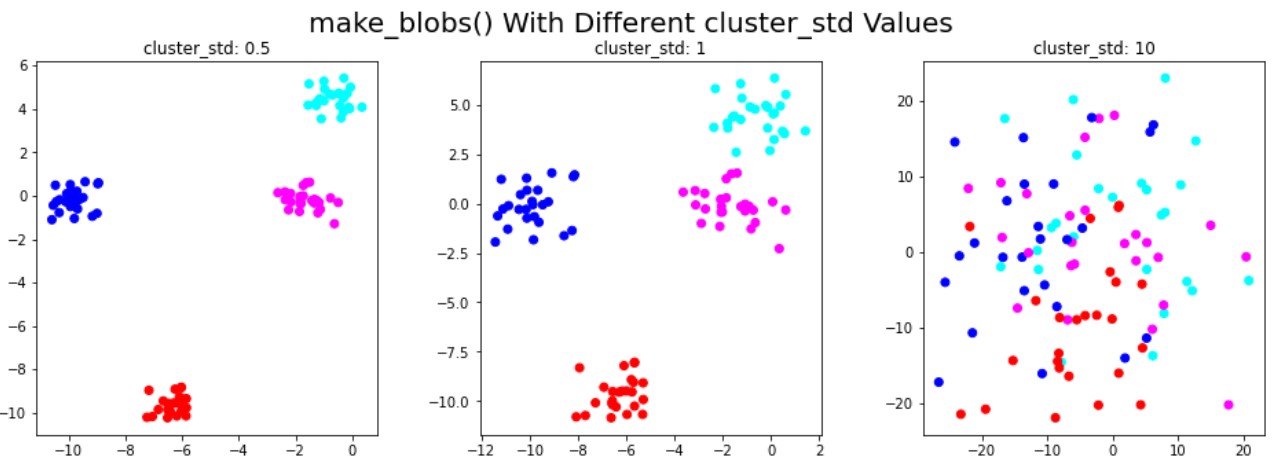
Scikit-learn ile sentetik veri kümeleri oluşturma
Python ile Veri Gizliliği ve Anonimleştirme

Rebeca Gonzalez
Data engineer
Scikit-learn ile veri kümeleri üretme
Olasılık dağılımlarından örnekleyen veri kümeleri oluşturabiliriz
Örneğin normal dağılım
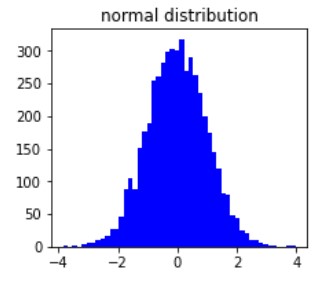
Normal dağılım
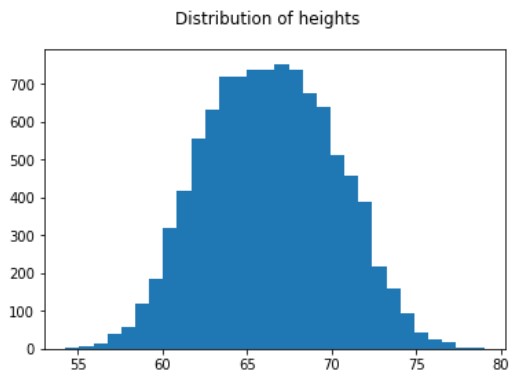
Normal dağılımdan örnekleme
# Oluşan boy dağılımını görmek için histogram çizin
new_measures['Height'].hist(bins=50)
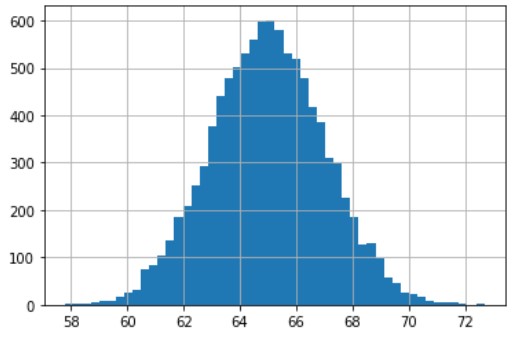
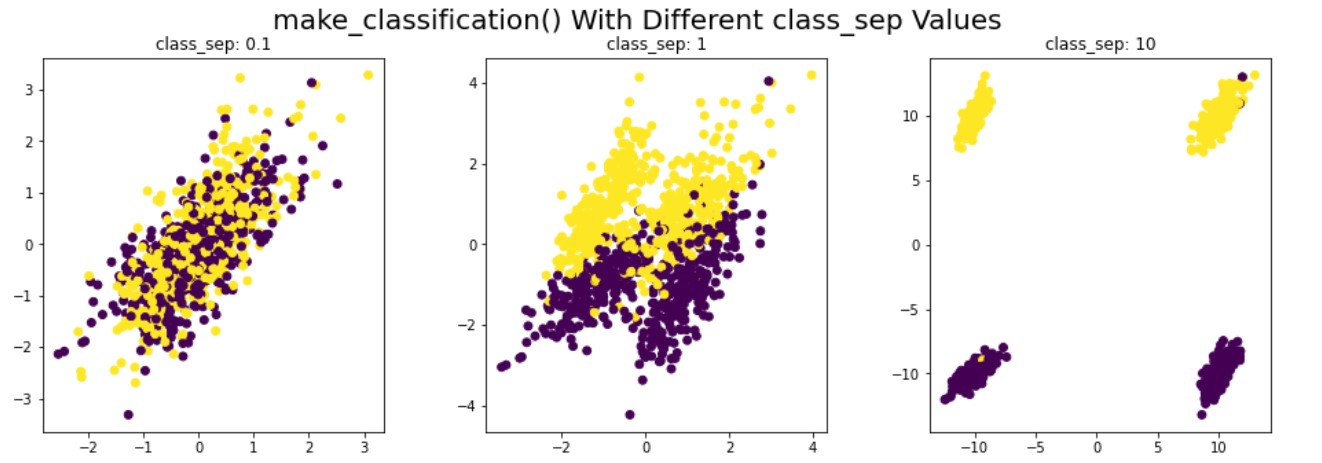
Sınıflandırma için sentetik veri
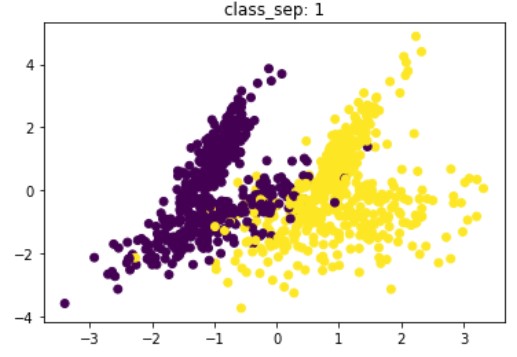
Sınıflandırma için sentetik veri
Kümeleme için sentetik veri
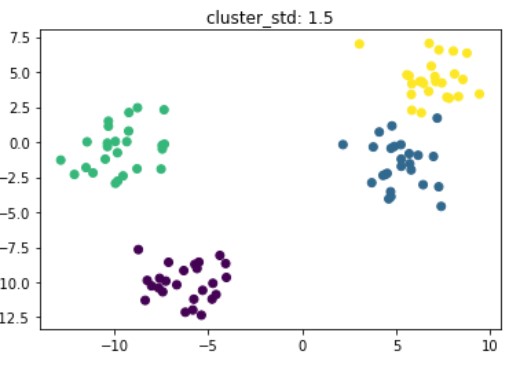
Kümeleme için sentetik veri