Neden mevcut özellikleri dönüştürmeliyiz?
R'da Feature Engineering

Jorge Zazueta
Research Professor. Head of the Modeling Group at the School of Economics, UASLP
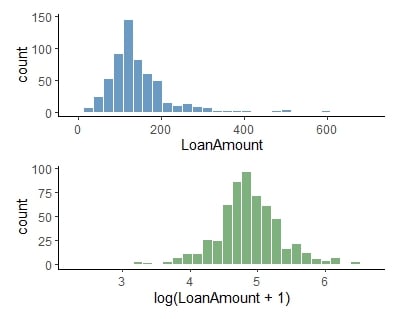
Log dönüşümü
Log-dönüştürülmüş kredi tutarı verisi
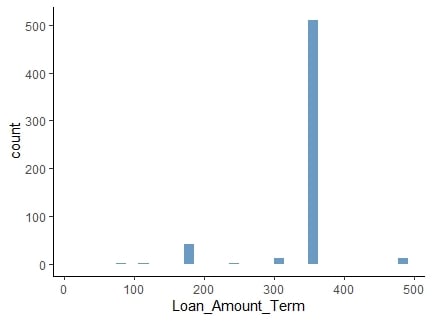
Normalizasyon
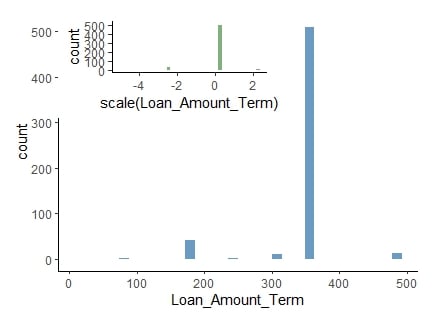
ör. kredi vade tutarı değerleri ciddi şekilde değişir
Normalizasyon
Normalleştirilmiş değerler dağılımı korur, ancak değişkenlik içerir.