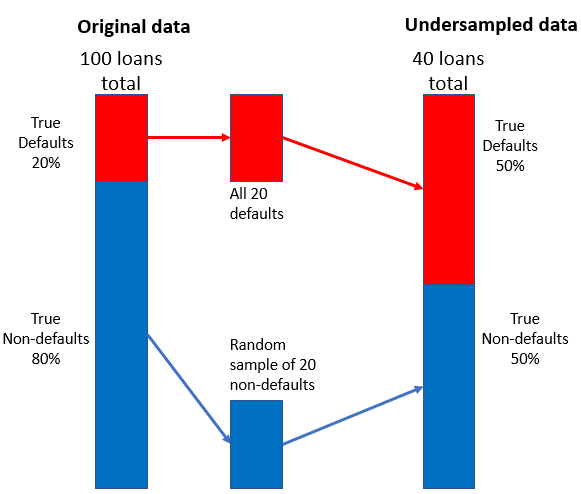
Kredi verilerinde sınıf dengesizliği
Python ile Kredi Riski Modellemesi

Michael Crabtree
Data Scientist, Ford Motor Company
Model kayıp fonksiyonu
xgboost’taki Artırılmış Karar Ağaçları log-kayıp kayıp fonksiyonu kullanır- Amaç bu değeri en aza indirmektir
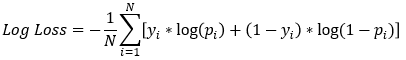
| Gerçek kredi durumu | Tahmin olasılığı | Log Kayıp |
|---|---|---|
| 1 | 0.1 | 2.3 |
| 0 | 0.9 | 2.3 |
- Hatalı tahmin edilen bir temerrüt daha büyük finansal etki yaratır
Az örnekleme stratejisi
- Temerrüt dışı küçük bir rastgele örneklemi temerrütlerle birleştirin