Hiperparametre Değerleri
Python'da Hiperparametre Ayarlama

Alex Scriven
Data Scientist
Hiperparametre Ayarlamasını Otomatikleştirme
Sonuçları görüntülemek için bir DataFrame'de saklayabiliriz:
results_df = pd.DataFrame({'neighbors':neighbors_list, 'accuracy':accuracy_list})
print(results_df)

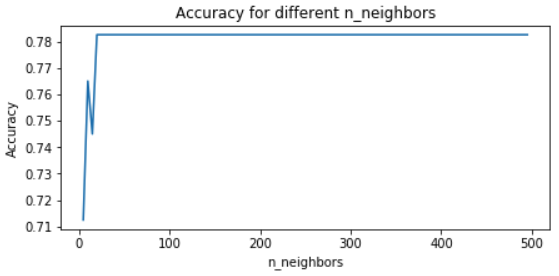
Öğrenme Eğrileri
Grafiğimiz: