RLHF'te verimli ince ayar
İnsan Geri Bildiriminden Pekiştirmeli Öğrenme (RLHF)

Mina Parham
AI Engineer
Parametre-verimli ince ayar
- Tüm modeli ince ayarlama
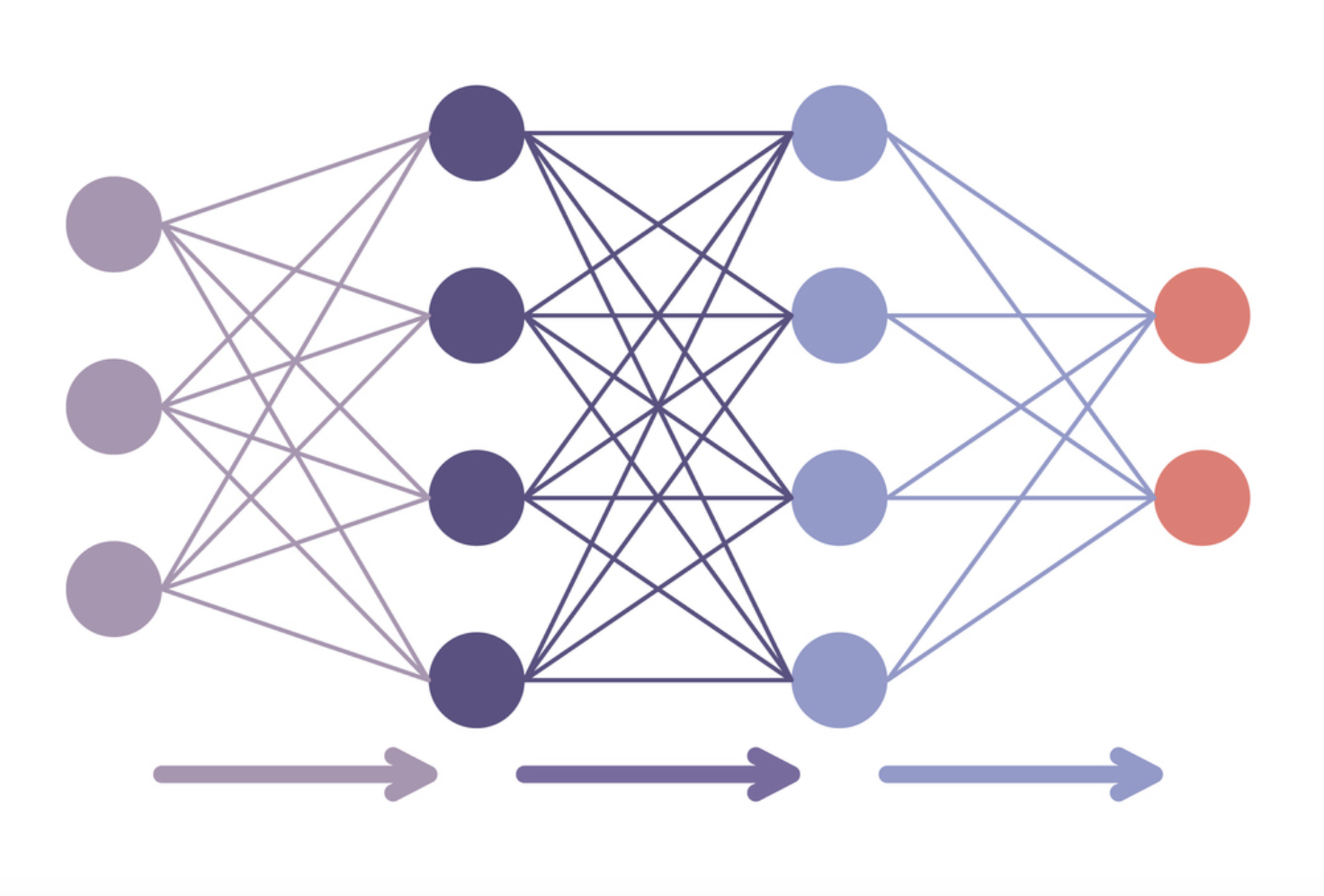
Parametre-verimli ince ayar
- PEFT ile ince ayar
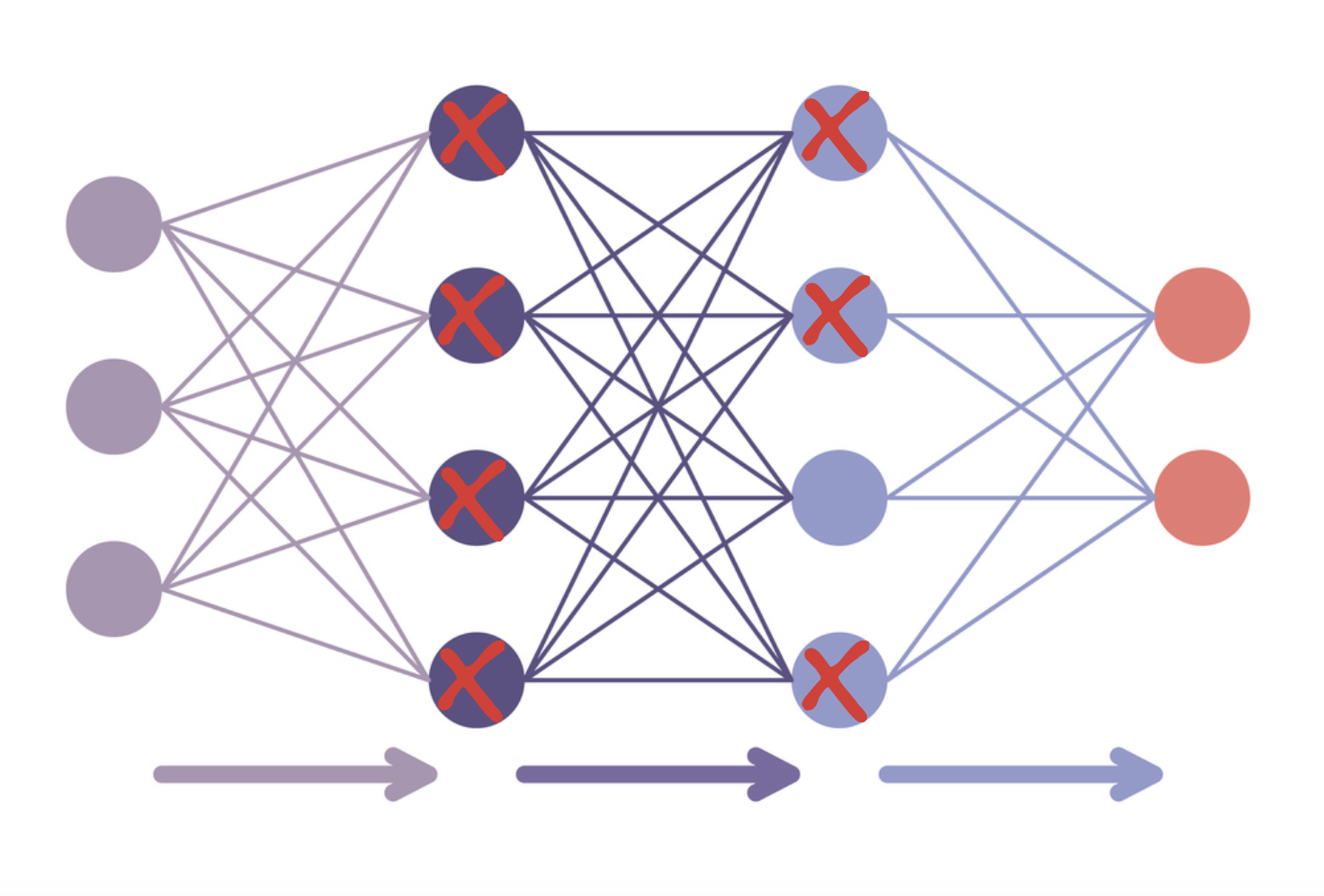
- LoRA: yalnızca birkaç katmanı ayarlar
- Kuantizasyon: veri türü hassasiyetini düşürür

