Yakınsal politika optimizasyonu
Python ile Deep Reinforcement Learning

Timothée Carayol
Principal Machine Learning Engineer, Komment
A2C
- A2C politika güncellemeleri:
- Oynak tahminlere dayalı
- Büyük ve dengesiz olabilir
- Performansa zarar verebilir

PPO
- PPO, her politika güncellemesinin boyutuna sınır koyar
- Kararlılığı artırır

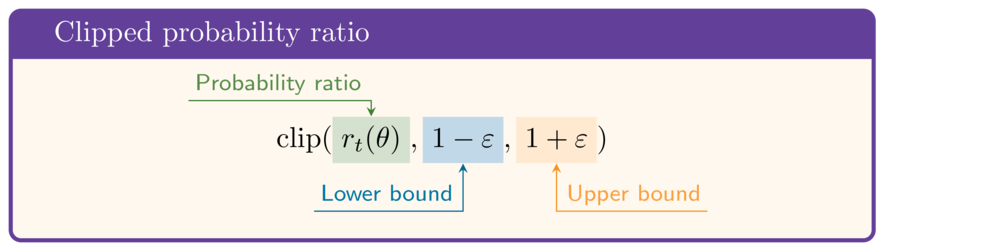
Olasılık oranı
- PPO’nun ana yeniliği: yeni bir amaç fonksiyonu
- Özünde:

- $\theta$ ile eylem $a_t$, $\theta_{old}$’a kıyasla ne kadar daha olası?
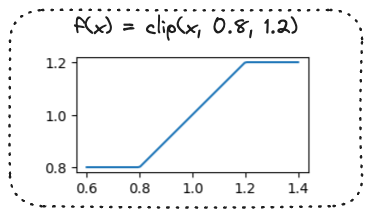
Olasılık oranını kırpmak
- Clip işlevi:
PPO amaç fonksiyonu

surr1 = ratio * td_error.detach()surr2 = clipped_ratio * td_error.detach()objective = torch.min(surr1, surr2)
- Kırpılmış oranla vekil:
$$\mathrm{clip}(r_t(\theta),1-\varepsilon,1+\varepsilon)\hat{A}$$
- PPO kırpılmış vekil amaç fonksiyonu:

- A2C’den daha kararlı

