Denetimli öğrenme boru hatları
Python'da Machine Learning İş Akışları Tasarlama

Dr. Chris Anagnostopoulos
Honorary Associate Professor
Etiketli veri
- Özellik değişkenleri (kısaltma:
X) - Etiketler veya sınıf (kısaltma:
y)
credit_scoring.head(4)
checking_status duration ... foreign_worker class
0 '<0' 6 ... yes good
1 '0<=X<200' 48 ... yes bad
2 'no checking' 12 ... yes good
3 '<0' 42 ... yes good
Özellik mühendisliği
- Çoğu sınıflandırıcı sayısal özellikler bekler
- Dize sütunları sayıya çevrilmelidir
sklearn.preprocessing içindeki LabelEncoder ile ön işleme:
le = LabelEncoder()
le.fit_transform(credit_scoring['checking_status'])[:4]
array([1, 0, 3, 1])
Model eğitimi
.fit(features, labels).predict(features)
features, labels = credit_scoring.drop('class', 1), credit_scoring['class']model_nb = GaussianNB() model_nb.fit(features, labels) model_nb.predict(features.head(5))
['good' 'bad' 'good' 'bad' 'good']
İlk 5 örnekte %60 doğruluk.
Model seçimi
.fit()verilen modelin parametrelerini optimize eder- Diğer modeller ne durumda?
AdaBoostClassifier, ilk beş veri noktasında GaussianNB'den daha iyi:
model_ab = AdaBoostClassifier()
model_ab.fit(features, labels)
model_ab.predict(features.head(5))
numpy.array(labels[0:5])
['good' 'bad' 'good' 'good' 'bad']
['good' 'bad' 'good' 'good' 'bad']
Performans değerlendirmesi
Daha büyük örneklem boyutu ⇒ daha iyi doğruluk tahmini:
from sklearn.metrics import accuracy_score
accuracy_score(labels, model_nb.predict(features)) # naive bayes
0.706
accuracy_score(labels, model_ab.predict(features)) # adaboost
0.802
Bu hesaplamada ne yanlış?
Aşırı uyum ve veri bölme
Aşırı uyum (overfitting): Bir model, eğitildiği veride her zaman görülmeyen veriye göre daha iyi performans gösterir.
X_train, y_train ile eğitin, X_test, y_test üzerinde doğruluğu değerlendirin:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)GaussianNB().fit(X_train, y_train).predict(X_test)
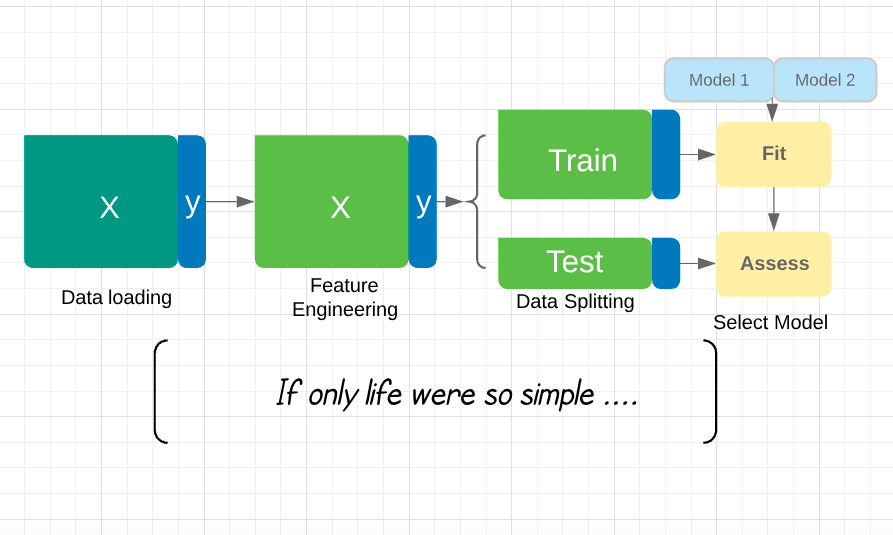
Peki, bu ders ne hakkında?
- Boru hattınızı ayarlamak için ölçeklenebilir yöntemler.
- Alan uzmanlarını dahil ederek tahminlerinizi ilgili kılmak.
- Modelinizin zamanla iyi performans göstermesini sağlamak.
- Yeterli etiket yokken model eğitmek.
Konut kredisi krizini önleyebilir miydiniz?
Python'da Machine Learning İş Akışları Tasarlama

