PPO ile eğitim
İnsan Geri Bildiriminden Pekiştirmeli Öğrenme (RLHF)

Mina Parham
AI Engineer
Pekiştirmeli öğrenme ile ince ayar
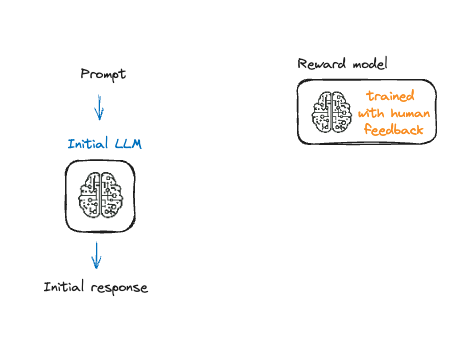
Pekiştirmeli öğrenme ile ince ayar
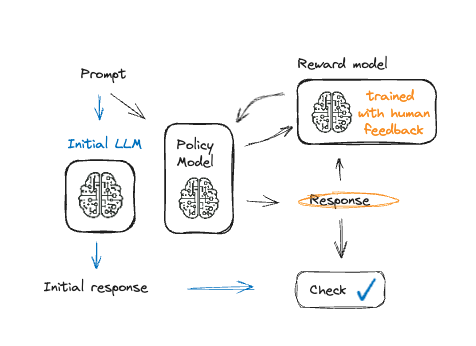
PPO ile Dil Modelini İnce Ayarlama
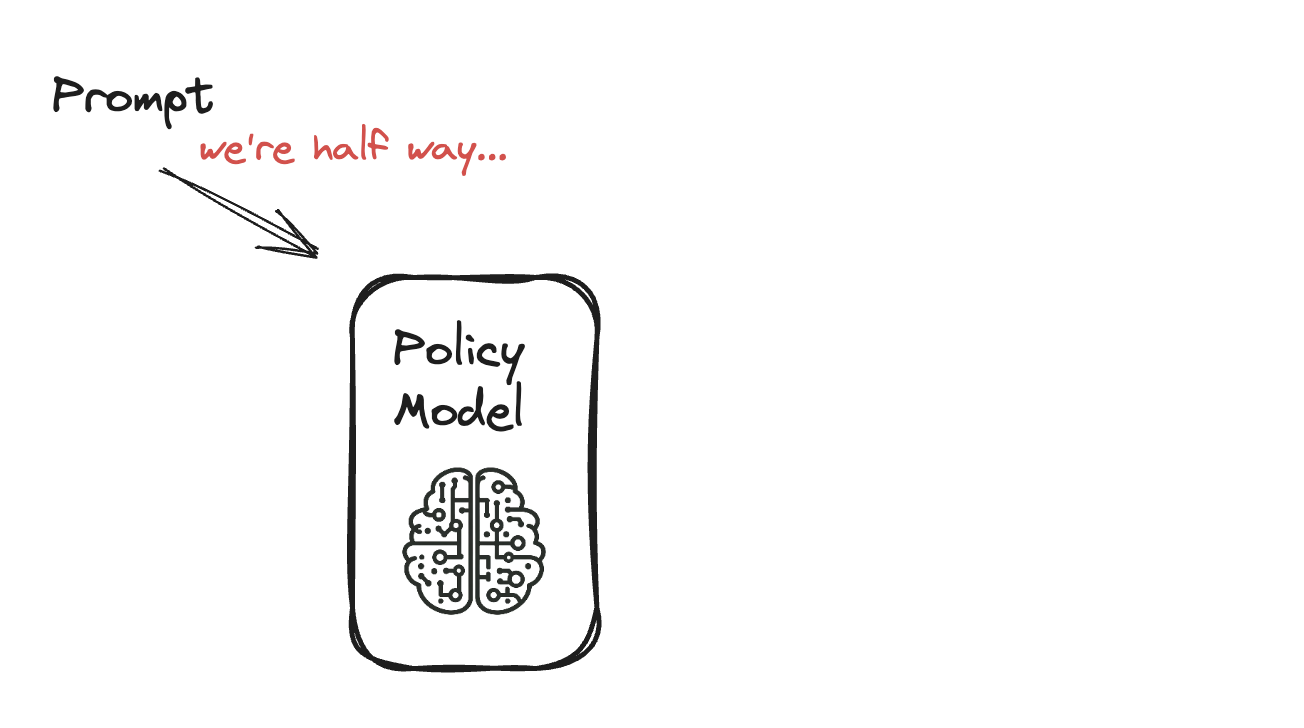
PPO ile Dil Modelini İnce Ayarlama
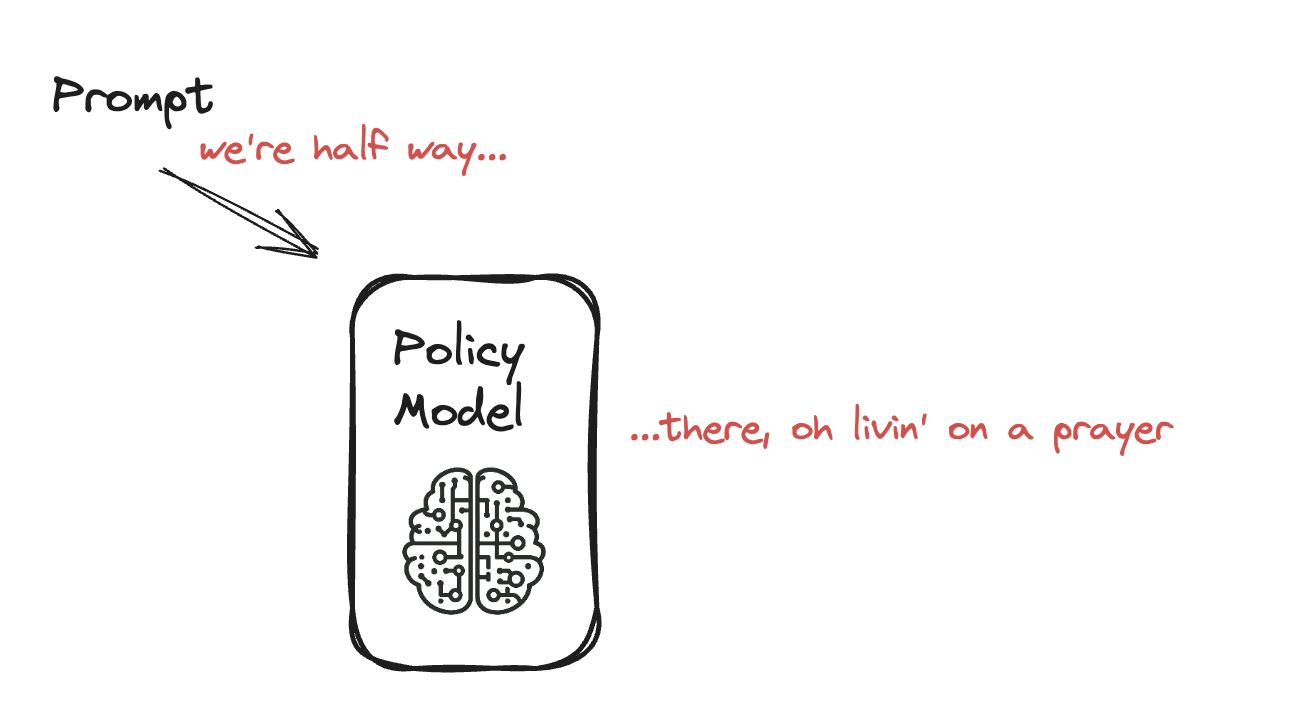
PPO ile Dil Modelini İnce Ayarlama
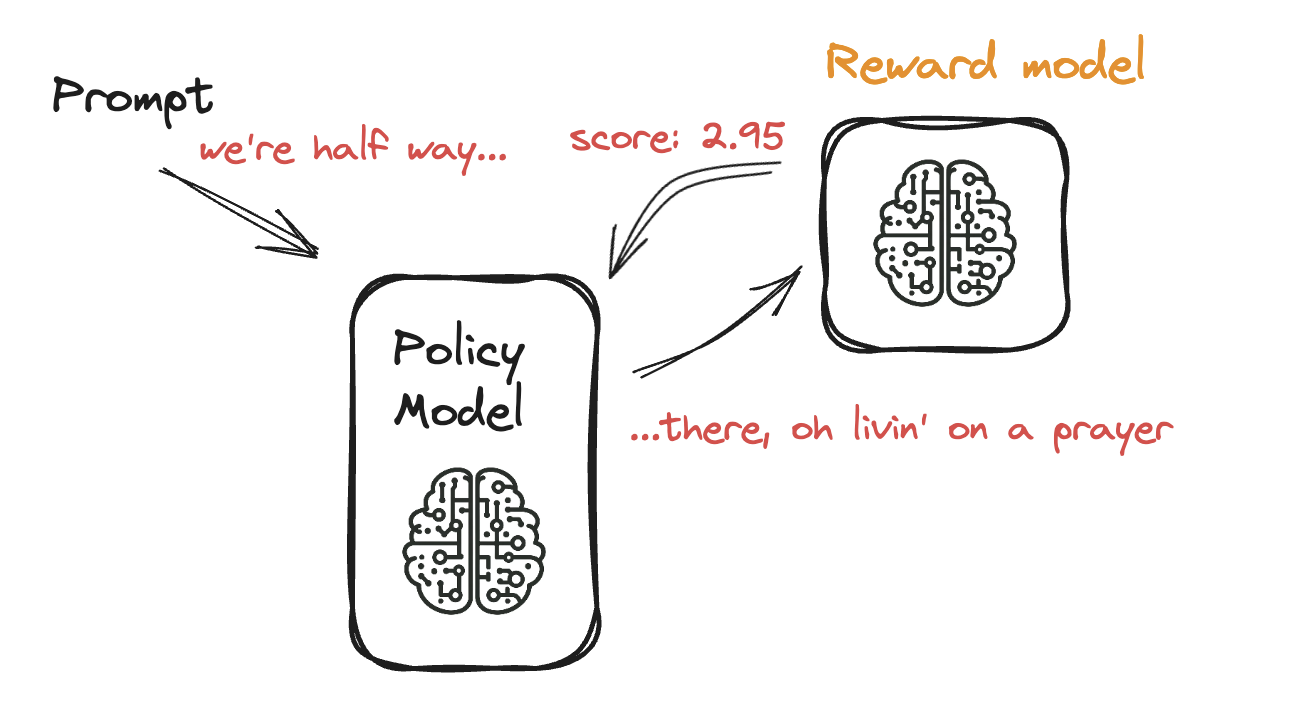
PPO ile Dil Modelini İnce Ayarlama
- PPO: modele kademeli ayarlama
- Geri bildirime aşırı uyumu önler


