Politika gradyanı ve REINFORCE
Python ile Deep Reinforcement Learning

Timothée Carayol
Principal Machine Learning Engineer, Komment
DQN ile farklar

Kayıp hesaplama
Politika gradyanı teoremine dönelim:
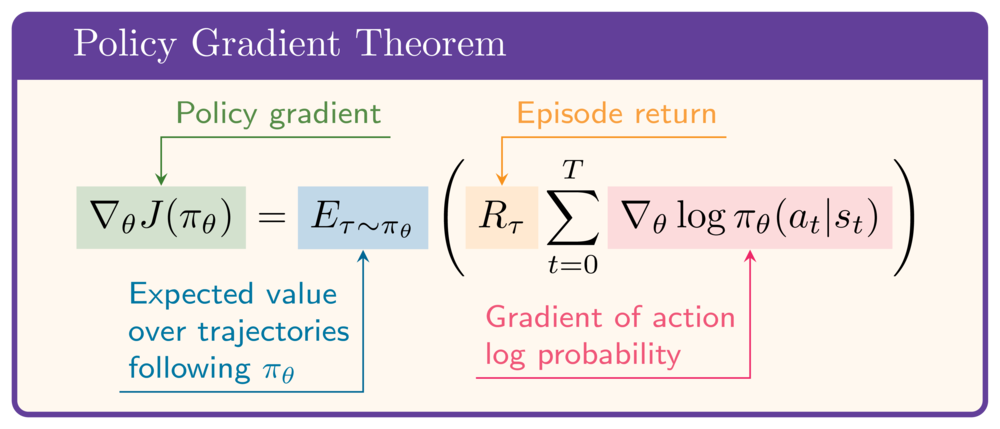

Python'da:
- $R_{\tau}$,
episode_return - $\log\pi_\theta(a_t|s_t)$ vektörü,
episode_log_probs
loss = -episode_return * episode_log_probs.sum()

