Model ölçütleri ve ayarlamalar
İnsan Geri Bildiriminden Pekiştirmeli Öğrenme (RLHF)

Mina Parham
AI Engineer
Neden bir referans modeli kullanılır?

Model çıktısını kontrol etme
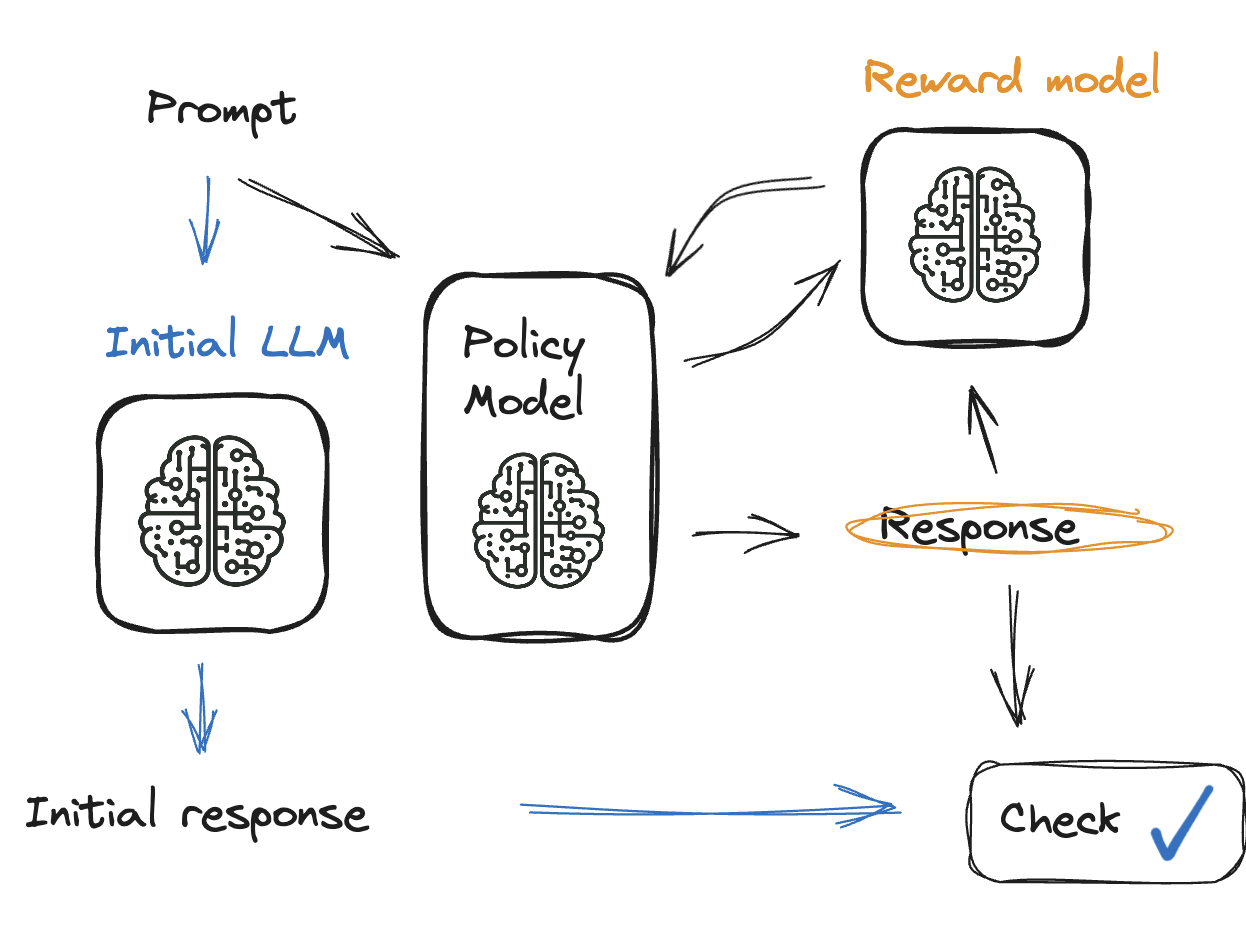
Çözüm: KL ayrışımı
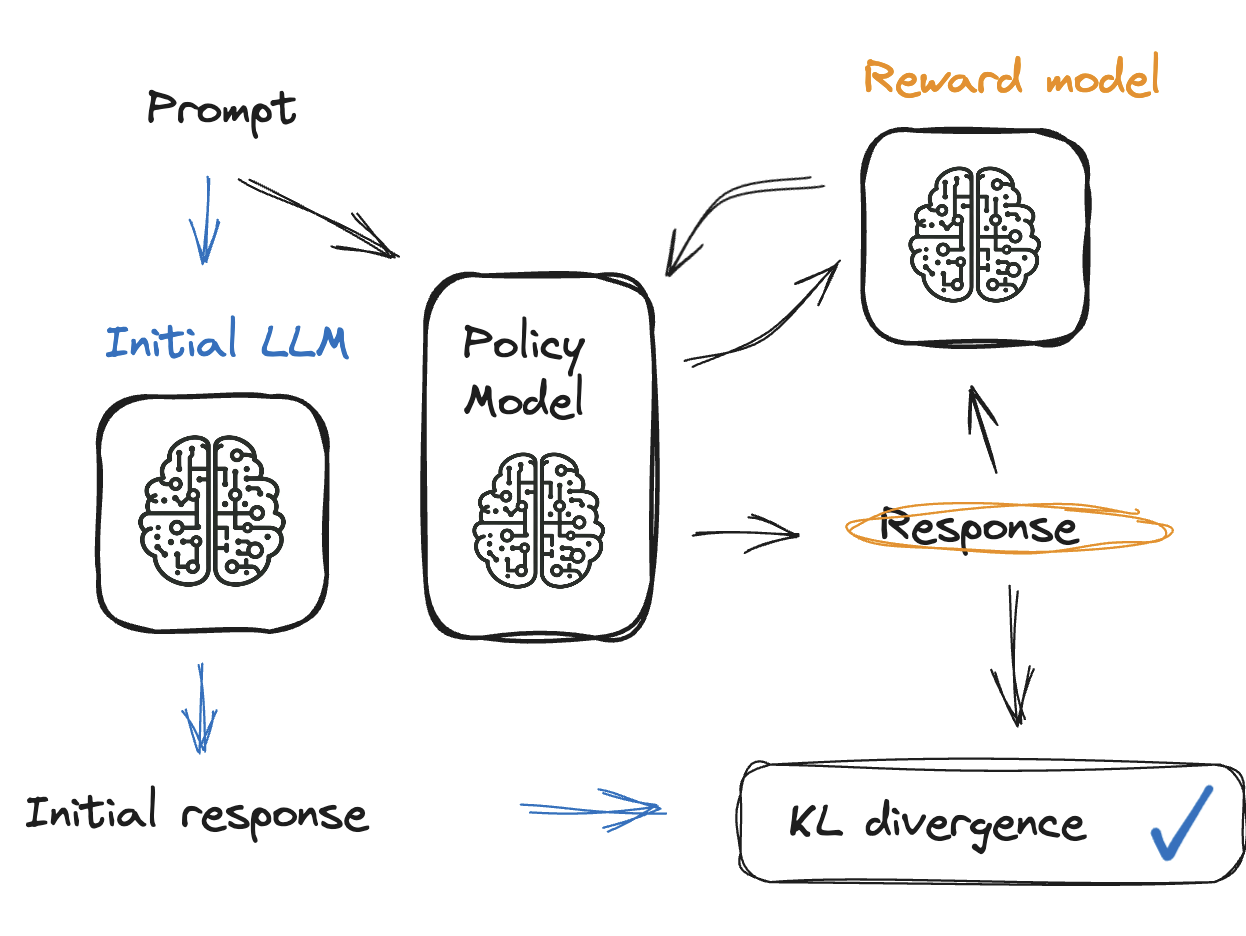
Çözüm: KL ayrışımı
- Ceza, ödül modeline eklenir
- Model ilgisiz çıktılar üretirse ceza onu yönlendirir
- KL ayrışımı, mevcut modelle ödül modelini karşılaştırır

- 0 ile 10 arasında, asla negatif değil

