Scikit Learn ile Izgara Araması
Python'da Hiperparametre Ayarlama

Alex Scriven
Data Scientist
GridSearchCV Nesnesi
Bir GridSearchCV nesnesine giriş:
sklearn.model_selection.GridSearchCV(
estimator,
param_grid, scoring=None, fit_params=None,
n_jobs=None, refit=True, cv='warn',
verbose=0, pre_dispatch='2*n_jobs',
error_score='raise-deprecating',
return_train_score='warn')
Izgara Aramasının Adımları
Izgara Aramasındaki adımlar:
- Hiperparametreleri ayarlayacağımız bir algoritma (tahminci)
- Hangi hiperparametreleri ayarlayacağımızı tanımlama
- Her hiperparametre için bir değer aralığı tanımlama
- Bir çapraz doğrulama şeması belirleme
- Izgaradaki en iyi kareyi seçmek için bir skor fonksiyonu tanımlama
- Ek yararlı bilgi ya da işlevler ekleme
GridSearchCV Nesnesi Girdileri
Önemli girdiler:
estimatorparam_gridcvscoringrefitn_jobsreturn_train_score
GridSearchCV 'estimator'
estimator girdisi:
- Esasen algoritmamız
- KNN, Rastgele Orman, GBM, Lojistik Regresyon ile zaten çalıştınız
Unutmayın:
- GridSearchCV nesnesi başına yalnızca bir tahminci
GridSearchCV 'param_grid'
param_grid girdisi:
- Test edilecek hiperparametreleri ve değerleri ayarlama
Liste yerine:
max_depth_list = [2, 4, 6, 8]
min_samples_leaf_list = [1, 2, 4, 6]
Bu şöyle olur:
param_grid = {'max_depth': [2, 4, 6, 8],
'min_samples_leaf': [1, 2, 4, 6]}
GridSearchCV 'param_grid'
param_grid girdisi:
Unutmayın: param_grid sözlüğündeki anahtarlar geçerli hiperparametreler olmalıdır.
Örneğin, bir Lojistik regresyon tahmincisi için:
# Incorrect
param_grid = {'C': [0.1,0.2,0.5],
'best_choice': [10,20,50]}
ValueError: Invalid parameter best_choice for estimator LogisticRegression
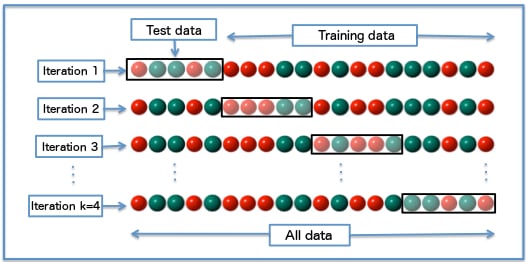
GridSearchCV 'cv'
cv girdisi:
- Çapraz doğrulamanın nasıl yapılacağını seçer
- Bir tamsayı, k-katlı çapraz doğrulamayı başlatır; genelde 5 veya 10 kullanılır
GridSearchCV 'scoring'
scoring girdisi:
- En iyi kareyi (modeli) seçmek için hangi skoru kullanacağınızı belirler
- Kendi skorunuzu ya da Scikit Learn
metricsmodülünü kullanın
Tüm yerleşik skorlayıcıları şöyle görebilirsiniz:
from sklearn import metrics
sorted(metrics.SCORERS.keys())
GridSearchCV 'refit'
refit girdisi:
- En iyi hiperparametreleri eğitim verisine uydurur
GridSearchCVnesnesinin bir tahminci (öngörü) olarak kullanılmasını sağlar- Çok kullanışlı bir seçenektir
GridSearchCV 'n_jobs'
n_jobs girdisi:
- Paralel yürütmeyi destekler
- Modellerin art arda yerine eşzamanlı oluşturulmasına izin verir
Faydalı kod:
import os
print(os.cpu_count())
Diğer işler yapacaksanız tüm çekirdekleri modele ayırırken dikkat edin!
GridSearchCV 'return_train_score'
return_train_score girdisi:
- Yapılan eğitim çalışmaları hakkında istatistikleri kaydeder
- Sapma-varyans dengesini analiz etmek için yararlıdır, ancak hesaplama maliyeti ekler
- En iyi modeli seçmeye yardımcı olmaz; yalnızca analiz içindir
Bir GridSearchCV nesnesi oluşturma
Kendi GridSearchCV Nesnemizi oluşturma:
# Create the grid param_grid = {'max_depth': [2, 4, 6, 8], 'min_samples_leaf': [1, 2, 4, 6]}#Get a base classifier with some set parameters. rf_class = RandomForestClassifier(criterion='entropy', max_features='auto')
Bir GridSearchCv Nesnesi Oluşturma
Parçaları birleştirme:
grid_rf_class = GridSearchCV(
estimator = rf_class,
param_grid = parameter_grid,
scoring='accuracy',
n_jobs=4,
cv = 10,
refit=True,
return_train_score=True)
Bir GridSearchCV Nesnesi Kullanma
refit değerini True yaptığımız için nesneyi doğrudan kullanabiliriz:
#Fit the object to our data
grid_rf_class.fit(X_train, y_train)
# Make predictions
grid_rf_class.predict(X_test)
Ayo berlatih!
Python'da Hiperparametre Ayarlama

