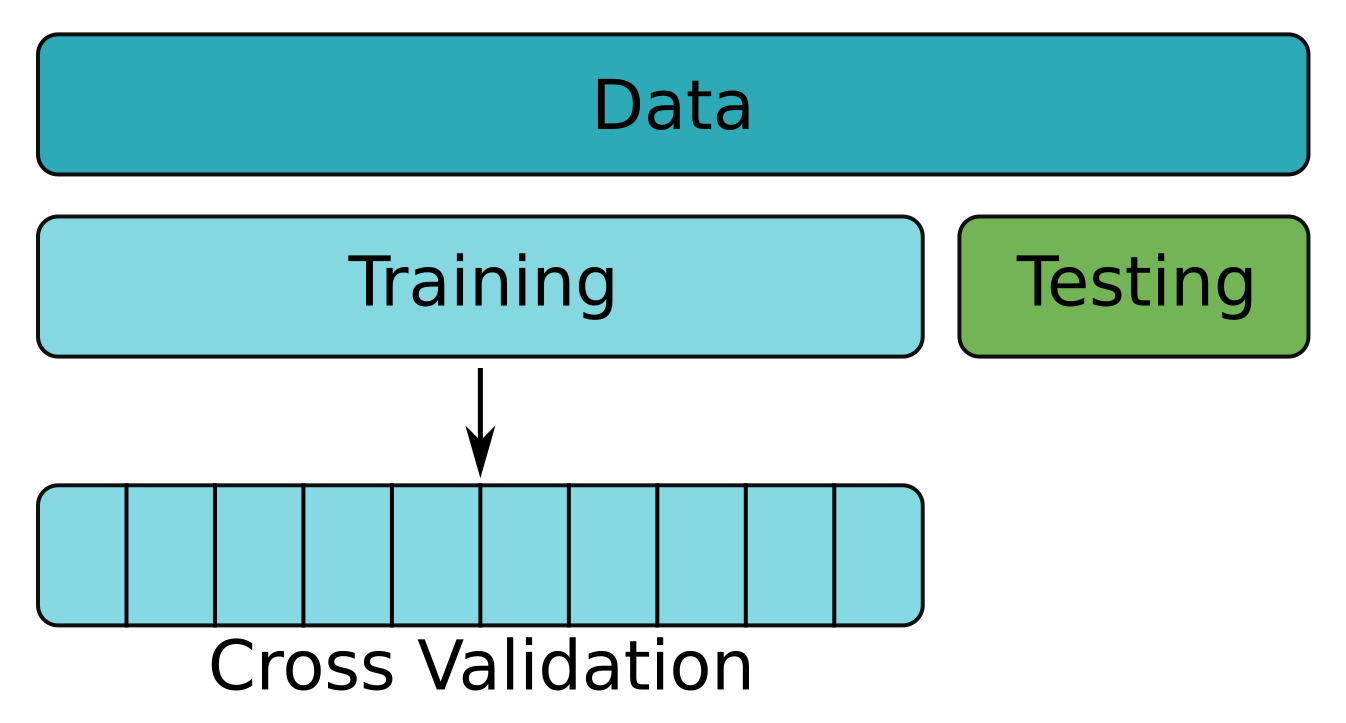
Çapraz Doğrulama
PySpark ile Machine Learning

Andrew Collier
Data Scientist, Fathom Data


Kat üstüne kat - ilk kat

Kat üstüne kat - ikinci kat
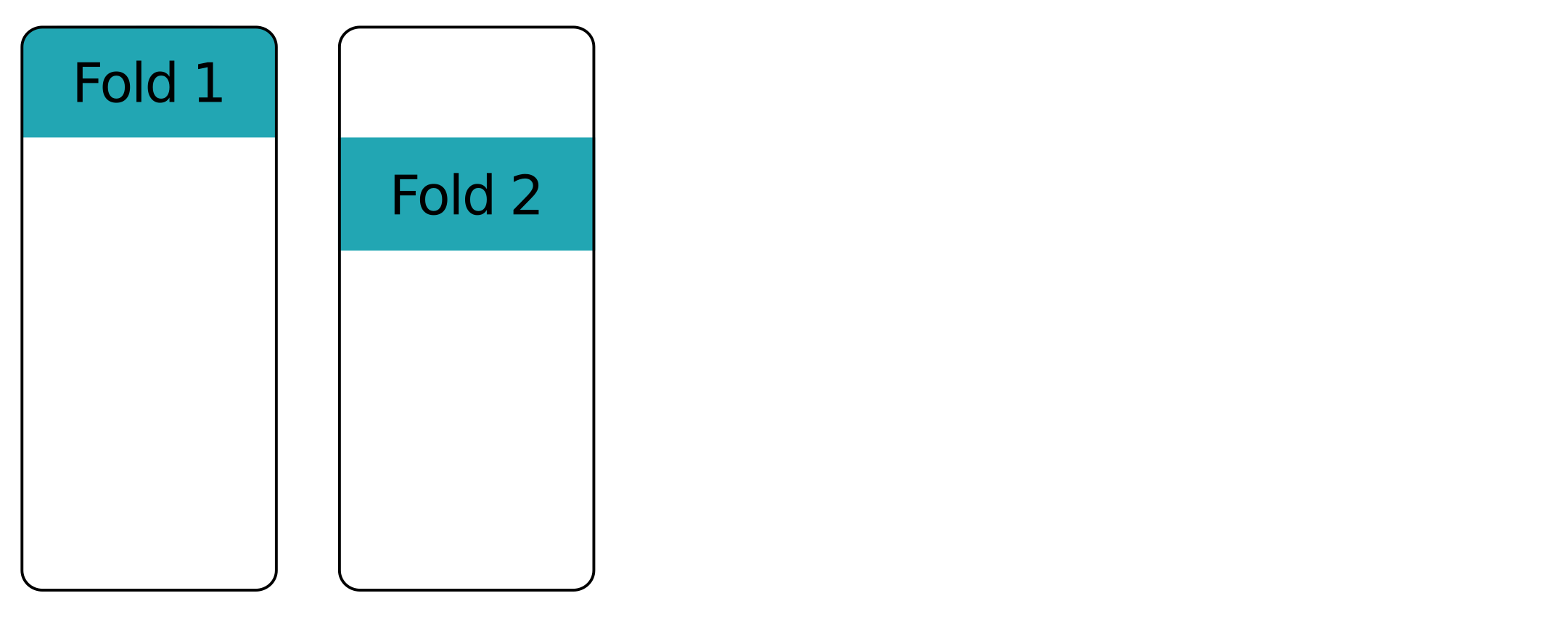
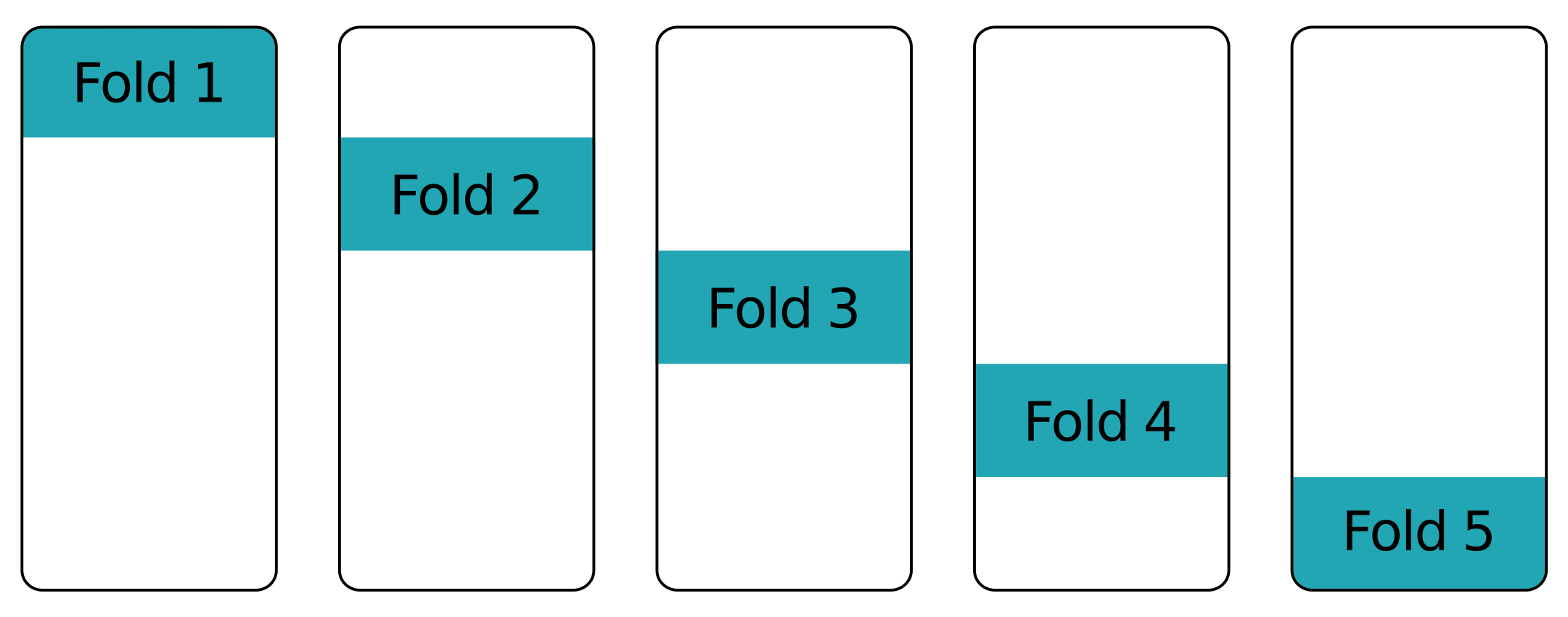
Kat üstüne kat - diğer katlar
PySpark ile Machine Learning
Andrew Collier
Data Scientist, Fathom Data

