Uygulamada LDA
R ile Doğal Dil İşlemeye Giriş

Kasey Jones
Research Data Scientist
LDA sonuçlarını sonlandırma
- konu sayısını seçin
- belirsizlik/perplexity/diğer metrikler
- durumunuza uygun bir çözüm
Belirsizlik (Perplexity)
- bir olasılık modelinin yeni veriye ne kadar iyi uyduğunun ölçüsü
- daha düşük daha iyidir
- modelleri karşılaştırmak için kullanılır
- LDA parametre ayarında
- Konu sayısını seçmede
sample_size <- floor(0.90 * nrow(doc_term_matrix))
set.seed(1111)
train_ind <- sample(nrow(doc_term_matrix), size = sample_size)
train <- matrix[train_ind, ]
test <- matrix[-train_ind, ]
1 https://en.wikipedia.org/wiki/Perplexity
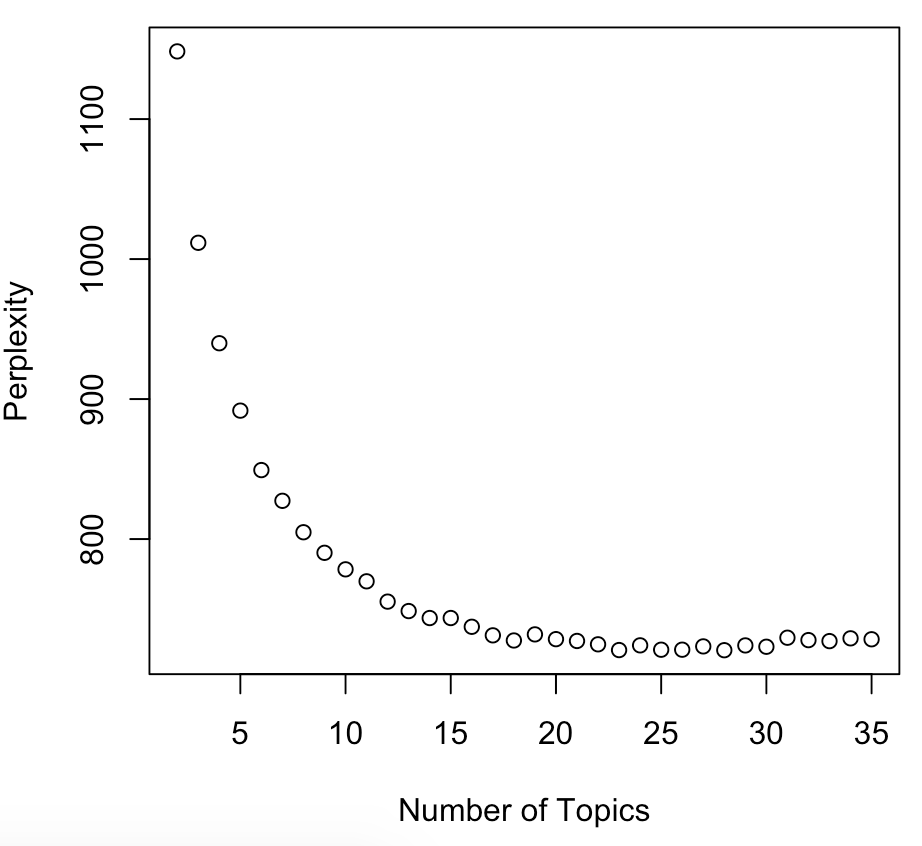
R’da belirsizlik
library(topicmodels)
values = c()
for(i in c(2:35)){
lda_model <- LDA(train, k = i, method = "Gibbs",
control = list(iter = 25, seed = 1111))
values <- c(values, perplexity(lda_model, newdata = test))
}
plot(c(2:35), values, main="Perplexity for Topics",
xlab="Number of Topics", ylab="Perplexity")
Belirsizlik tekrar!
Pratik seçim
- Durum kaç konuyu kaldırabilir?
- 20 konuyu kapsamak zor olabilir
- Sonuçları nasıl görselleştiriyorsunuz?
- 5 konulu grafikler, 100 konulu grafiklerden daha anlaşılır
- Başparmak kuralları:
- Her konu birkaç belgeyle temsil edilecek şekilde az sayıda konu kullanın
- Yüksek konu sayıları ancak her konuyu keşfetmeye zaman varsa uygundur
Sonuçları kullanma
- Her konu için “temalar”ı gözden geçirin veya değerlendiricilere buldurun
- değerlendiriciye konudaki en önemli sözcüklerin listesini verin
- değerlendiriciye o konunun en iyi belgelerinin listesini verin
Çıktıyı gözden geçirme
betas <- tidy(lda_model, matrix = "beta")
betas %>%
filter(topic == 1) %>%
arrange(desc(beta)) %>%
select(term)
# A tibble: 2,000 x 1
term
<chr>
1 athletic
2 quick
3 strong
4 tough
...
gammas <- tidy(lda_model, matrix = "gamma")
gammas %>%
filter(topic == 1) %>%
arrange(desc(gamma)) %>%
select(document)
# A tibble: 1,000 x 1
document
<chr>
1 232
2 292
3 921
4 643
5 468
Çıktıyı özetleme
gammas <- tidy(lda_model, matrix = "gamma")
gammas %>%
group_by(document) %>%
arrange(desc(gamma)) %>%
slice(1) %>%
group_by(topic) %>%
tally(topic, sort=TRUE)
topic n
1 1 1326
2 5 1215
3 4 804
...
Yeniden özetleme
gammas %>%
group_by(document) %>%
arrange(desc(gamma)) %>%
slice(1) %>%
group_by(topic) %>%
summarize(avg=mean(gamma)) %>%
arrange(desc(avg))
topic avg
1 1 0.696
2 5 0.530
3 4 0.482
...
LDA pratiği.
R ile Doğal Dil İşlemeye Giriş

