RLHF'ye Giriş
İnsan Geri Bildiriminden Pekiştirmeli Öğrenme (RLHF)

Mina Parham
AI Engineer
Kursa hoş geldiniz!
- Konu: İnsan Geri Bildiriminden Pekiştirmeli Öğrenme (RLHF)

Kursa hoş geldiniz!
- Konu: İnsan Geri Bildiriminden Pekiştirmeli Öğrenme (RLHF)
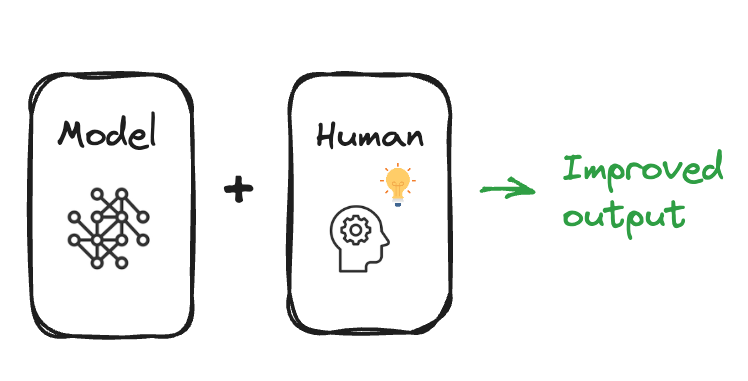
Pekiştirmeli öğrenme özeti
Pekiştirmeli öğrenme özeti

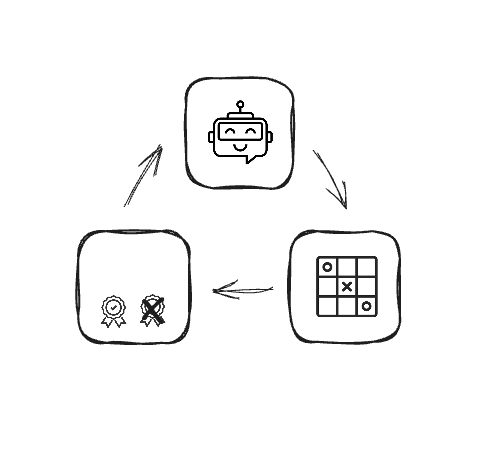
Pekiştirmeli öğrenme özeti
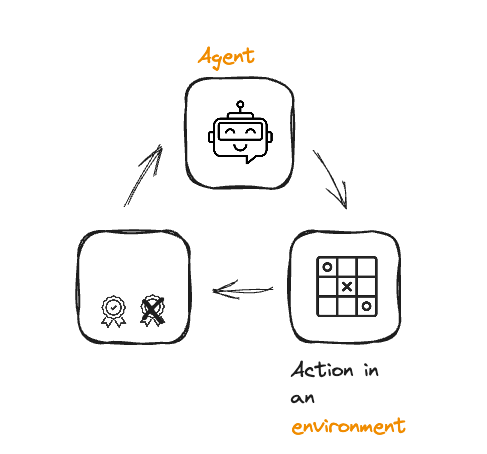
Pekiştirmeli öğrenme özeti
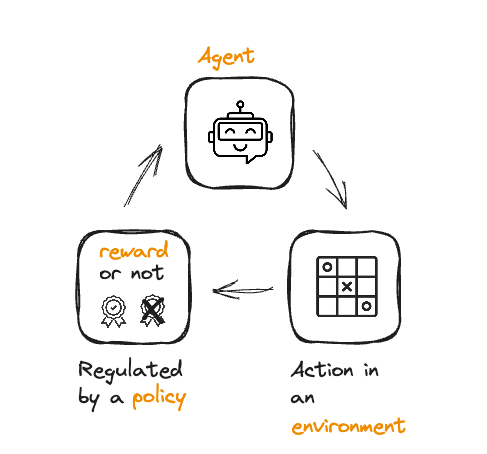
RL'den RLHF'ye

RL'den RLHF'ye
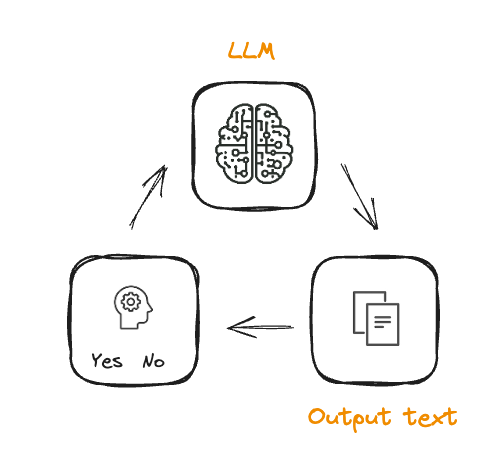
RL'den RLHF'ye
- Ödül modeli eğitimi
- İnsan tercihleriyle hizalama

RLHF'de LLM ince ayarı
RLHF'de LLM ince ayarı

Tam RLHF süreci

Tam RLHF süreci

Tam RLHF süreci

Tam RLHF süreci

Tam RLHF süreci
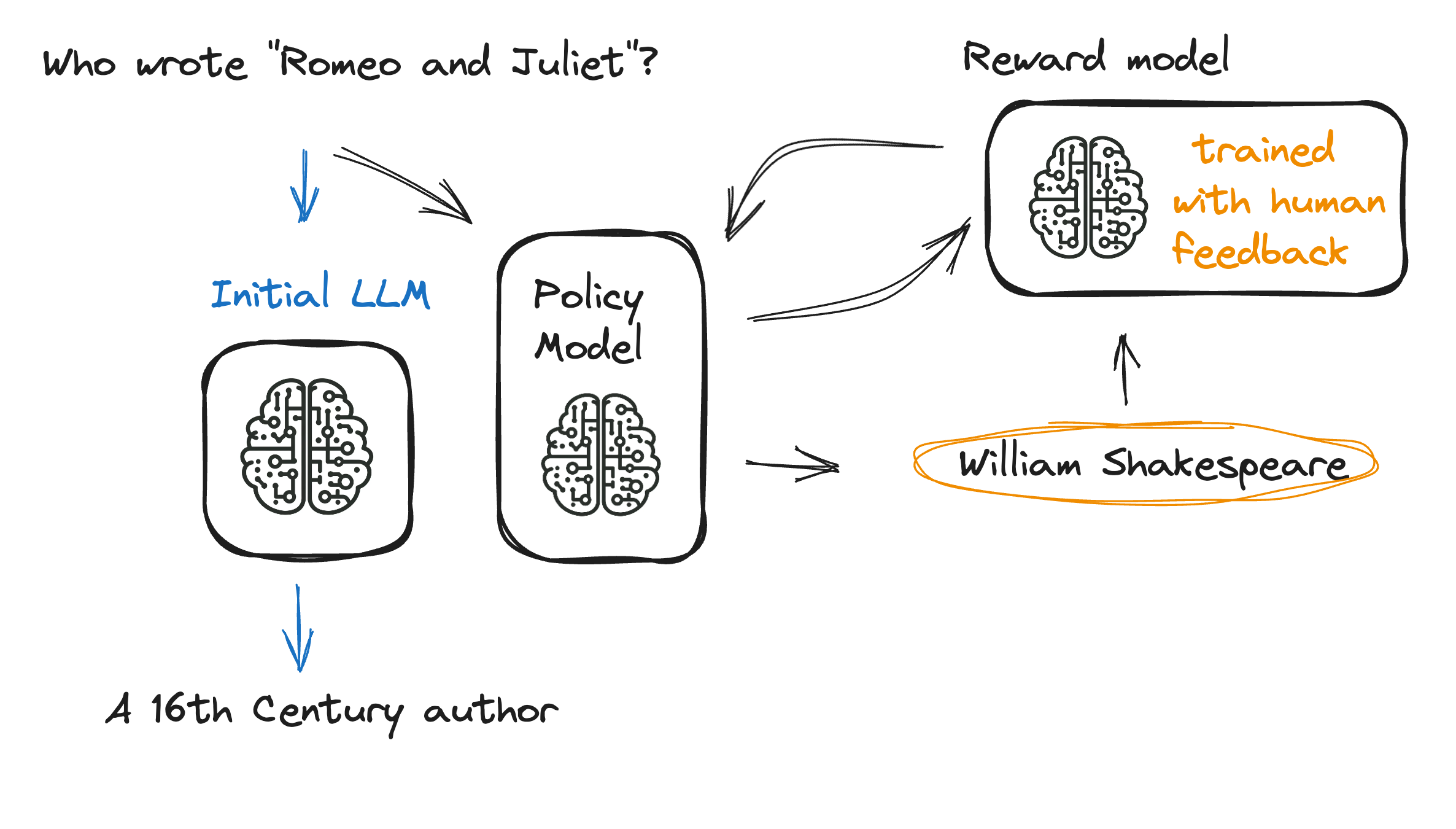
Tam RLHF süreci


