Bölümlendirme için veri hazırlığı
Python ile Pazarlama için Machine Learning

Karolis Urbonas
Head of Analytics & Science, Amazon
Log dönüşümlü veriyi inceleyin
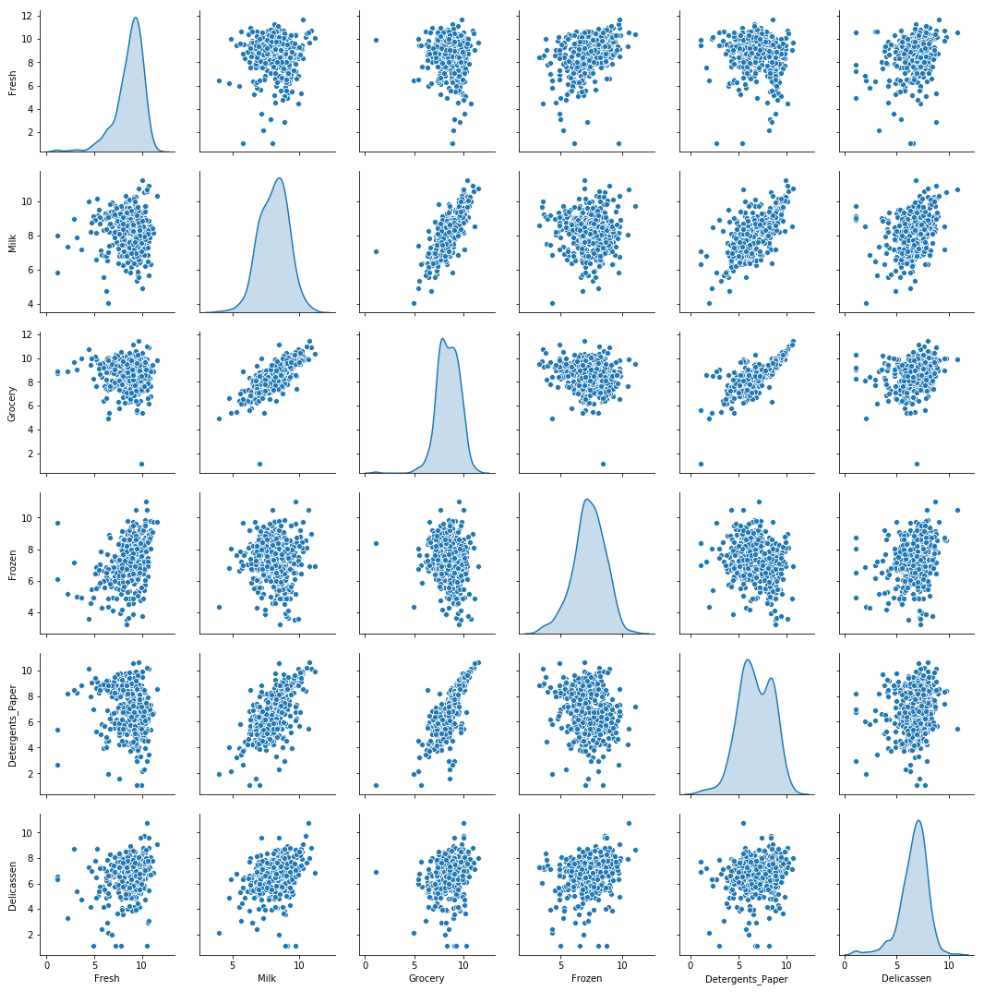
Box-Cox dönüşümlü veriyi inceleyin
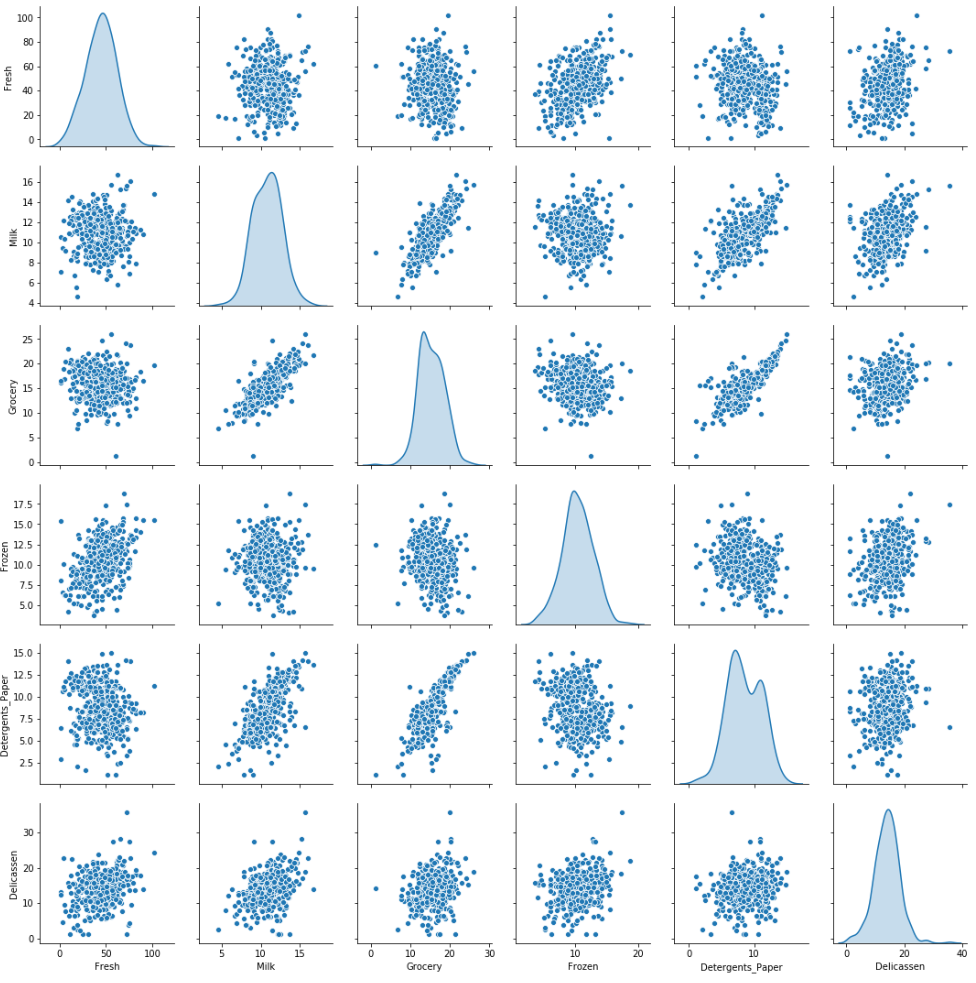
Python ile Pazarlama için Machine Learning
Karolis Urbonas
Head of Analytics & Science, Amazon

