Kategorik verilerin anonimleştirilmesi
Python ile Veri Gizliliği ve Anonimleştirme

Rebeca Gonzalez
Instructor
Genelleştirme
Age Gender Department Condition
0 30 F Finance Anxiety disorders
1 42 M Production Bronchitis
2 35 F Marketing Dysthymia
3 39 F Production Dysthymia
4 40 M Marketing Flu
Age Gender Department Condition
0 <40 F Finance Anxiety disorders
1 >=40 M Production Bronquitis
2 <40 F Finance Dysthymia
3 <40 F Production Dysthymia
4 >=40 M Marketing Flu
Kategorik verilerin genelleştirilmesi
# Veri kümesini gör
hr.head()
Age BusinessTravel Department EducationField EmployeeNumber
0 41 Travel_Rarely Sales Life Sciences 1
1 49 Travel_Frequently Research & Development Life Sciences 2
2 37 Travel_Rarely Research & Development Other 4
3 33 Travel_Frequently Research & Development Life Sciences 5
4 27 Travel_Rarely Research & Development Medical 7
Kategorik veriler
Sınırlı ya da sabit sayıda olası değer.
- ırk
- cinsiyet
- memleket
- yaş grubu
- eğitim düzeyi
- sevdikleri filmler ve tercihler
Kategorik verilerin anonimleştirilmesi
Kategorik verilerin anonimleştirilmesi
Department EducationField
0 Sales Life Sciences
1 Research & Development Life Sciences
2 Research & Development Other
3 Research & Development Life Sciences
4 Research & Development Medical
Orijinal veri kümesi
Department EducationField
0 Sales Medical
1 Research & Development Marketing
2 Research & Development Life Sciences
3 Research & Development Other
4 Research & Development Life Sciences
Orijinal veri kümesindeki educationField sütununun olasılık dağılımından örnekleme sonrası oluşan veri kümesi.
Veriden örnekleme
ABD Nüfus Sayımı, vatandaşlar hakkında topladıkları verilerin örneklerini kamuya açıklar.
Büyük ölçekli istatistiksel örüntülerin hesaplanmasını sağlar:
- ortalamalar
- varyanslar
- kümeler
Dağılımı keşfetme
# Her benzersiz değerin mutlak frekanslarını göster
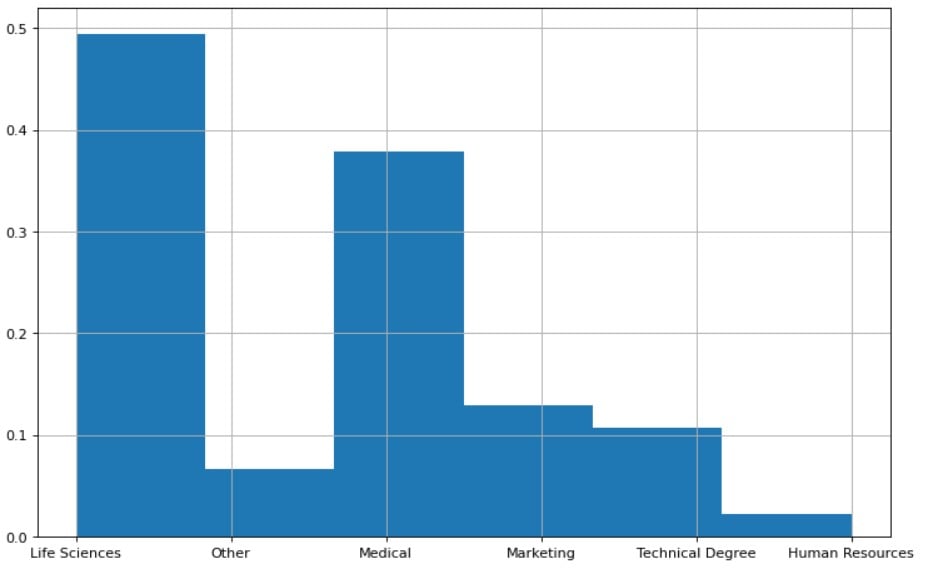
hr['EducationField'].value_counts()
Life Sciences 606
Medical 464
Marketing 159
Technical Degree 132
Other 82
Human Resources 27
Name: EducationField, dtype: int64
Dağılımı keşfetme
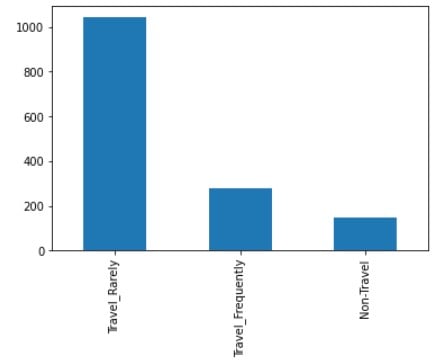
# Kategoriler için çubuk grafik oluştur
df['BusinessTravel'].value_counts().plot(kind='bar')
Dağılımı keşfetme
# Her benzersiz değerin mutlak frekanslarını al
counts = hr['EducationField'].value_counts()
# Dizin listesini yazdır
print(counts.index)
Index(['Life Sciences', 'Medical', 'Marketing',
'Technical Degree', 'Other', 'Human Resources'],
dtype='object')
Dağılımı keşfetme
# Her benzersiz değerin olasılık dağılımları
counts = df['EducationField'].value_counts(normalize=True)
Life Sciences 0.412245
Medical 0.315646
Marketing 0.108163
Technical Degree 0.089796
Other 0.055782
Human Resources 0.018367
Name: EducationField, dtype: float64
Dağılımı keşfetme
# Her benzersiz değerin frekans değerleri
df['EducationField'].value_counts(normalize=True).values
array([0.4122449 , 0.31564626, 0.10816327, 0.08979592, 0.05578231,
0.01836735])
Aynı dağılımdan örnekleme
# Bir olasılık dağılımından örnekleme hr_sample['EducationField']= np.random.choice(counts.index, p=counts.values, size=len(hr))# Ortaya çıkan veri kümesini gör hr.head()
Age BusinessTravel Department EducationField EmployeeNumber
0 41 Travel_Rarely Sales Life Sciences 1
1 49 Travel_Frequently Research & Development Medical 2
2 37 Travel_Rarely Research & Development Marketing 4
3 33 Travel_Frequently Research & Development Technical Degree 5
4 27 Travel_Rarely Research & Development Medical 7
Aynı dağılımdan örnekleme
# Her kategorinin mutlak frekanslarını göster
hr['EducationField'].value_counts()
Life Sciences 606
Medical 464
Marketing 159
Technical Degree 132
Other 82
Human Resources 27
Name: EducationField, dtype: int64
# Ortaya çıkan sütunun frekanslarını göster
hr_sample['EducationField'].value_counts()
Life Sciences 604
Medical 493
Marketing 158
Technical Degree 120
Other 61
Human Resources 34
Name: EducationField, dtype: int64
Ayo berlatih!
Python ile Veri Gizliliği ve Anonimleştirme

