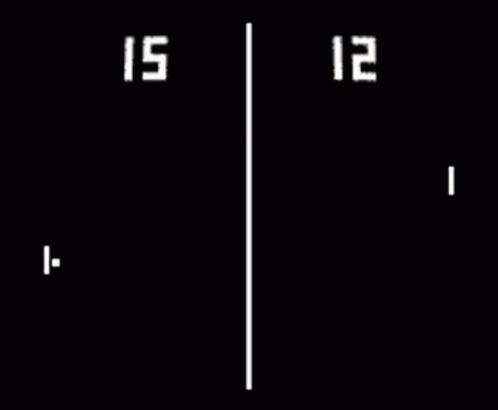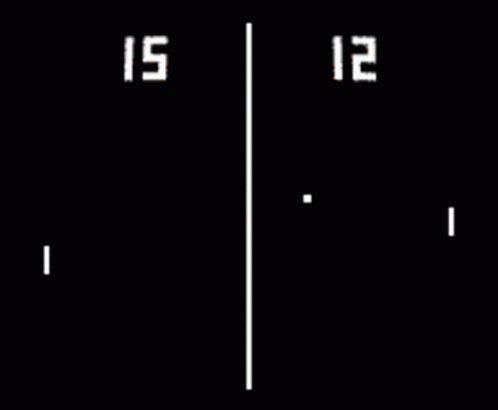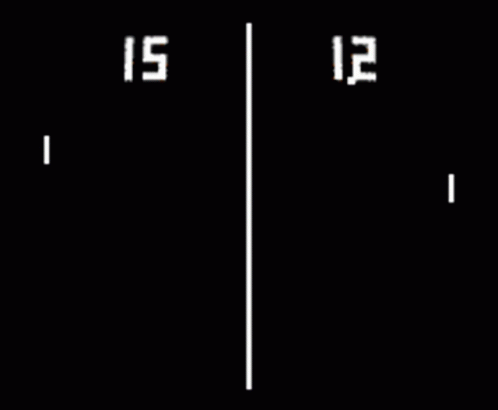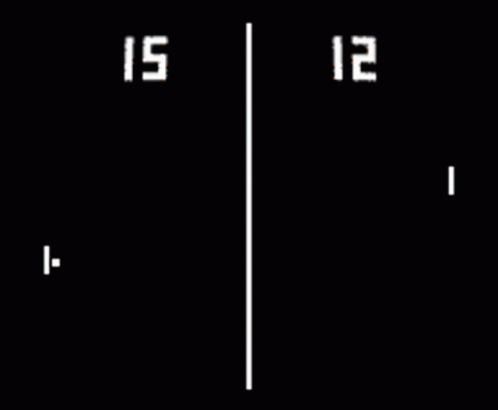
Politika gradyanına giriş
Python ile Deep Reinforcement Learning

Timothée Carayol
Principal Machine Learning Engineer, Komment
DRL'de Politika yöntemlerine giriş
Q-öğrenme:
- Eylem-değer fonksiyonu Q'yu öğrenir
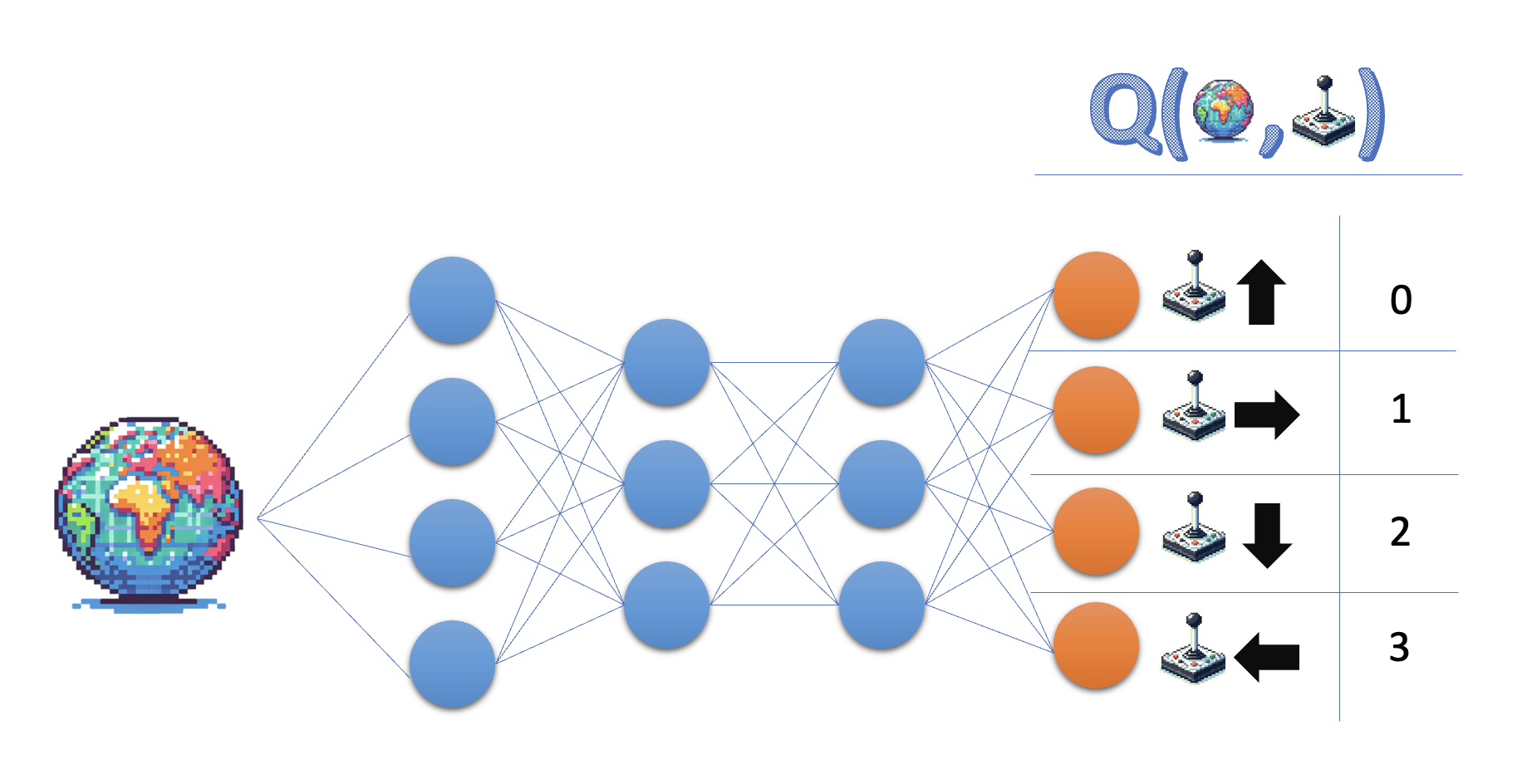
- Politika: en yüksek değere sahip eylemi seçer
Politika öğrenme:
- Politikayı doğrudan öğrenir
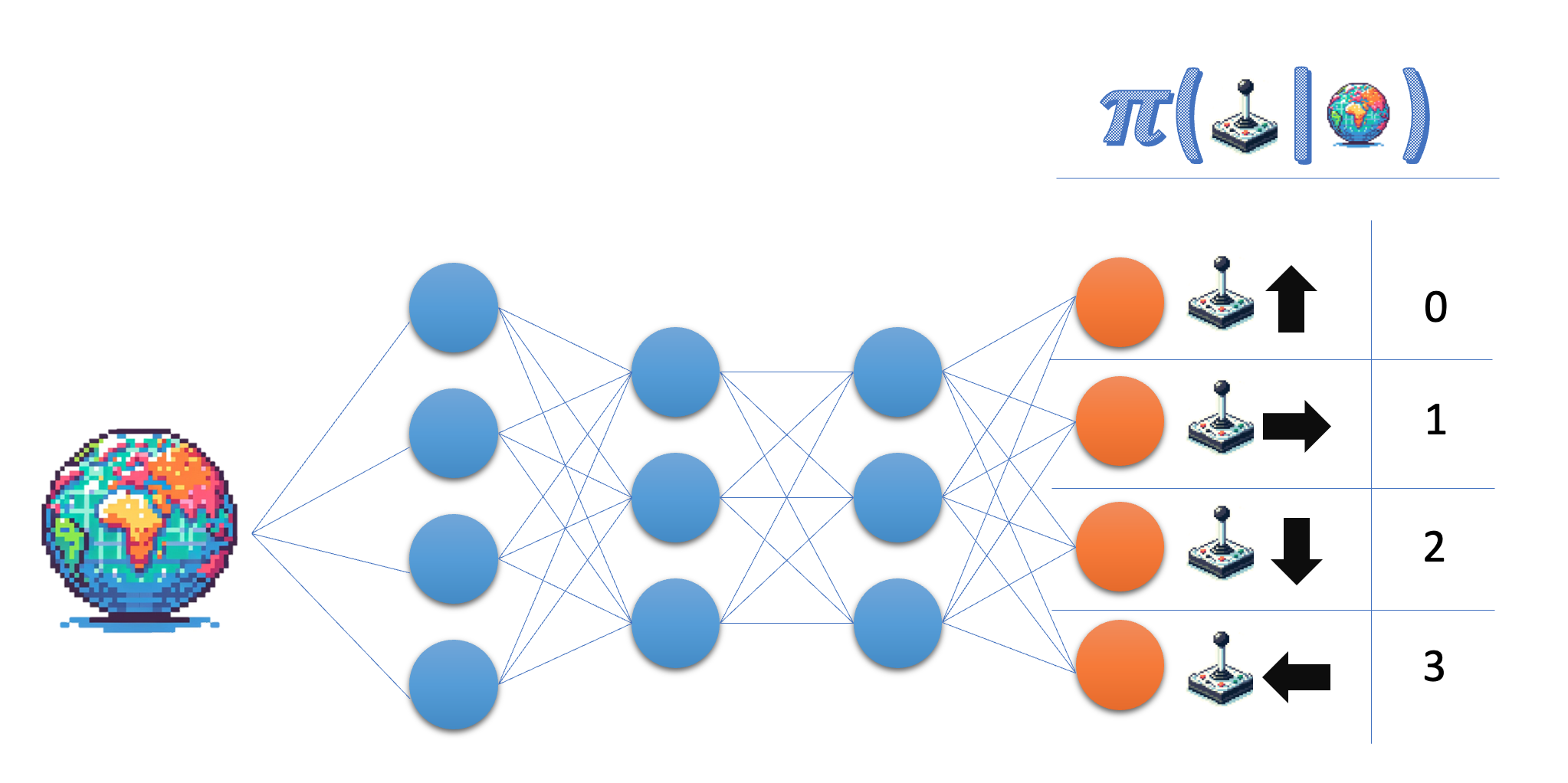
Politika ağı (ayrık eylemler)
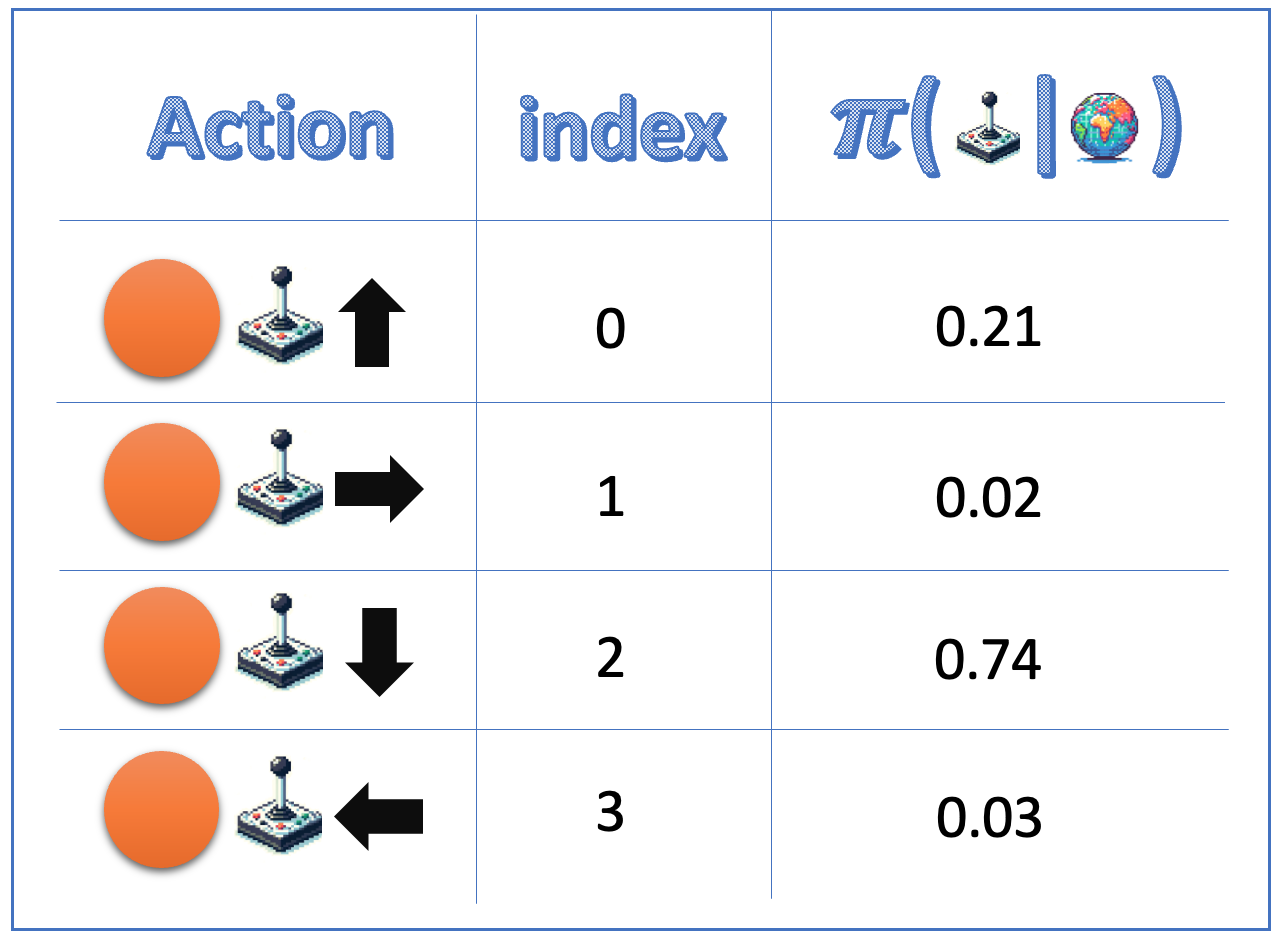
action_dist = ( torch.distributions.Categorical(action_probs))action = action_dist.sample()
Amaç fonksiyonu
Politika beklenen getiriyi eniyilemelidir
- Ajanın $\pi_\theta$'yı izlediğini varsayalım
- Politika parametresi $\theta$ eniyilenir
Amaç fonksiyonu:

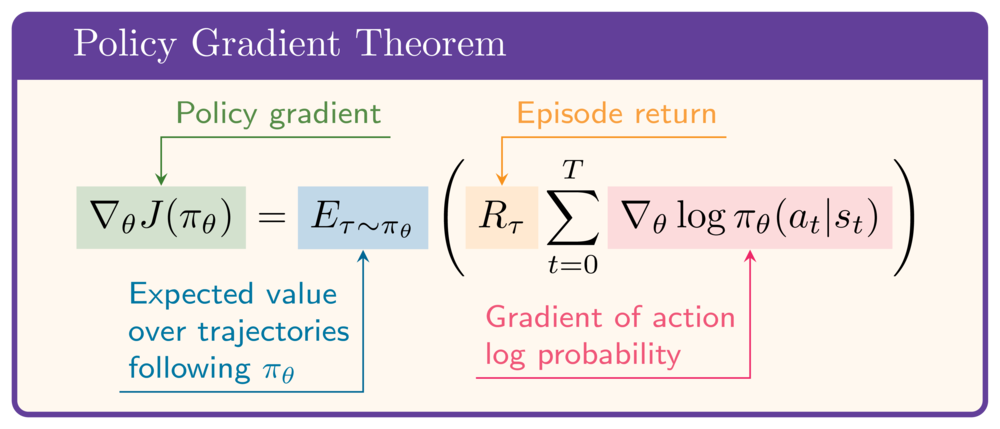
- $J$'yi eniyilemek için: $\theta$'ya göre gradyan gerekir:
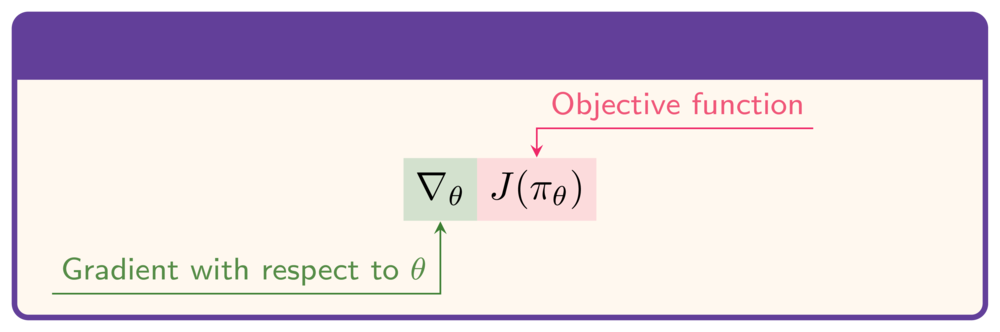
Amaç fonksiyonu
Politika beklenen getiriyi eniyilemelidir
- Ajanın $\pi_\theta$'yı izlediğini varsayalım
- Politika parametresi $\theta$ eniyilenir
Amaç fonksiyonu:
- $J$'yi eniyilemek için: $\theta$'ya göre gradyan gerekir:
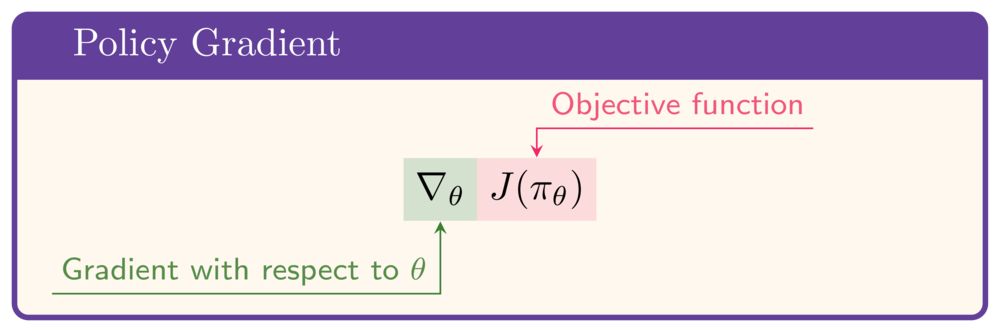
Politika gradyanı teoremi
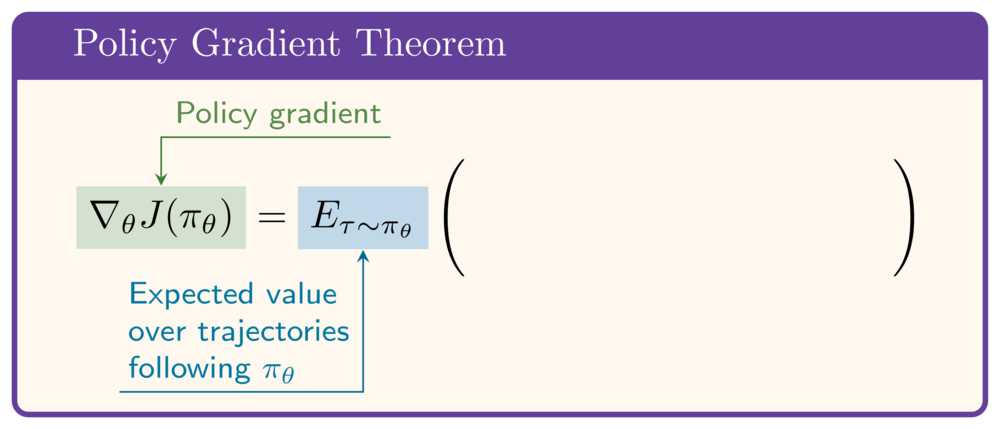
Politika gradyanı teoremi
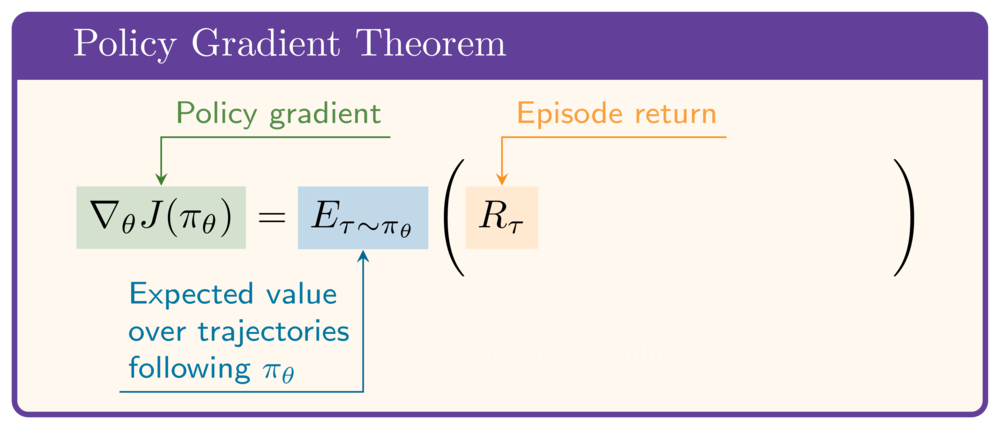
Politika gradyanı teoremi