spaCy ile anlamsal benzerliği ölçme
spaCy ile Natural Language Processing

Azadeh Mobasher
Principal Data Scientist
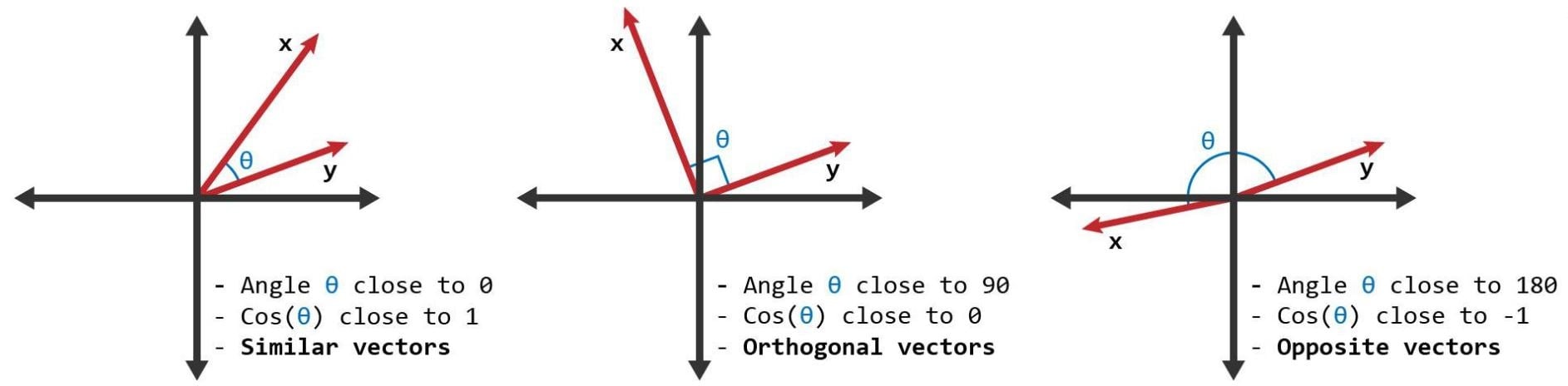
Benzerlik skoru
- Metinler üzerinde tanımlı bir metrik
- Benzerliği ölçmek için kosinüs benzerliği ve kelime vektörleri kullanılır
- Kosinüs benzerliği 0 ile 1 arasında bir sayıdır