k-En Yakın Komşu kestirimi
R'de Atamaya Dayalı Eksik Veri Doldurma

Michal Oleszak
Machine Learning Engineer
k-En Yakın Komşu kestirimi
k-En Yakın Komşu kestirimi
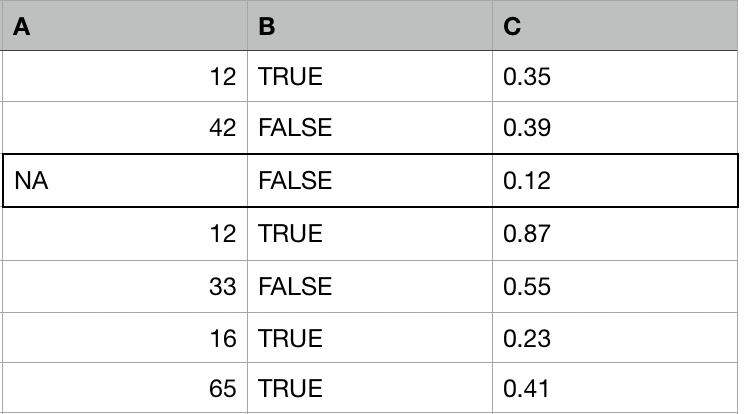
Eksik değeri olan her gözlem için:
- O gözleme en benzer olan diğer k gözlemi bulun (bağışçılar, komşular).
k-En Yakın Komşu kestirimi
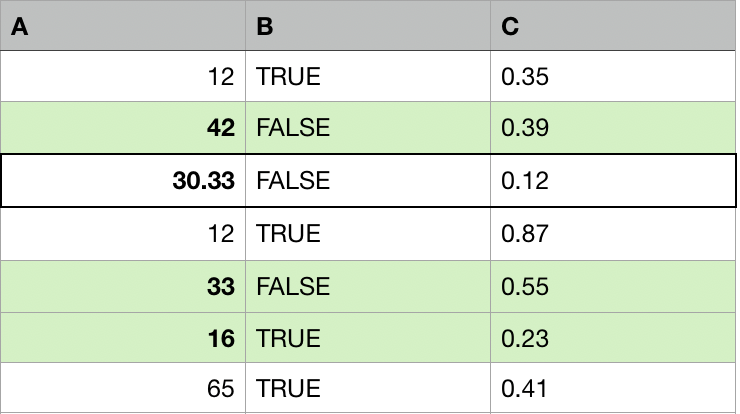
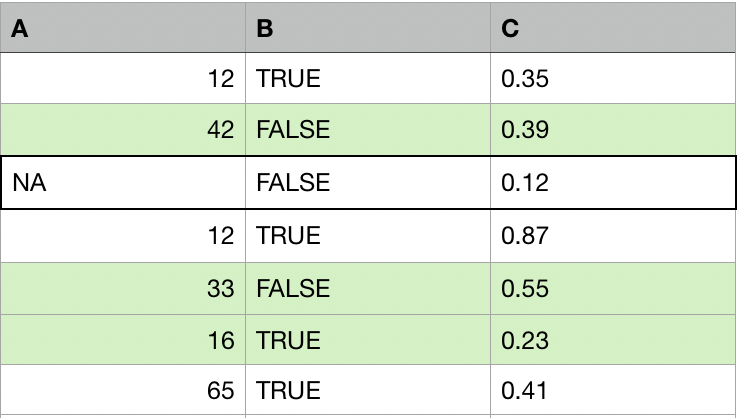
Eksik değeri olan her gözlem için:
- O gözleme en benzer olan diğer k gözlemi bulun (bağışçılar, komşular).
- Eksikleri k bağışçıdan toplanan değerlerle değiştirin (ortalama, medyan, mod).
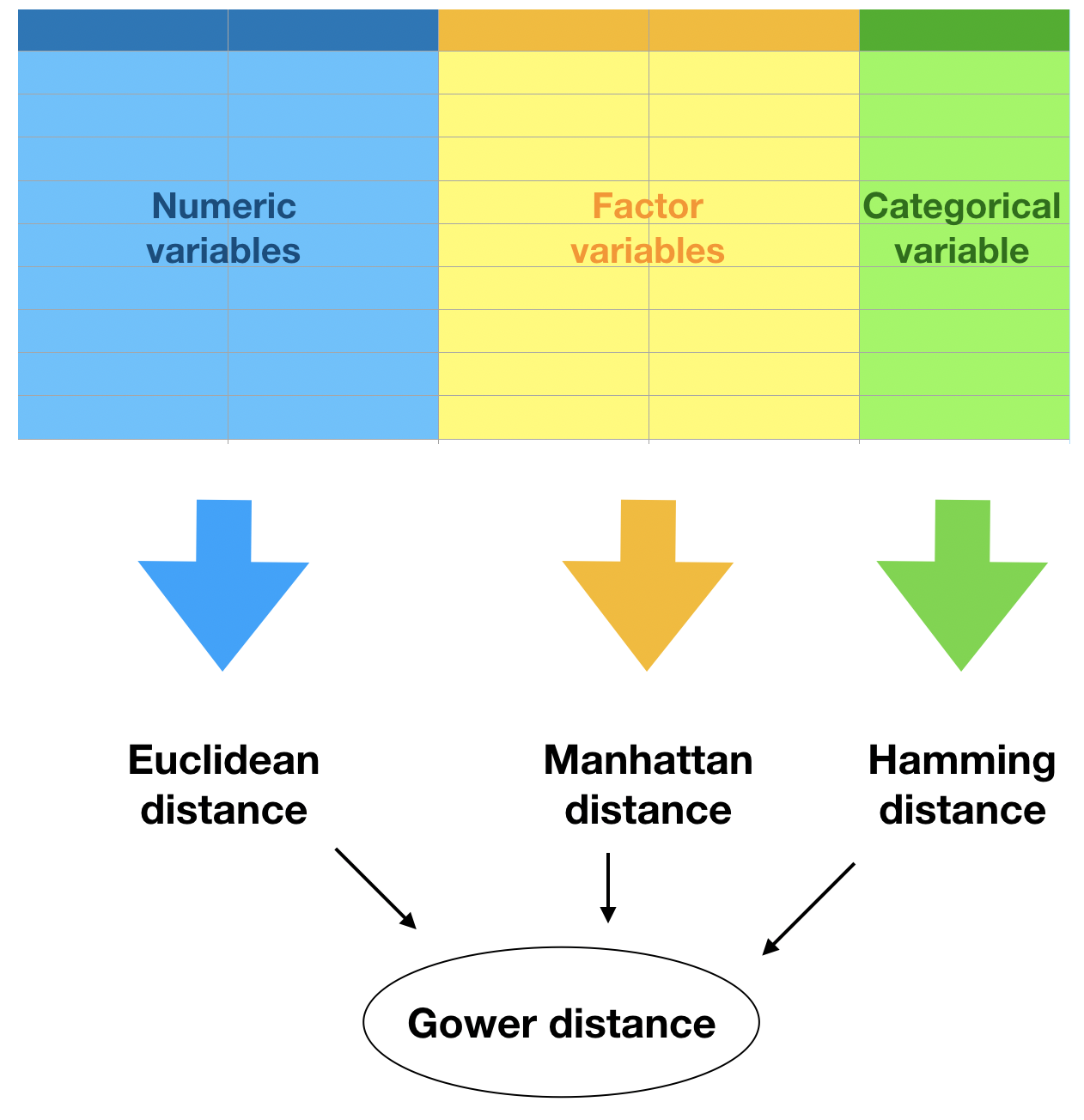
Uzaklık ölçüleri
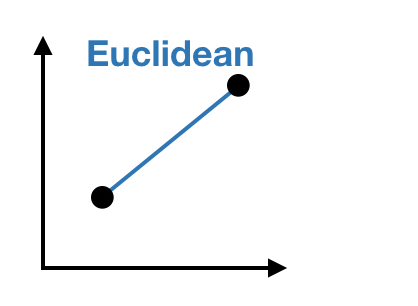
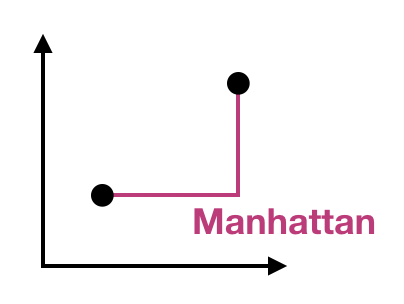
Gower uzaklığı
Gower uzaklığı