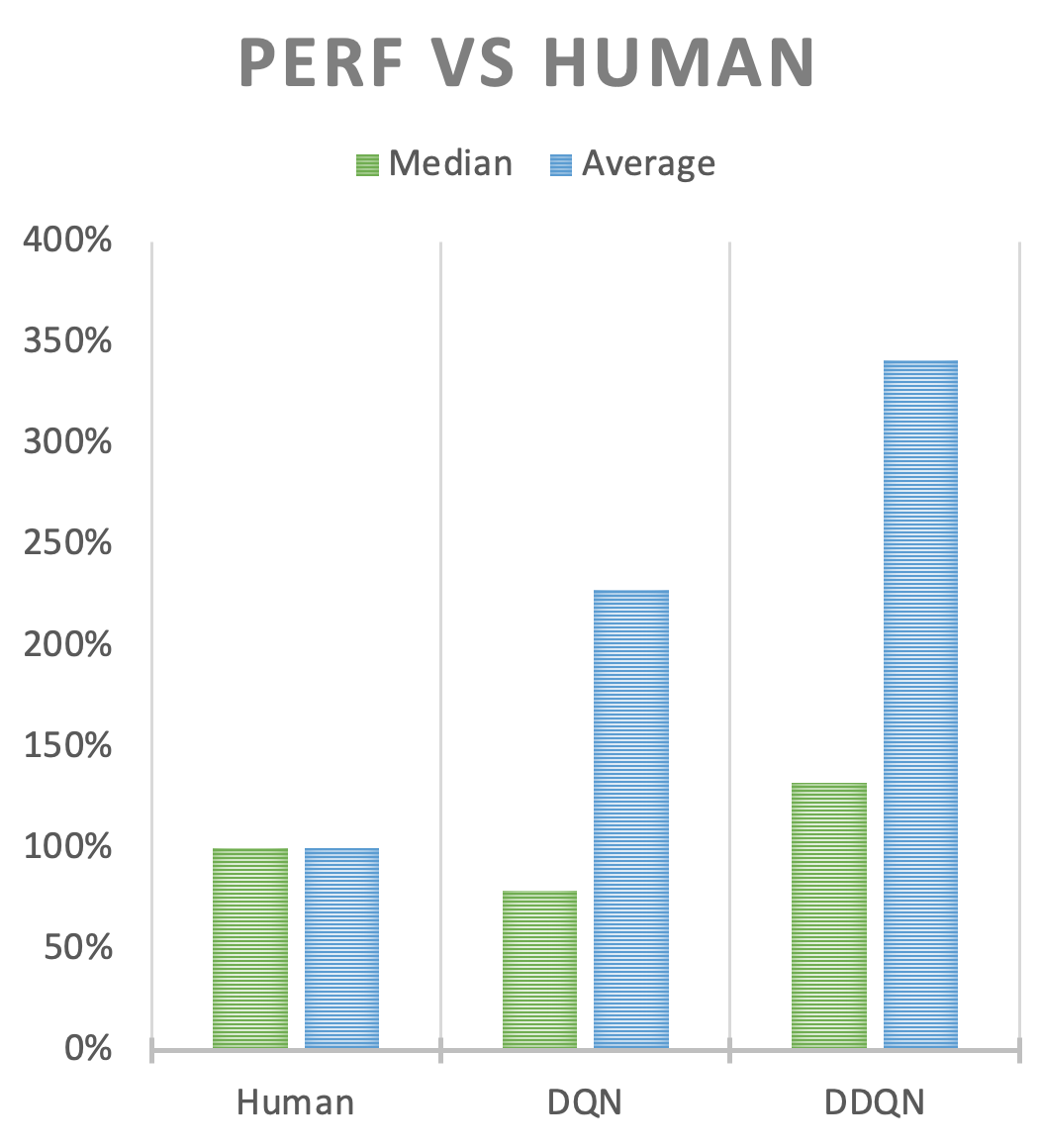
DDQN performansı
1 https://arxiv.org/abs/2303.11634

