Boru hattı
PySpark ile Machine Learning

Andrew Collier
Data Scientist, Fathom Data
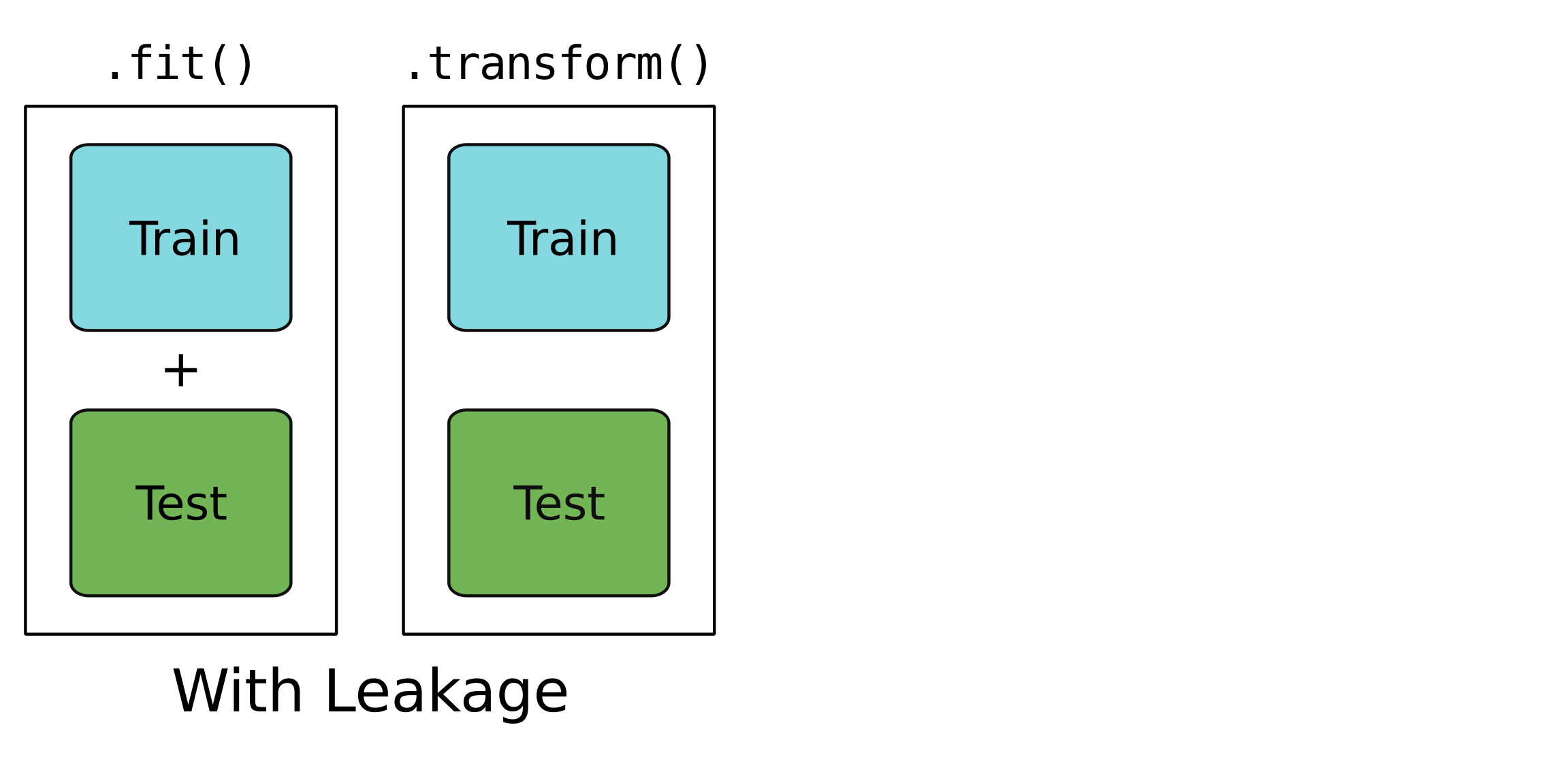
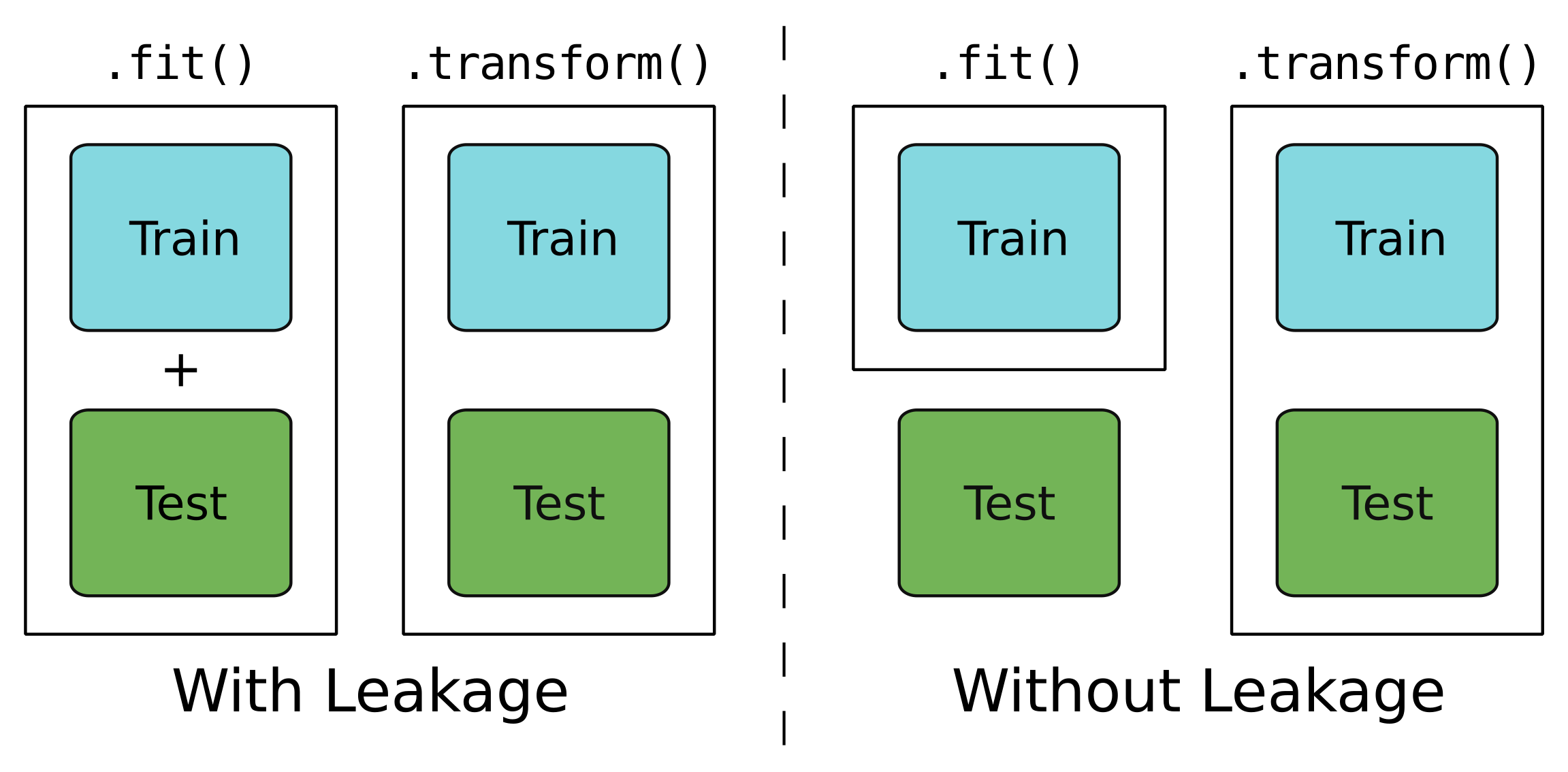
Sızıntı?

Yalnızca eğitim verisi için.

Test ve eğitim verisi için.
Sızıntılı bir model
Sızdırmaz bir model
Boru hattı
Bir boru hattı bir dizi işlemlerden oluşur.

Her işlemi tek tek uygulayabilirsiniz... ya da doğrudan boru hattını uygulayabilirsiniz!

