Ödül modellerine genel bakış
İnsan Geri Bildiriminden Pekiştirmeli Öğrenme (RLHF)

Mina Parham
AI Engineer
Şu ana kadarki süreç
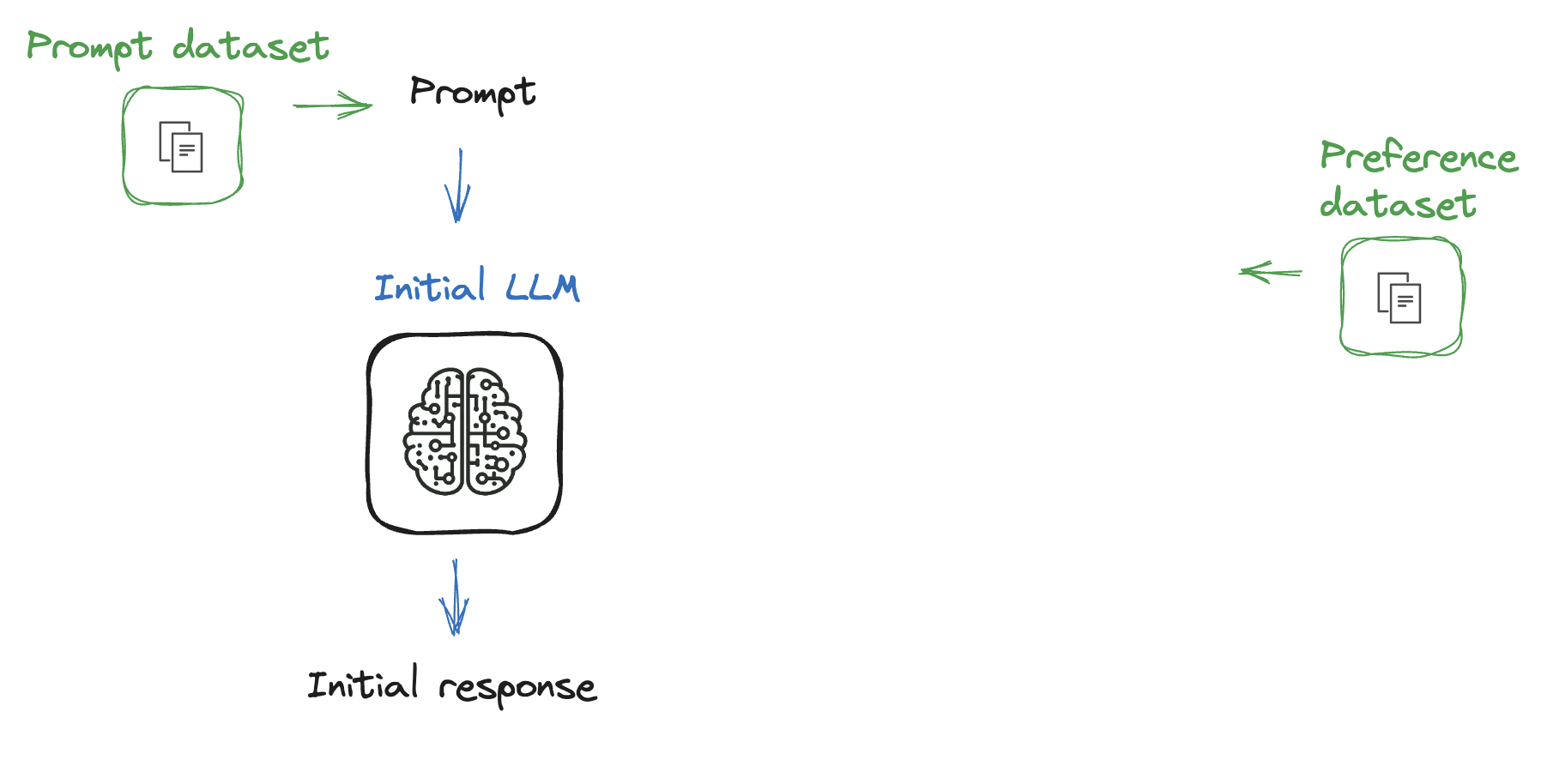
Şu ana kadarki süreç

Ödül modeli nedir?
Ödül modeli nedir?
- Model, ajanı bilgilendirir
- Ajan, ödülü en üst düzeye çıkarmak için modeli değerlendirir


