# Modeli eğitme
model = LGBMRegressor(random_state=42)
model.fit(X_train, y_train)
# Tahmin yapma
y_pred_train = model.predict(X_train)
y_pred_test = model.predict(X_test)
# Modeli eğitim ve testte değerlendirme
mae_train = MAE(y_train, y_pred_train)
mae_test = MAE(y_test, y_pred_test)
# Modeli üretime alma
y_pred_prod = model.predict(X_prod)
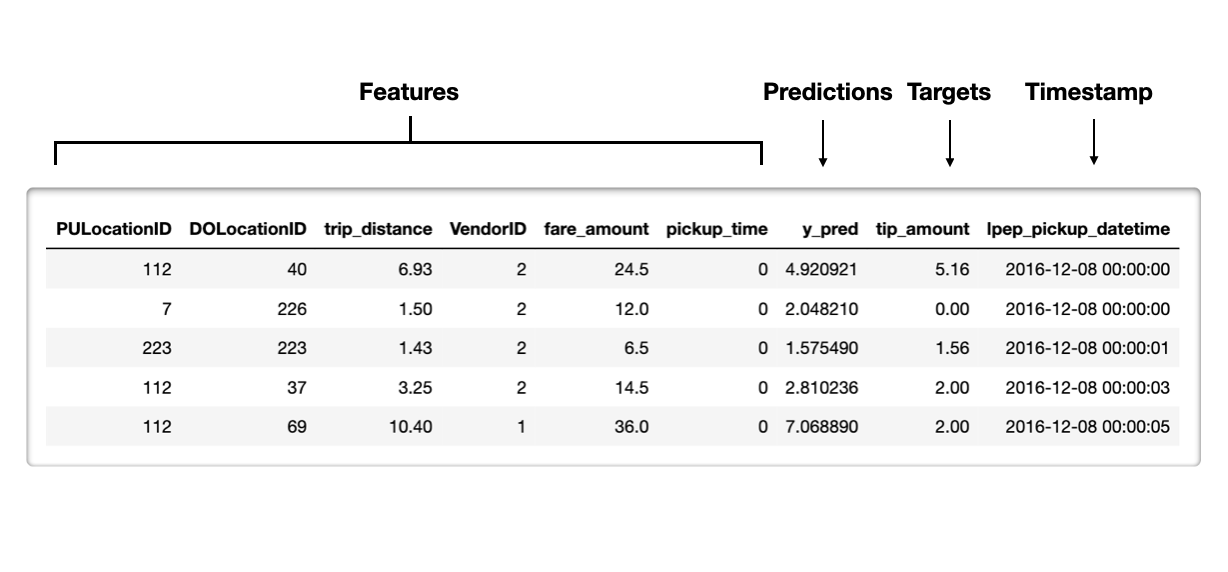
Referans ve analiz kümeleri oluşturma
Referans dönemi
Test kümesi kullanır
Gerçek değer gerekir
Temel performansı belirler
Analiz dönemi
En güncel üretim verisi
Gerçek değer isteğe bağlıdır
NannyML veri kaymasını ve performansı inceler
# Referans kümesi oluşturma
reference = X_test.copy() # Test kümesi özellikleri
reference['y_pred'] = y_pred_test # Tahminler
reference['tip_amount'] = y_test # Etiketler
reference = reference.join(
data['lpep_pickup_datetime']) # Zaman damgası
# Analiz kümesi oluşturma
analysis = X_prod.copy() # Üretim özellikleri
analysis['y_pred'] = y_pred_prod # Tahminler
analysis = analysis.join(
data['lpep_pickup_datetime']) # Zaman damgası
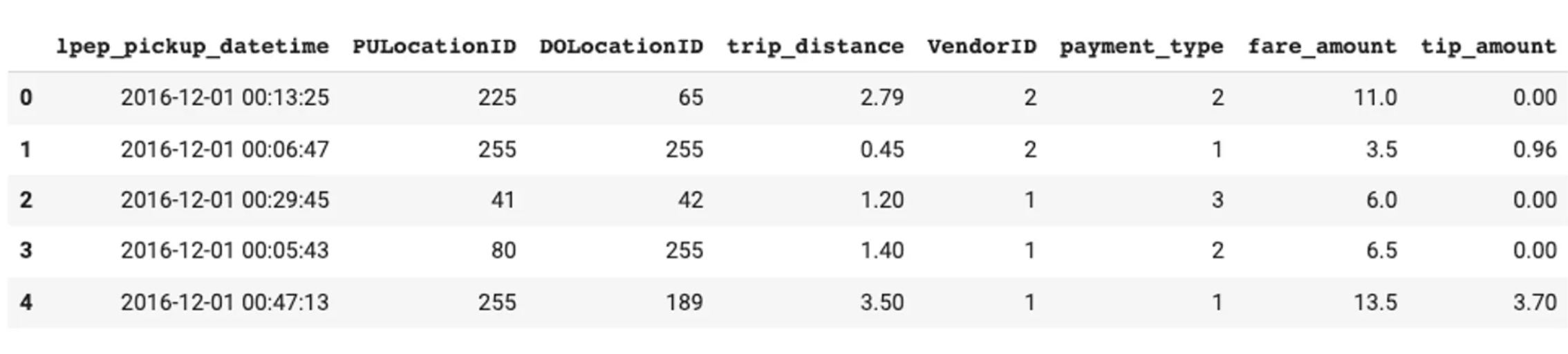
Referans kümesi örneği
Zaman damgası - gözlemin gerçekleştiği an (isteğe bağlı)
Özellikler - modele verilen özellikler
Model çıktıları
Tahminler - modelin ürettiği skor
Tahmin sınıf etiketleri - eşiklenmiş olasılık skorları