Avantajlı Aktör-Kritik
Python ile Deep Reinforcement Learning

Timothée Carayol
Principal Machine Learning Engineer, Komment
Neden aktör-kritik?
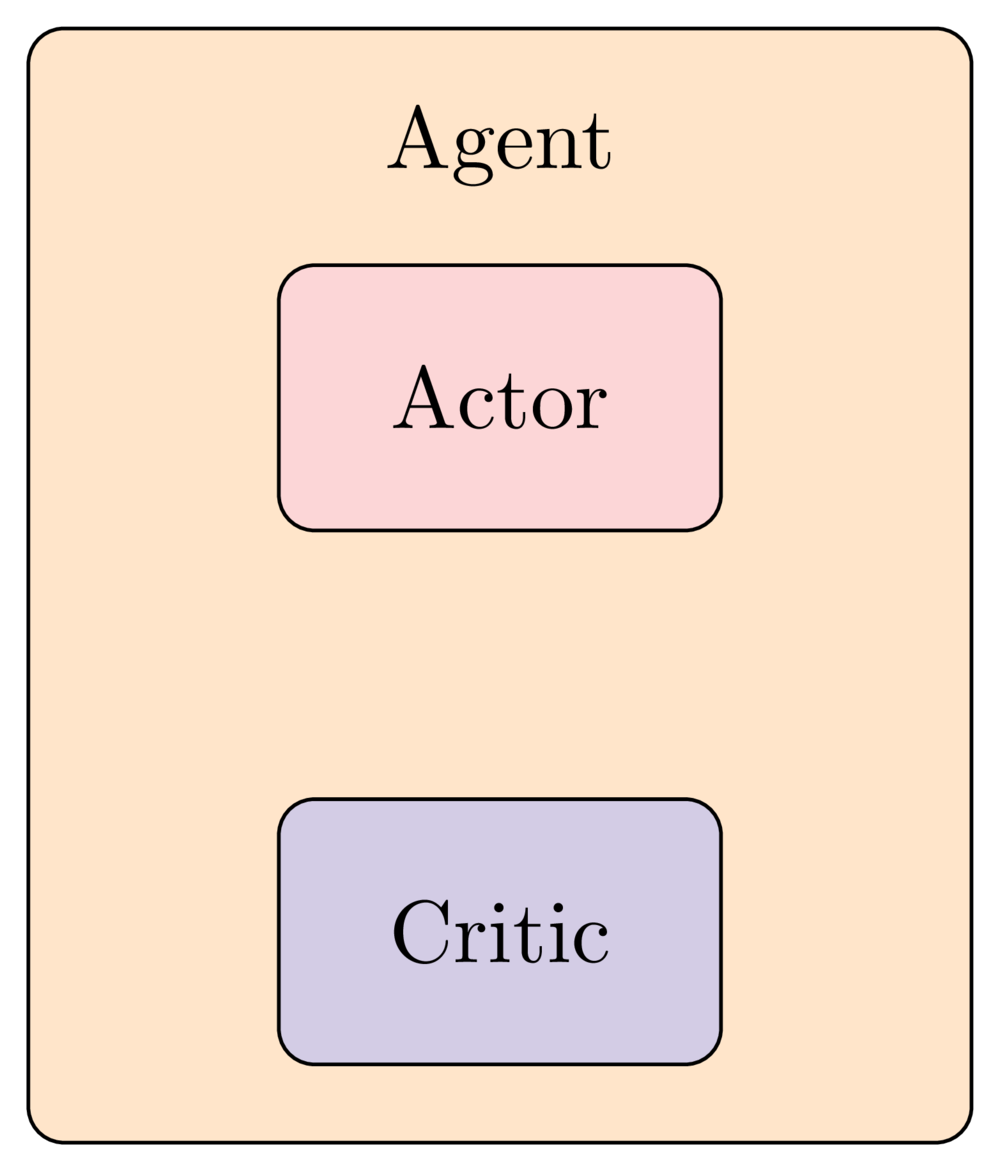
Aktör-Kritik yöntemlerinin sezgisi

Kritik ağı
- Kritik, durum değer fonksiyonunu yaklaştırır
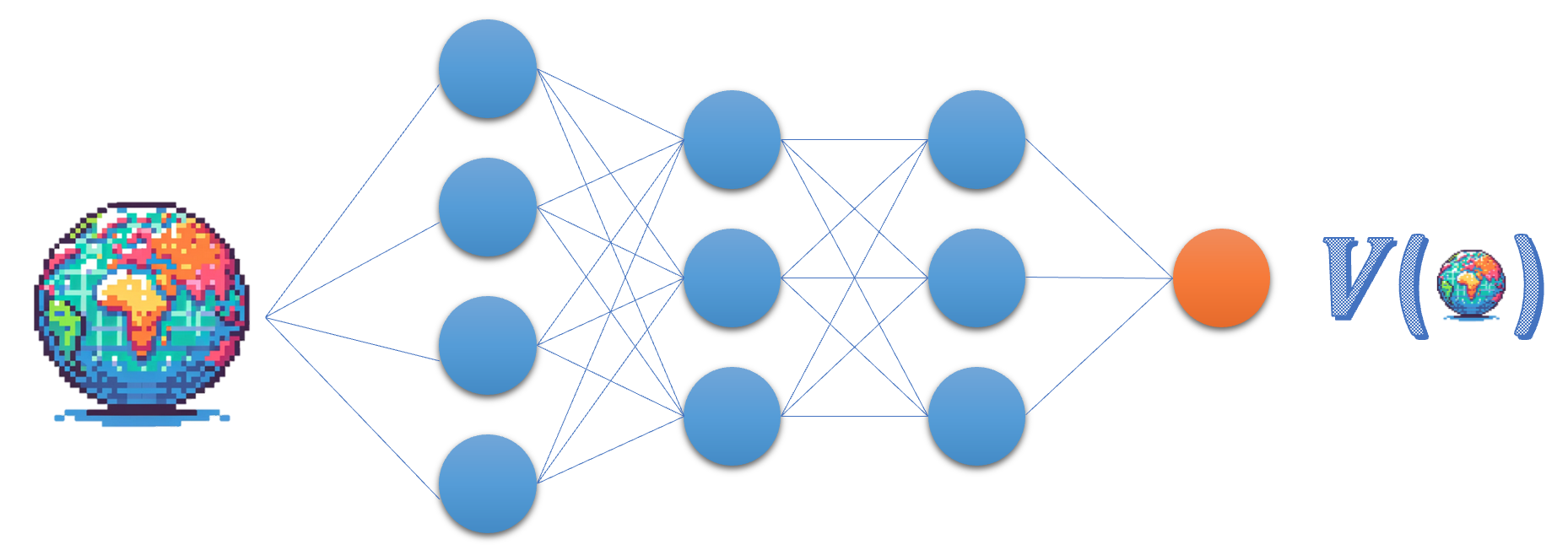
- Eylem $a_t$’yi avantaj veya TD hatasına göre değerlendirir
Aktör-Kritik dinamikleri
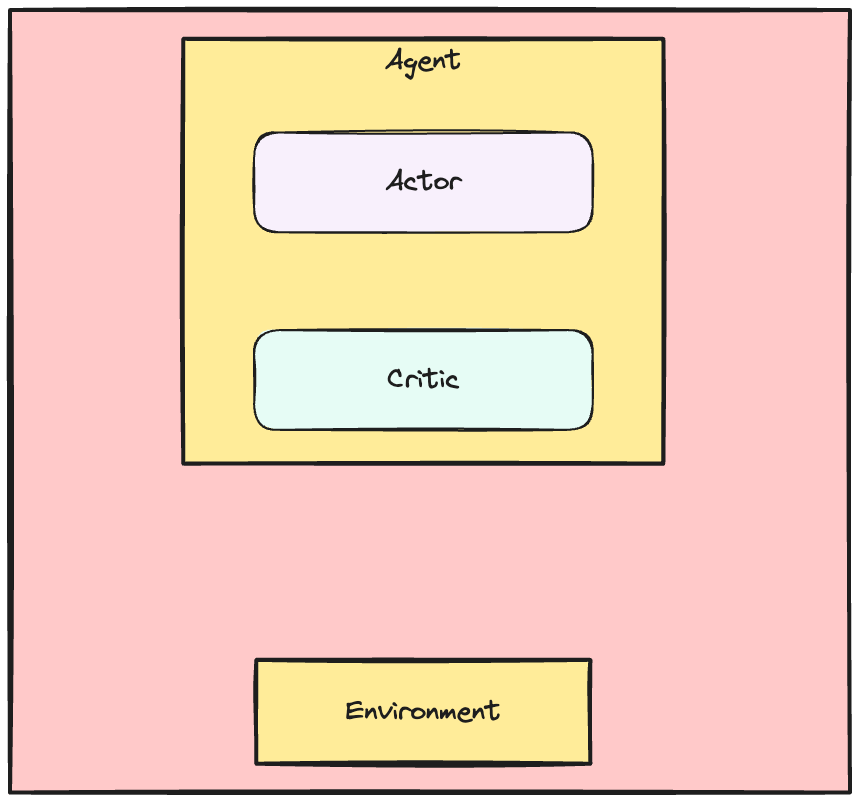
Aktör-Kritik dinamikleri
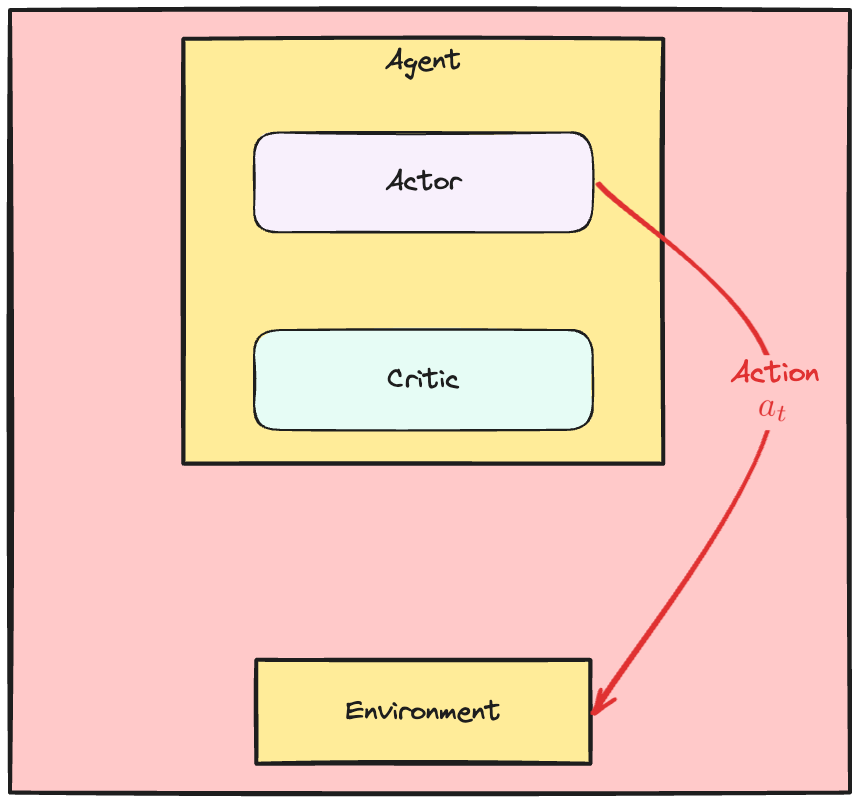
Aktör-Kritik dinamikleri
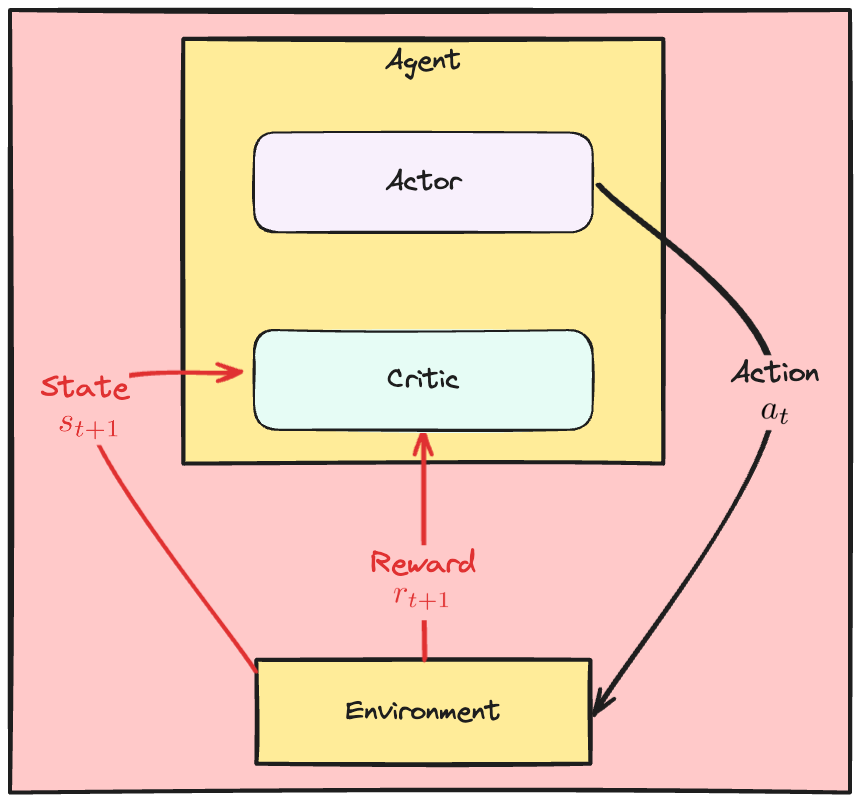
Aktör-Kritik dinamikleri
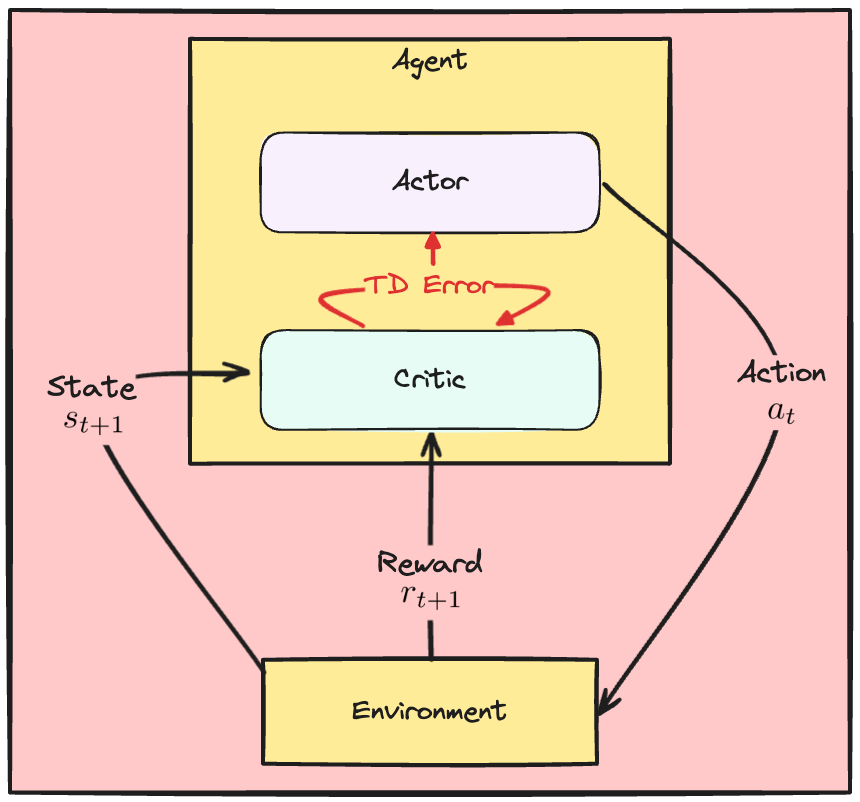
Aktör-Kritik dinamikleri
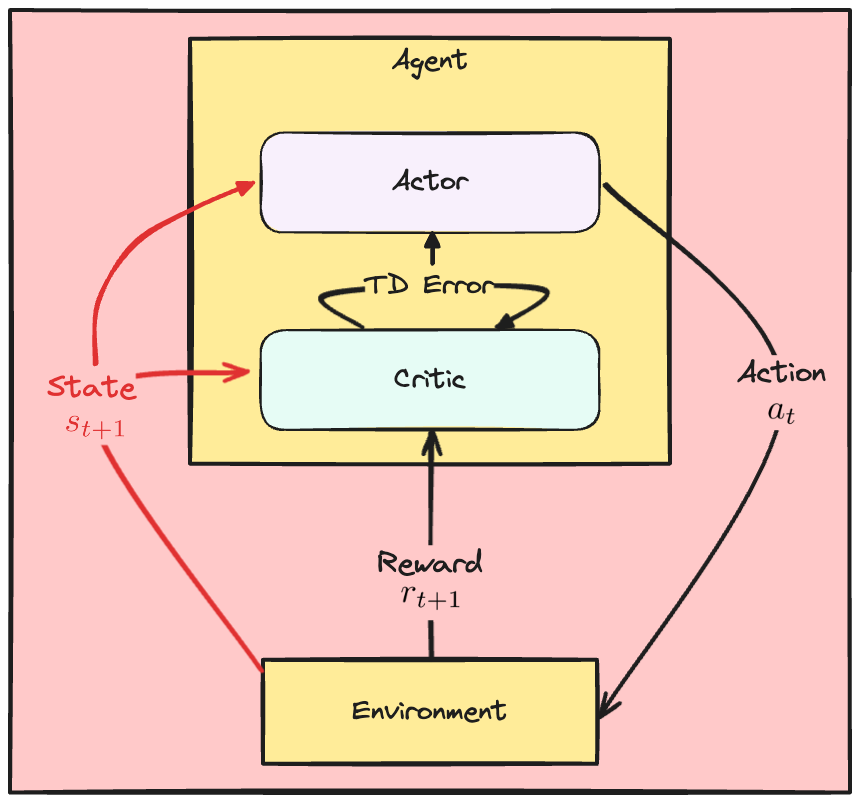
A2C kayıpları
Kritik

- Kritik kaybı: kare TD hatası
Aktör

- TD hatası, kritiğin değerlendirmesini yansıtır
- TD hatası pozitif olan eylemlerin olasılığını artırın

