Python'da hiperparametre ayarlama
Python'da Hiperparametre Ayarlama

Alex Scriven
Data Scientist
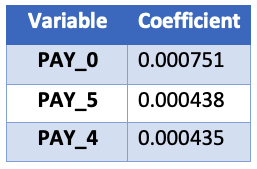
Lojistik Regresyonda Parametreler
Şimdi ilk üç katsayıyı sıralayıp yazdırın
coefs.sort_values(by=["Coefficient"], axis=0, inplace=True, ascending=False)
print(coefs.head(3))