Metin tabanlı benzerlikler
Python ile Öneri Motorları Geliştirme

Rob O'Callaghan
Director of Data
Açık öznitelikler olmadan çalışmak

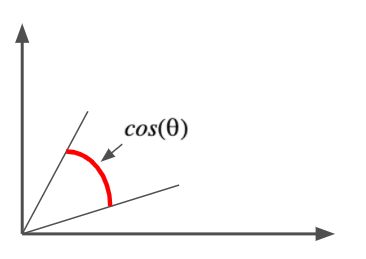
Kosinüs benzerliği
Kosinüs uzaklığı: $$cos(\theta)=\frac{A.B }{||A||\cdot||B||}$$
Python ile Öneri Motorları Geliştirme
Rob O'Callaghan
Director of Data
Kosinüs uzaklığı: $$cos(\theta)=\frac{A.B }{||A||\cdot||B||}$$

